Na etapie analiz odpowiadam na pytania: “Jakie informacje i jak są przetwarzane w firmie”. Na etapie projektowania rozwiązania odpowiadam na pytanie “Jak powinien to robić przyszły system”.
Wprowadzenie

Adresatem tego wpisu są moi główni klienci (biznes, inwestorzy, itp.), bywa że jest nim software-house. Polecam ten wpis także dostawcom oprogramowania, których angażują moi klienci: jeżeli chcesz dostawać zapytania od moich klientów zapisz się jako dostawca na Newsletter).
Moją rolę w tej pętli opisują etapy od 1 do 3 pokazane poniżej:
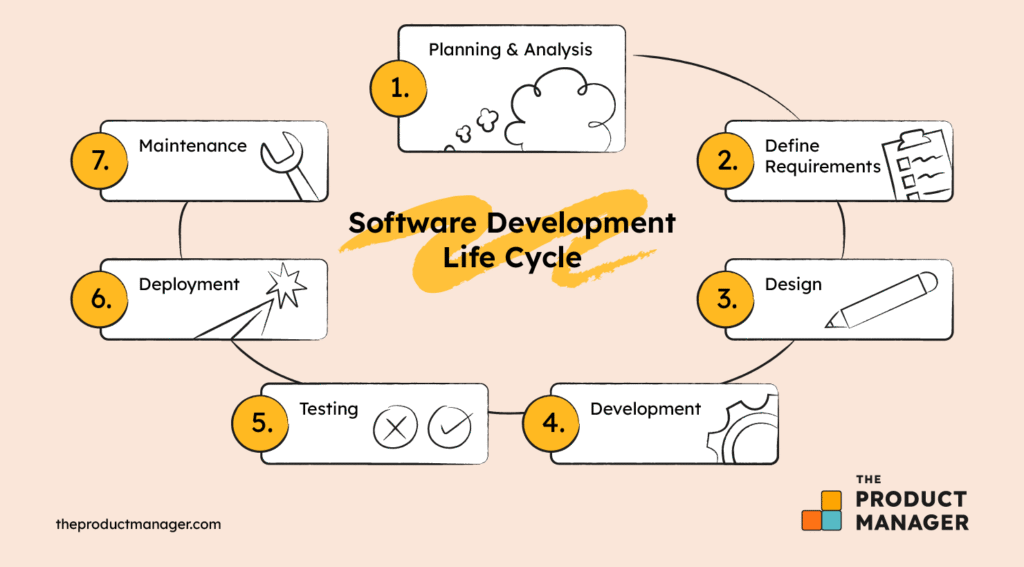
Co robi Architekt IT?
Ustala architekturę i mechanizm działania aplikacji (ale nie jej środowiska) przed kodowaniem. Kodowanie to etap rozpoczynany po tym, jak wykażemy że mechanizm ten jest poprawny.
“In software development, a model is a representation of a system or process, while code is the actual instructions that make the system run. Models help clarify needs, define architecture, and analyse code, while code implements the final product. “
Architekt IT ma za zadanie przygotować projekt zawierający wszelkie informacje, w tym także graficzną prezentację połączeń pomiędzy ważnymi modułami, aby programiści, graficy i inne osoby mogły stworzyć funkcjonalny produkt. Architekt opracowuje dokumentację: procesów biznesowych, wymagań, komponentów realizujących logikę biznesową (środowisko programistyczne i systemowe dobiera deweloper):
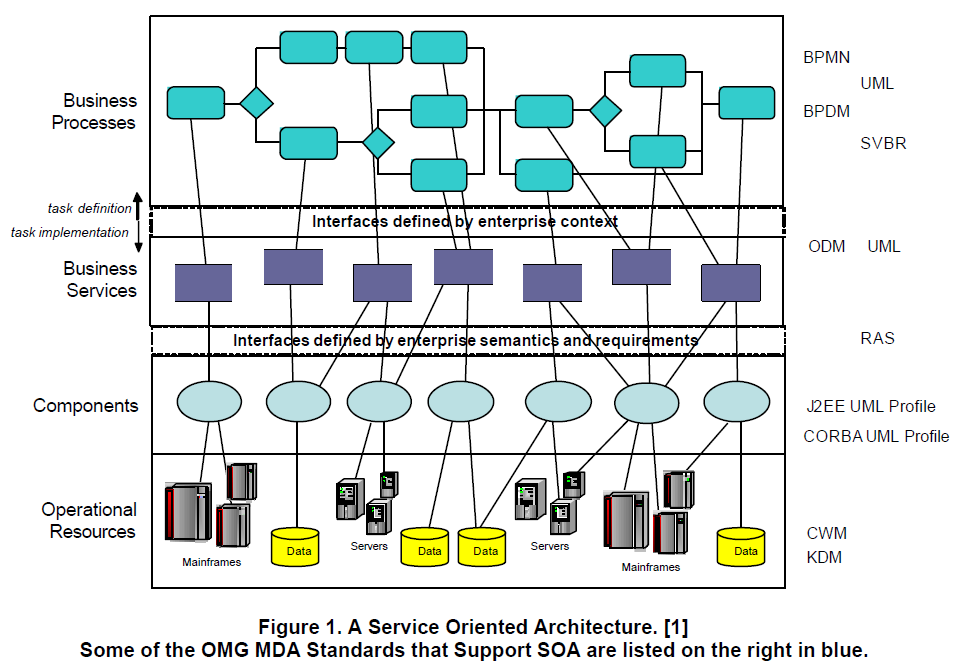
Architekt oprogramowania to osoba zazwyczaj pracująca w firmach deweloperskich, ale – tak jak ja – bywa także osobą, która pośredniczy pomiędzy klientami biznesowymi a firmą IT (SH-Software House, Deweloper, dostawca standardowego oprogramowania) zajmującą się implementacją danego projektu.
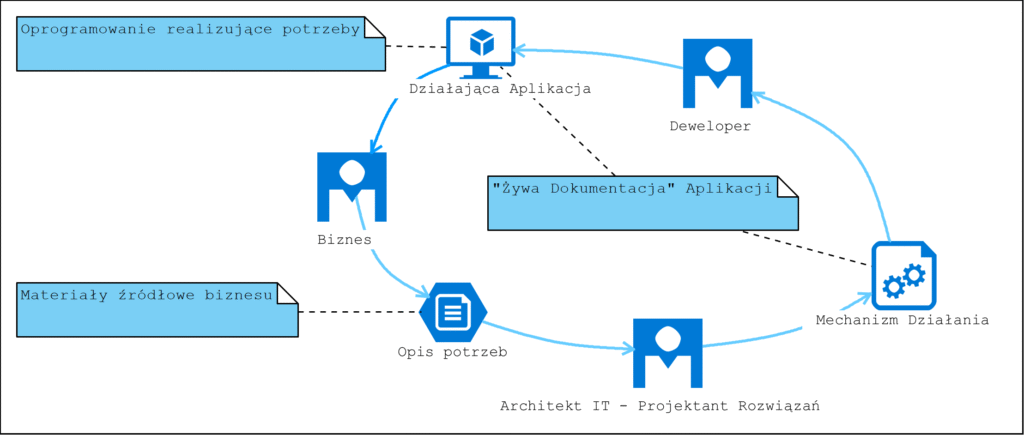
Kluczową odpowiedzialnością i kompetencją Architekta IT jest tworzenie dokumentacji, wykresów i diagramów obrazujących logikę działania systemów informatycznych. W tym ważna jest znajomość języka UML. (na podstawie https://nofluffjobs.com/pl/etc/specjalizacja/architekt-it-zarobki-wymagania-umiejetnosci/).
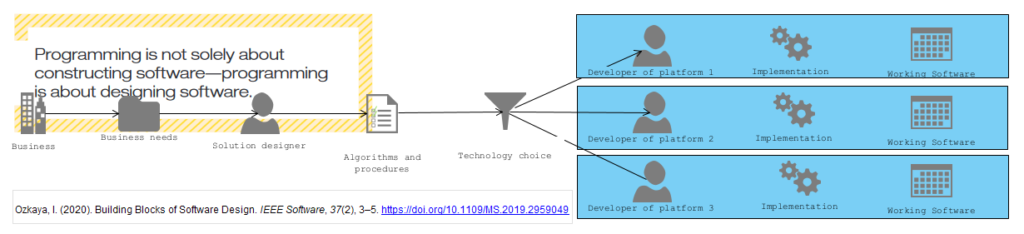
Przebieg projektu
Kadry kierownicze Sponsora projektu (przyszły użytkownik) dostarczają mi materiały w postaci potrzeb biznesowych (wymagania biznesowe), na podstawie których powstaje projekt aplikacji (model realizacji wymagań funkcjonalnych), którą realizuje (implementuje) SH/deweloper.
Bardzo często analiza wymagań poprzedzana jest powstaniem analitycznego modelu workflow/docflow (procesy biznesowe) i dopiero na jego podstawie powstają wymagania biznesowe.
Projekty w których biorę udział są często prowadzone zgodnie z tak zwanym V-Model:
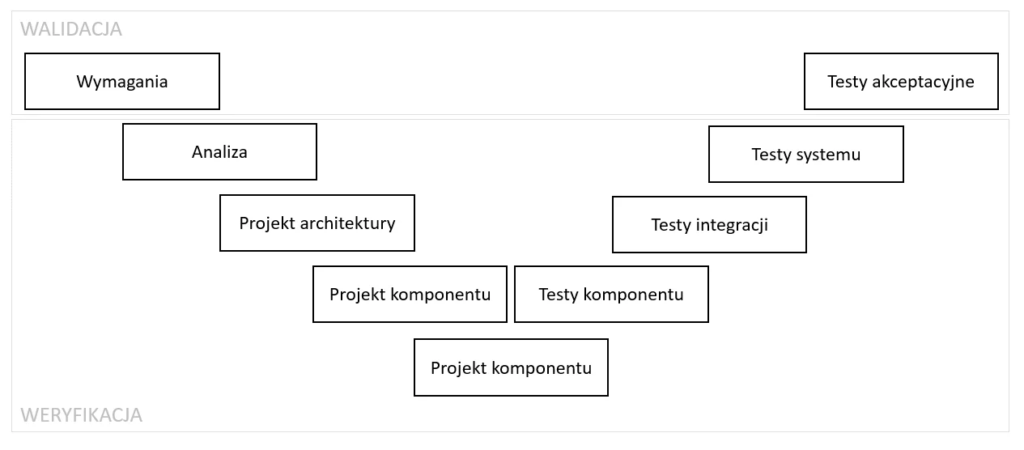
Moja rolą jest opracowanie lewej gałęzi powyższego modelu: do są wymagania oraz projekt: Requirement Analysis, System Design, Architecture Design (HLD), Modul Design (LLD), czyli na dzisiaj profesjonalne analizy i projektowanie z użyciem notacji UML.
Deweloper (prawa gałąź) dostarcza i konfiguruje środowisko oraz koduje (realizuje implementacje projektu). Większe aplikacje mają już na poziomie High Level Design komponentową architekturę i są dostarczane iteracyjnie-przyrostowo. Moimi klientami także bywają softwarehousy (przykładowe referencje). Od wielu lat część sponsorów wydziela fazę analizy wymagań i projektowanie (lewa strona V-Model).
Czym jest Model Logiki Aplikacji
Jest także nazywany Opisem Technicznym Oprogramowania albo Mechanizmem Działania. Opis Techniczny Oprogramowania (nie mylić z opisem powykonawczym wdrożenia) to dokumentacja, pozwalająca osobie mającej odpowiednią wiedzę, samodzielnie zrozumieć jego działanie i wytworzyć go.
Poniżej tak zwany “opis minimalny i wystarczający opis produktu” (czyli także aplikacji). Wynalazek to produkt zgłaszany do patentowania, poza Urzędem Patentowym “opis wynalazku” to “opis przedmiotu zamówienia” kierowany do jego wykonawcy (przedmiot umowy na wykonanie):
Opis wynalazku powinien przedstawiać (ujawniać) wynalazek na tyle jasno i wyczerpująco, aby znawca Jest mógł ten wynalazek urzeczywistnić, a ekspert mógł dokonać rzeczowej analizy porównawczej z dotychczasowym stanem techniki. Za „znawcę z danej dziedziny” uważa się przeciętnego praktyka dysponującego przeciętną, ogólnie dostępną wiedzą z danej dziedziny w odpowiednim czasie, który dysponuje typowymi środkami i możliwościami prowadzenia prac i doświadczeń. Przyjmuje się, że specjalista taki ma dostęp do stanu techniki; tzn. informacji zawartych w podręcznikach, monografiach, książkach. Zna także informacje zawarte w opisach patentowych i publikacjach naukowych, jeżeli wynalazek dotyczy rozwiązań, które są na tyle nowe, że nie są zawarte w książkach. Ponadto, potrafi korzystać ze stanu techniki w działalności zawodowej do rozwiązywania problemów technicznych. Przedstawiony wynalazek powinien więc nadawać się do odtworzenia bez dodatkowej twórczości wynalazczej. Pod pojęciem tym należy rozumieć dodatkową działalność umysłową, eksperymentalną związaną z niepełną informacją techniczną zawartą w opisie wynalazku, a także konieczność dodatkowych uzupełniających badań naukowych, niezbędnych do realizacji rozwiązania według wynalazku w pełnym zakresie żądanej ochrony. Odtworzenie wynalazku powinno być możliwe na podstawie przeciętnej wiedzy specjalisty w danej dziedzinie, bez nadmiernego wysiłku. (art. 33 ust. 1 § 32 ust. 2 pkt. 63)
Projekt to Opis techniczny, i jako opis mechanizmu działania aplikacji zawiera:
- modele struktur dokumentów i komunikatów,
- metody wyliczania lub weryfikowania wartości wszystkich pół wyliczanych w tych dokumentach,
- model architektury kodu dziedzinowego (komponenty, moduły, integracje, itp.),
- oraz opisuje mechanizmy współdziałania komponentów wyjaśniające integrację, wprowadzanie danych i powstawanie nowych treści.
Rolą dewelopera jest dobór i uruchomienie środowiska oraz implementacja ww. mechanizmu w wybranym języku programowania. Więcej w opisie Projektowanie aplikacji.
Warto tu podkreślić, że sama “idea systemu” wyrażona jako opis jego zewnętrznych cech i sposobów użycia (wymagania funkcjonalne i poza-funkcjonalne, user story), nie stanowi opisu technicznego i nie podlega żadnej ochronie. Z zasady nie stanowią opisu mechanizmu działania, know-how ani nie stanowią tajemnicy przedsiębiorstwa (polecam tu cały wpis: Ochrona Wartości Intelektualnych).
Bez względu na dziedzinę inżynierii , powyższe wymogi są identyczne. Komputer (oprogramowanie) jest zawsze częścią nadrzędnej konstrukcji (systemu, raz jest to macierzyste urządzenie a raz organizacja). Powoduje to, że oprogramowanie komputera, który wraz z tym oprogramowaniem z zasady realizuje jakiś mechanizm , musi zostać udokumentowane na równi z innymi elementami systemu, którego jest częścią.
Dokumentowanie istniejącego oprogramowania
Jeżeli celem jest opracowanie dokumentacji oprogramowania, które powstało ale nie ma ono profesjonalnej dokumentacji technicznej:
- dostaje aktualne dokumenty (jakiekolwiek jakimi dysponuje zleceniodawca) i na bazie ich audytu powstaje dokumentacja techniczna w takiej postaci w jakiej jest możliwa do stworzenia na bazie dostarczonego materiału źródłowego, na tym etapie jako efekt, powstaje także opis tego jakie dalsze prace są konieczne by projekt Techniczny uzyskał docelową postać (koszt: stawka za analizą dokumentacji),
- kontynuacja jako realizacja prac określonych w poprzednim punkcie (harmonogram i z góry ustalona kwota, rozliczenia miesięczne ryczałtem),
- przekazanie praw majątkowych do opracowanej dokumentacji ma miejsce zawsze, zależnie od ustalenia: po pierwszym lub po drugim etapie.
Typowy podział na role w projekcie
1. Zamawiający: jako Organizacja Analizowana zgłasza cele biznesowe i problemy, udostępnia wiedzę na swój temat, jest stałym recenzentem produktów analizy i projektowania (zamawiający to ekspert dziedzinowy) w toku projektu. To kadry kierownicze Zamawiającego, wspierane przez Asystenta–koordynatora, dostarczają materiały źródłowe opisujące opis ich działania i potrzeby.
2. Asystent-koordynator: osoba zaangażowana bezpośrednio z zbieranie materiałów źródłowych (wywiady, kolekcjonowanie dokumentów, itp.), z reguły jest to osoba angażowana (zatrudniana, wyznaczana) przez Zamawiającego. Bywa, że jest to zewnętrzny audytor.
3. Architekt IT: jako architekt-projektant (inżynier systemów, obszar Information Systems), prowadzi analizę otrzymanych materiałów, opracowuje model biznesowy organizacji (procesy biznesowe, przepływ i logika przetwarzania informacji), a potem opracowuje model dziedzinowy rozwiązania jako architekturę i logikę działania systemu (patrz jak powstaje Opis Techniczny Oprogramowania), jest ona wymaganiem dla dostawcy.
4. Deweloper (Programmer, obszar Information Technology): jako wykonawca implementacji rozwiązania, wybiera technologię, narzędzia i środowisko aplikacji, projektuje i wykonuje implementację, dostarcza i wdraża oprogramowanie.
(źr.: https://builtin.com/recruiting/software-engineer-vs-programmer)
Struktura i treść moich opracowań
Więcej na temat samego procesu powstawania tych produktów w: Analiza Potrzeb i Opracowanie Wymagań na Oprogramowanie, więcej o stosowanych metodach i standardach: Metoda analizy i projektowania systemów biznesowych. Słownik stosowanych metod i narzędzi jest dostępny na stronie: Słownik metodyczny.

Dodatek techniczny
(dla zainteresowanych)
Dlaczego moje projekty są zorientowane na dokumenty/komunikaty
Ważna uwaga! Dotyczy zarówno aplikacji tworzonych od zera jak i aplikacji już istniejących i rozwijanych. Ten opis dotyczy obu rodzajów aplikacji. Dokumenty w modelu logicznym mogą być utrwalane w bazie i modelu relacyjnym z pomocą dodatkowej warstwy ORM (mapowanie obiektowo-relacyjne), ma to jednak opisane niżej konsekwencje. Najczęściej stosowane przeze mnie wzorce projektowe to Repozytorium/Envelope, Active Record lub Active Table oraz DDD/Aggregate . Co do zasady na etapie analizy i projektowania nie tworzę i nie używam modeli danych rozumianych jako “jedna relacyjna baza danych dla projektu”.
Innymi słowy logika dziedzinowa to dokumenty jako komunikaty, a te mogą być i przesyłane i utrwalane. Jak widać po prawej, metody utrwalania są poza zakresem modelu dziedziny, czyli poza modelem opisującym mechanizm działania aplikacji.
Krótkie wyjaśnienie
Pojęcie “zbiór danych” większości nadal kojarzy się z relacyjnym modelem danych. Jednak my jako ludzie gromadzimy informacje w postaci redundantnych dokumentów, ich struktury odpowiadają naszym potrzebom a dokumenty są z zasady niezależnymi od siebie bytami (to nie raz zawierają powiązane logicznie treści niczego tu nie zmienia). Dokument to przede wszystkim kontekst dla danych na nim zgromadzonych. Dlatego tak zwane Systemy Biznesowe często nazywane są systemami formularzowymi: z zasady operują na dokumentach (formularzach), integracja systemów – wewnątrz organizacji jak i między organizacjami – to wymiana nazwanych zestawów danych: dokumentów .
Relacyjny model danych jest nieelastyczny. Cechuje się precyzyjnie zdefiniowaną strukturą danych, która jednak bardzo ją ogranicza. Musimy zdefiniować stałą strukturę jak kolumny i wiersze tabel oraz określić ich relacje, co jest później trudne do zmiany. Ponadto, jeśli dziedzina pojęciowa jest głęboko zagnieżdżona, użycie modelu relacyjnego dla niej będzie wymagało wielu tabel i złączeń. Relacyjne bazy danych mają słabą skalowalność poziomą. Mogą być skalowane w pionie poprzez dodanie większej ilości zasobów, takich jak procesor i pamięć RAM. Ale nie mogą być skalowane poziomo, tzn. łączyć wielu maszyn i tworzyć klastrów. Wynika to z wymagań dotyczących spójności. Baza danych zorientowana na dokumenty rozwiązuje niektóre z tych problemów, z którymi boryka się baza danych w modelu relacyjnym.
Główną wadą relacyjnego modelu danych w systemach biznesowych jest zapisywanie danych w postaci współdzielonych znormalizowanych struktur pojęciowych, pozbawionych redundancji, co powoduje, że dane są pozbawione kontekstu , a w konsekwencji model ten nie sprawdza się w systemach zarządzających dokumentami i ich treścią. Dokumenty biznesowe (dowody księgowe ale także umowy, oferty i wiele innych) to złożone agregaty danych więc zapytania SQL do tabel relacyjnych (do ich zapisu i odczytu) to bardzo złożone struktury kodu, powodujące, że tak zorganizowane bazy szybko stają się niewydajne (zasoby takie jak procesor i RAM są ograniczone a skalowanie poziomie tu jest niemożliwe). Dodatkowo dokument, w sensie fizycznym nie może być generowaną dynamicznie strukturą (zapytania SQL do bazy relacyjnej), bo jest wtedy tylko wirtualnym chwilowym bytem, nie stanowi także dokumentu w sensie prawnym (Kodeks Cywilny), nie da się też zarządzać jego cyklem życia.
W dzisiejszej erze big data można zaobserwować ogromną ewolucję w typach baz danych i ich wykorzystaniu. Rozwiązania takie jak np. MySQL czy Oracle, nie są w stanie sprostać współczesnym wymaganiom związanym z obsługą dużej różnorodności, szybkości, prawdziwości i, co ważne, obszernych zbiorów danych. Bazy danych NoSQL są szybkimi rozwiązaniami i doskonale radzą sobie z tymi wymaganiami dzięki dodatkowym cechom, takim jak skalowanie poziome, wysoka wydajność, zgodność z elastycznością i wszechstronność.
Dokument jako agregat danych
Dokumenty w systemach informatycznych są coraz częściej wyrażane jako struktury XML/XSD/DTD (lub JSON) w bazach dokumentowych (NpSQL) i przechowywane w postaci agregatów .
Dane grupowane w dokumenty i przetwarzane jako całe struktury informacyjne, a nie jako pojedyncze pola danych, są coraz częściej stosowaną metodą budowania architektury oprogramowania . Podejście takie daje znacznie większą swobodę projektowania, zaś struktury takie jaki XML czy JSON, można przetwarzać i przesyłać między aplikacjami ze znacznie większą swobodą .
W moich projektach dane są modelowane jako hierarchiczne agregaty (patrz wzorce obiektowe) przechowywane w niezależnych płaskich (nie powiązanych relacyjnie) tabelach: kolumny takiej tabeli reprezentują metadane, cały dokument jako XML/JSON jest zawartością jednego z pól. Każdy dokument ma określoną strukturę oraz zdefiniowane reguły określające jego poprawność (słownik i reguły biznesowe , . Struktura ta może być przejrzyście wyrażona w postaci diagramu UML.
Mechanizm utrwalania standardowo modeluję z użyciem wzorca repozytorium. Obiekt ‘entity’ (wiersz ww. tabeli z dokumentami) odpowiedzialny jest za przechowanie dokumentu (patrz wzorzec ‘envelope’ ): ma atrybuty zawierające kluczowe metadane do realizowania logiki biznesowej oraz operacje CRUD dla tego dokumentu . Od pozostałej części aplikacji oddziela go komponent realizujący logikę dostępu do danych.
Logika dziedzinowa (także walidacja dokumentów) może być wspólna dla wielu dokumentów w określonym dziedzinowym kontekście . Dokument jest tu agregatem.
Jednym z kluczowych powodów powszechnego stosowania XML jest także standaryzacja dokumentów, głównie finansowych i urzędowych w ramach Unii Europejskiej oraz standaryzacja, także w Unii, metod zarządzania nimi (archiwa) .
Z racji tego, że pojęcie dokumentu ma także charakter prawny, wydaje się oczywistym, że zachowanie interoperacyjności wymaga takiej standaryzacji. Jest to – standaryzacja – proces postępujący w ramach Unii Europejskiej i wewnątrz państw wspólnoty, dlatego z zasady w moich projektach wymaganiem jest stosowanie XML jako metody zapisu informacji. To czy fizycznie będzie to motor bazy NoSQL czy płaskie tablice w motorach SQL nie ma większego znaczenia, bo istotny jest tu nierelacyjny model danych .
Jako analityk biznesowy i jednoczenie architekt rozwiązania, jestem projektantem. Na podstawie otrzymanych materiałów projektuję rozwiązanie i odsyłam jego opis (opisane schematy blokowe prezentujące procesy biznesowe, architekturę integracji, struktury dokumentów i logikę ich poprawności, itp. (co do zasady stosuję standardy: notacje BPMN, UML, SBVR, itp.). Jak i dlaczego dlaczego? Polecam poniższy referat, który mam nadzieję wiele wyjaśni:
Przykłady specyfikacji wymagań

Prezentowanie przykładowych specyfikacji jest możliwe wyłącznie wtedy, gdy nie są one objęte tajemnicą przedsiębiorstwa, mogę więc pokazać tylko wybrane opracowania. Sa to wyłącznie opublikowane wcześniej dokumenty w przetargach publicznych lub opisy “demo” (tu jako artykuł: Projekt aplikacji ? przykład). Poniższe opracowania to dokumentacja dedykowanych systemów, jednak nie każdy system musi być dedykowany.
Projekty dla administracji były realizowane z moim wsparciem (nadzór autorski), zostały wykonane w terminie i w budżecie, zamawiający dostał autorskie prawa majątkowe do projektu, aplikacje te nadal są w użyciu i są rozwijane przez ich właścicieli.
Większość projektów nastawiona jest na zakup i wdrożenie oprogramowania gotowego, dlatego przygotowanie np. do wdrożenia systemu ERP to zawsze Analiza Biznesowa oraz “architektura wysokiego poziomu” (HLD) integracji systemu. Jedynie tam, gdzie wymagane są dedykowane funkcjonalności tworzona jest architektura LLD (ww. specyfikacja techniczna).
Generator_Ofert_zalacznik_nr_1_do_siwz.pdf
1.92 MBKomentarze do projektu Generator Ofert na stronie: Generator Ofert ? Komentarze
ZW_RZP_32_PN_S_2019_zal_1a_-_Dokumentacja_Projektowa_Oprogramowania_do_OPZa.pdf
2.88 MBAnaliza-systemu-promocji-PKP-IC.pdf
2.27 MBPrzykład procesu prowadzenia analizy i wykonania opisu dokumentacji, wraz z filmem jak powstawał, znajdziesz na stronie: https://it-consulting.pl/2020/12/11/analiza-biznesowa-od-zlecenia-do-kompletnego-projektu-technicznego-z-uzyciem-narzedzia-case/.
W razie jakichkolwiek pytań lub sugestii co do tego, czego wg. Was developerów brakuje w tych przykładach zapraszam do komentarzy pod tym tekstem lub proszę o kontakt.
Jesteś deweloperem? Zarejestruj się jako developer na newsletter.
