Bardzo często zastanawiam się, nad przyczynami porażek projektów, przyczynami tego, że jedne są lepsze inne gorsze, a gorszy to taki, który wymyka się spod kontroli a ostateczny efekt (produkt), uzyskany po znacznie dłuższym czasie niż planowano, jest zaskoczeniem dla wszystkich. Na to nakłada się problem przekazywania wiedzy pomiędzy kolejnymi etapami projektu, gdzie największym ryzykiem jest zrozumienie problemu i przekazywanie wiedzy przez samego zamawiającego. Gdzie problem?
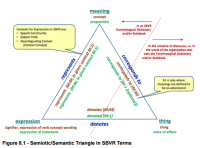
Ten artykuł polecam “biznesowi” który szuka przyczyn swoich problemów, i tym (nie tylko analitykom), którzy mają ambicje robić coś w kierunku poprawy tego stanu rzeczy, zamiast uznawać obecne statystyki za pewnik bo “takie są fakty”. […] Ktoś może powiedzieć: biznes tego (notacje, modele itp.) nie rozumie. I ma racje, bo to narzędzia a nie produkty analiz. Produktem analizy dla biznesu są zawsze rekomendacje (wymagania na oprogramowanie to także rodzaj rekomendacji brzmiącej: zalecam by takie warunki spełniało to oprogramowanie). Zamawianie przez biznes modeli jako takich, to jakieś koszmarne nieporozumienie. To tak jak by np. prawnik, jako produkt zlecenia “opinia prawna” oddał wybrany stos kodeksów z komentarzami. Nie, dobry prawnik oddaje jedna stronę rekomendacji: opinie prawną. To, że skorzystał z tych kodeksów to jego narzędzie pracy, możliwe, że załączy je do tej tej opinii (ale raczej jako materiał dla innego prawnika lub audytora).