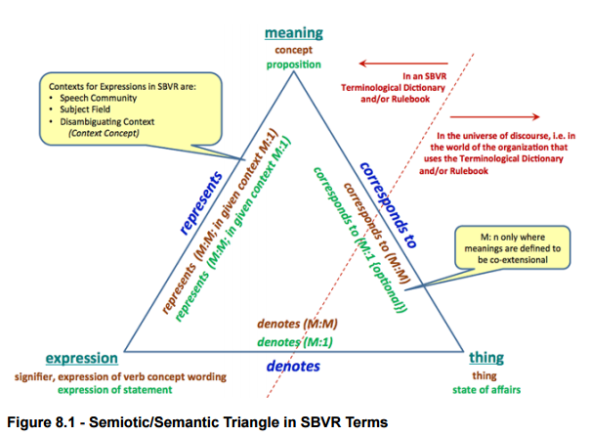
Semiotic/Semantic Triangle in SBVR Terms
Ronald G. Ross Ronald G. Ross jest autorem lub współautorem wielu opracowań na temat modeli pojęciowych i zarządzania wiedzą . Jest także współzałożycielem Business Rule Solution LLC, oraz współtwórcą specyfikacji i notacji SBVR . Książka Najnowsze z powyższych opracowań to rodzaj podsumowania pewnej części dorobku autora. Modele pojęciowe są często mylone z projektowaniem relacyjnego modelu danych, a bywa gorzej, gdy są utożsamiane z "modelem dziedziny systemu" w projektach dotyczących tworzenia aplikacji określanych jako"obiektowe". Książka traktuje o modelach pojęciowych, i autor definiuje je jako: model pojęciowy: uporządkowany zbiór pojęć i związków…

Technologia IT pozwala zapisywać ogromne ilości danych. W cytowanym na początku artykule namawia się nas na inwestycje w technologie, które dają szanse na "przerobienie" tego. A czy aby na pewno musimy gromadzić to wszystko? Mózg ludzki ma doskonała obronę przed nadmiarem informacji, jak wiemy radzimy sobie całkiem nieźle mimo tego, że wiele rzeczy zapominamy. To miliony lat ewolucji stworzyły ten mechanizm! Wystarczy go naśladować.Zmierzam do tego, że projektowanie systemów informatycznych to także projektowanie tego jakimi danymi zarządzać i które zachowywać np. w hurtowni danych. Gdyby nasza firma zawierała nieskończoną ilość transakcji sprzedaży rocznie (:)) czy musimy analizować wszystkie by ocenić udziały w rynku, podział na regiony, najlepszych i najgorszych sprzedawców, nadużycia w transporcie? Nie! wystarczy mieć dane reprezentatywne, rejestrować do analiz tylko ustalona część ([retencja danych]]). Niestety nie jest łatwo podjąć decyzje, która to część i to jest (powinno być) tak na prawdę część analizy wymagań. A koszt takiej analizy nijak się nie ma, jest znacznie mniej kosztowna, niż systemy do przetwarzania wszystkich tych danych. Nie dajmy się zwariować z wydatkami na rosnące pojemności systemów składowania i przetwarzania danych.

Moim zdaniem hurtownie danych i wszelkiego typu systemy BI mogą być skuteczne jako wykrywanie "czegoś" w historii, na pewno sprawdzają się jako złożone systemy raportowania, ale nie sądzę by jakakolwiek hurtownia danych plus system BI odkryła cokolwiek nowego lub skutecznie prognozowała. [...] Budowanie modeli na bazie małych partii danych jest po pierwsze wiarygodniejsze (paradoksalnie) niż proste wnioskowanie statystyczne, po drugie daje szanse odkrycia czegoś nowego. W czym problem? To drugie jest nie możliwe z pomocą deterministycznej maszyny jaką jest komputer. To wymaga człowieka, ten jednak nie daje się produkować masowo... ;), korporacja na nim nie zarobi.Hm... czy przypadkiem promowanie systemów hurtowni danych, BI, pracy z terabajtami danych itp.. to nie tworzenie sobie rynku przez dostawców tych technologii?Warto więc za każdym razem, zanim zainwestujemy w rozwiązania operujące na terabajtach danych, przemyśleć co chcemy osiągnąć. W zasadzie nie ma uzasadnienia dla trzymania wszystkich danych, ważne jest określenie jaki problem chcemy rozwiązać. Jeżeli są to problemy związane z analizą danych historycznych, badania statystyczne mogą być skuteczne, do tego poddają się automatyzacji. Jeżeli jednak problem tkwi w planowaniu zmian, prognozowaniu, odkrywaniu, polecam raczej człowieka i budowanie hipotez.