W perspektywie krótkoterminowej architektura oprogramowania pomaga zredukować czas i koszty rozwoju.W dłuższej perspektywie architektura oprogramowania pomaga zredukować koszty utrzymaniu. https://medium.com/@learnwithwhiteboard_digest/basics-of-software-architecture-a-guide-for-developers-8098a76881ca Wstęp W 2017 roku pisałem dość ogólnie o logice wzorca architektonicznego MVC kończąc artykuł słowami: A gdzie mityczna baza danych? Tam gdzie jej miejsce: zarządza danymi utrwalanymi w pamięci. Baza danych i systemy zarządzania danymi w architekturze obiektowej nie stanowią miejsca na logikę biznesową, standardowym wzorcem projektowym jest tu active records. Podstawową zaletą stosowanie tego wzorca jest separacja utrwalonych danych od aplikacji. To pozwala skupić całą logikę i jej zmienność w kodzie aplikacji i jego architekturze. Dzięki temu…
Architektura Projekty informatyczne się rozrastają, cała branża ewoluuje. Ostatnie 20 lat doświadczeń pokazało, że owszem sztuką jest stworzyć i wdrożyć oprogramowanie, ale jeszcze większą sztuką jest je konserwować, zmieniać i rozwijać. Wiele firm boryka się z powtarzanymi długotrwałymi i kosztownymi "analizami przedwdrożeniowymi" poprzedzającymi każdy kolejny projekt wdrażania zmian. To skutek braku aktualnej dokumentacji posiadanego systemu. To jak planowanie nowej budowy w mieście nie mając aktualnych planów urbanistycznych tego miasta: każdy nowy projekt to ponowne dokumentowanie stanu obecnego, tylko dlatego, że ktoś nie udokumentował zmian wprowadzonych ostatnim razem (być może poprzednio…

Wprowadzenie
Niedawno napisał do mnie czytelnik pod jednym z artykułów:
Załóżmy, że realizujemy proces biznesowy: zarządzanie kursami walut. W ramach procesu pracownik musi przygotować plik csv zawierający wyłącznie listę słownikową par walut (np. usdpln, eurpln, eurusd). Nazwa pliku to np bieżącą data. Następnie systemX łączy się z API zewnętrznej platformy i pobiera tabele kursów tych par walut (aktualne i historyczne miesiąc wstecz) i wystawia plik xls zawierający dane: nazwa pary walut, data kursu, wartość kursy) Plik ten system X wysyła do szyby ESB. Szyna przesyła ten plik do systemuY. SystemY wykorzystuje te dane do wyznaczenia wewnętrznych kursów walut wg. ustalonego modelu matematycznego. Wynik obliczeń odkładany jest w bazie danych tego systemu. Na końcu procesu jest pracownik, który wykorzystuje te informacje za pośrednictwem SystemuZ. Wybiera parę walut, określa datę i system zwraca mu wewnętrzny kurs wyznaczony przez SystemY. Technicznie odbywa się poprzez odpytanie systemu Y poprzez jego API. Czyli mamy SystemX, SystemY, SystemZ, pracownika, szynę, plik csv, plix xls, 2XAPI no i przepływ danych (najpierw plików, potem poszczególnych atrybutów) . I jak to wszystkim pokazać żeby było czytelne? (źr.: : Model pojęciowy, model danych, model dziedziny systemu)
Prawdę mówiąc, mniej więcej w takiej formie dostaje materiały od moich klientów.. ;). Co możemy zrobić? Pomyślałem, że dobry reprezentatywny przykład pomoże. Popatrzmy…
(więcej…)
(źr. Martin Fowler, Analysis Patterns, 1997)
Wprowadzenie W 2019 opisałem swoistą próbę rewitalizacji wzorca BCE (Boundary, Control, Entity). Po wielu latach używania tego wzorca i dwóch latach prób jego rewitalizacji uznałem jednak, że Zarzucam prace nad wzorcem BCE. Podstawowy powód to bogata literatura i utrwalone znaczenia pojęć opisujących ten wzorzec. Co do zasady redefiniowanie utrwalonych pojęć nie wnosi niczego do nauki. Moja publikacja zawierająca także opis tego wzorca bazowała na pierwotnych znaczeniach pojęć Boundary, Control, Entity. Sprawiły one jednak nieco problemu w kolejnej publikacji na temat dokumentów . Dlatego w modelu pojęciowym opisującym role komponentów przyjąłem następujące bazowe stwierdzenie:…
Dwa lata temu pisałem o mikroserwisach: Obecnie mamy już dość dobrze wypracowane wzorce projektowe ale nadal jest problem ze zrozumieniem ?kiedy i jak?. Ładnie to opisał swego czasu E.Evans przy okazji wzorca DDD, Tu poprzestanę jedynie na pojęciu bounded context czyli ?granica kontekstu?. Granica ta ma podwójne znaczenie: kontekst nadaje (zmienia) znaczenia w modelu pojęciowym (bałwan w kontekście zimy to co innego niż bałwan w kontekście członków zespołu projektowego) oraz kontekst (bardzo często) wyznacza zakres projektu (inne aspekty wzorca DDD tu pominę). Pierwsza uwaga: kontekst dziedzinowy (pojęciowy) jest ważniejszy (powinien…
Obydwa te, spotykane często w prasie, skróty mają wiele wspólnego: oznaczają aplikacje zarządzające obiegiem informacji i jej magazynowaniem (ECM - Electronic Content Management czyli zarządzanie treścią w postaci elektronicznej oraz EOD - Elektroniczny Obieg Dokumentów). Cechą zawartą "nie wprost" w tych nazwach jest zarządzanie także składowaniem i przepływem tej informacji. Osiem lat temu pisałem o kwestiach pojęciowych (czym jest wiedza, jej przetwarzanie, czym są dane): Problematyka informacji w firmach, jej kolekcjonowania i przetwarzania jest częstym tematem artykułów w prasie specjalistycznej jak i opisem zakresów projektów IT. Termin ten jest jednak…
Kolejna książka, tym razem coś w rodzaju podręcznika, zbioru metod. Jest to praca zbiorowa. Polecam wszystkim osobom, których rolą jest między innymi dokumentowanie architektury systemów IT. Wiele przykładów opartych o UML, SysML oraz planowany do upowszechnienia AADL (Architecture Analysis and Design Language). Ten ostatni jest w sferze planów, zobaczymy… (więcej…)
Szperałem w sieci szukając informacji o architekturze i microservisach, a wpadłem na to: ... communication between two different software modules is proportional to the communication between the designers and developers of these modules. Conway?s law exposes the vulnerability in monoliths as they grow in size. Micro-services may not be the best, but better than monoliths for the contemporary web based applications. (Źródło: Micro-Services: A comparison with Monoliths | My Blog) To "prawo" wyjaśnia dlaczego powstają złe interfejsy a nawet zła architektura: z reguły dlatego, że to - architektura - jest lepszym lub…
W efekcie systemy nazywane nadal ERP to raczej już tylko jądro zarządzania (nadal bardzo ważne) integrowane z dziedzinowymi podsystemami (np. wymienionymi wyżej) innych producentów, aniżeli wielki zintegrowany, kosztowny i we wdrożeniu i w utrzymaniu moloch. ERP w reklamowanej jako "system do wszystkiego" ma raczej sens w małej firmie o nieskomplikowanej działalności, większe firmy wymagają jednak większej podatności ma zmiany czego ERP w "jednym kawałku" nigdy nie da, a duży jednorazowy koszt jest zbyt wielkim ryzykiem.
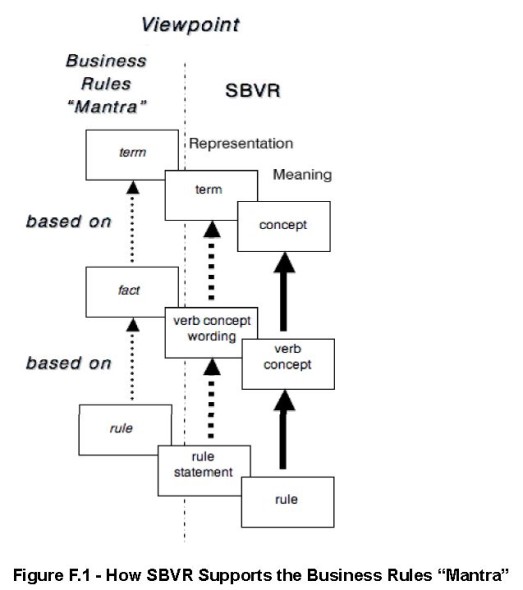
O analizie pojęciowej pisałem nie raz, chyba pierwszy raz w krótkim artykule Analityk biznesowy czyli wyplenić dwuznaczność z dokumentów analitycznych. Niestety nadal problemem większości dokumentów, takich jak analizy i specyfikacje, jest ich niespójność i niejednoznaczność. W niedawnym artykule SBVR czyli reguły biznesowe i słownik pisałem o diagramie faktów, o regułach i o słowniku pojęć, dzisiaj co nieco o pojęciach (tych ze słownika pojęć ;)). Ostatnia wersja specyfikacji SBVR v.1.3. z maja tego roku, zawiera rozszerzony rozdział: 8 Linguistic Foundations, 8.1 Things, Meanings, and Expressions, 8.1.1 Semiotic/Semantic Triangle in SBVR Terms rozpoczynający się tak: This sub…
Jednym z moich niedawnych nabytków jest bardzo wartościowa książka, jednak nie jest to podręcznik analizy i modelowania, a opis wieloletnich doświadczeń autorów w tworzeniu i dokumentowaniu architektury oprogramowania. The authors have structured this edition around the concept of architecture influence cycles. Each cycle shows how architecture influences, and is influenced by, a particular context in which architecture plays a critical role. Contexts include technical environment, the life cycle of a project, an organization?s business profile, and the architect?s professional practices. The authors also have greatly expanded their treatment of quality…
Niestety wiele systemów ERP i i nie tylko, powstało w latach 90'tych, mają one niestety scentralizowaną architekturę strukturalną (jedna baza danych i "nad nią" funkcje przetwarzające te dane). Efekty tego widać przy wdrożeniach, w których dopuszczono tak zwaną kastomizacje systemu, czyli właśnie wprowadzanie, nie raz bardzo wielu, zmian. To bardzo kosztowne projekty o praktycznie nieprzewidywalnym budżecie. Niestety współdzielenie danych wewnątrz takiego systemu jest jego poważną wadą a nie - jak to zachwalają ich dostawcy - zaletą...