Wprowadzenie
Niedawno napisał do mnie czytelnik pod jednym z artykułów:
Załóżmy, że realizujemy proces biznesowy: zarządzanie kursami walut. W ramach procesu pracownik musi przygotować plik csv zawierający wyłącznie listę słownikową par walut (np. usdpln, eurpln, eurusd). Nazwa pliku to np bieżącą data. Następnie systemX łączy się z API zewnętrznej platformy i pobiera tabele kursów tych par walut (aktualne i historyczne miesiąc wstecz) i wystawia plik xls zawierający dane: nazwa pary walut, data kursu, wartość kursy) Plik ten system X wysyła do szyby ESB. Szyna przesyła ten plik do systemuY. SystemY wykorzystuje te dane do wyznaczenia wewnętrznych kursów walut wg. ustalonego modelu matematycznego. Wynik obliczeń odkładany jest w bazie danych tego systemu. Na końcu procesu jest pracownik, który wykorzystuje te informacje za pośrednictwem SystemuZ. Wybiera parę walut, określa datę i system zwraca mu wewnętrzny kurs wyznaczony przez SystemY. Technicznie odbywa się poprzez odpytanie systemu Y poprzez jego API. Czyli mamy SystemX, SystemY, SystemZ, pracownika, szynę, plik csv, plix xls, 2XAPI no i przepływ danych (najpierw plików, potem poszczególnych atrybutów) . I jak to wszystkim pokazać żeby było czytelne? (źr.: : Model pojęciowy, model danych, model dziedziny systemu)
Prawdę mówiąc, mniej więcej w takiej formie dostaje materiały od moich klientów.. ;). Co możemy zrobić? Pomyślałem, że dobry reprezentatywny przykład pomoże. Popatrzmy…
(więcej…)
Skutek jest taki, że dostawca oprogramowania na podstawy prawne do ochrony kodu jaki dostarczył, jednak kupujący nie ma żadnych podstaw (dokumenty, projekt itp.) by chronić swoje know-how i by nie płacić za swoje własne know-how "włożone" w toku wdrożenia, do wdrażanego oprogramowania. Dlatego warto restrykcyjnie prowadzić proces analizy i projektowania, to jest umiejętnie udokumentować projekt tak, by granica pomiędzy wartościami intelektualnymi dostawcy i nabywcy oprogramowania była jasno określona. I nie jest to rola prawnika a architekta całości systemu, który musi także znać i rozumieć prawne aspekty tej architektury.
Bardzo często spotykam się z projektami inicjowanymi przez średnie kadry kierownicze dużych firm i urzędów, często mają one pewną wspólną cechę: "nie możemy nic zmieniać w strategii organizacji ale chcemy usprawnić pracę w naszym wydziale". To z reguły bardzo cenna inicjatywa ale także dobra droga do porażki projektu. W urzędach często na granicy łamania prawa... a nie raz z jego łamaniem. Projekty w administracji publicznej mają dodatkową specyfikę: zasady ustala prawodawca a nie menedżer organizacji. Bardzo dobrze opisał to zjawisko prof. Bolesław Szafrański wskazując przyczynę wielu porażek wdrożeń w administracji.…
Kolejna odsłona w rozwoju oprogramowania CASE firmy Visual Paradigm. Agile, pierwszych katach churra optymizmu, zaczyna troszkę się krystalizować co zauważył już [[Scott Ambler]] 12 lat temu: książka traktująca o tym, że zwinność nie oznacza bałaganu i pospolitego ruszenia. Scott Ambler to kolejny autorytet w inżynierii oprogramowania. I mimo, że nikogo nie ma sensu małpować, na pewno warto się uczyć? (Źródło: Agile Modeling. Effective Practices for Modeling and Documentation | | Jarosław Żeliński IT-Consulting) Visual-Paradigm to także zestaw narzędzi Agile pozwalających z jednej strony zwinnie zarządzać projektowaniem i projektem (to nie jest…
Narzędzie, którego używam od 2005 roku (rezygnując wtedy z MS Visio bo toporny i wyrzucając demo EA SPARX bo toporny i niezgodny z UML), staje się coraz lepsze. To co powoduje, że nadal nie planuję zmieniać narzędzia to mega ergonomia pracy, 100% zgodności ze specyfikacjami OMG, a przede wszystkim serwer pracy grupowej VPository, co razem daje mega platformę analityczno-komunikacyjną dla analityka i klienta.
W nowej wersji:
(więcej…)
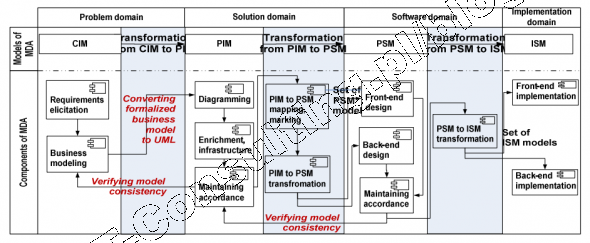
Nie powinniśmy zapominać, że model Kruchtena to połowa lat 90-tych, szczyt rozkwitu metod strukturalnych i raczkujące metody i narzędzia obiektowe. To stare systemy i ich relacyjne bazy danych wymusiły stosowanie [[mapowania ORM]] i takich narzędzi jak [[Hibernate]]. Dzisiaj mamy rok 2015, od tamtej pory minęło 20 lat. Nie musimy się cofać do początków inżynierii oprogramowania w wersji obiektowej. Coś takiego jak perspektywa danych to anachronizm. Podejście to w 100% zostały już dawno zastąpione przez MDA.
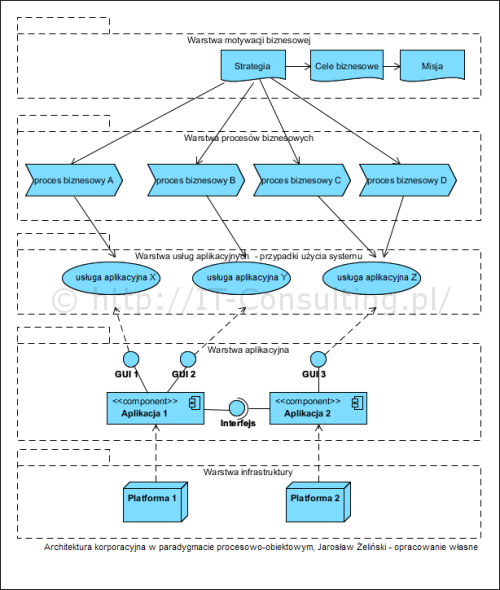
Autor prezentuje podejście, które nazywam podejściem "opartym na danych". Co mam na myśli? Otóż podejście to zakłada, że istotą "systemu" jakim jest organizacja są gromadzona i zarządzane dane (wiedza). Inne podejście, nazwę je operacyjne (lub procesowe), zakłada że istotą organizacje jest odgrywanie określonej roli na rynku (dostawca produktów, usługodawca, itp.). Innymi słowy istotne jest to co potrafię zaoferować a nie to jakimi danymi dysponuję.
Zakup oprogramowania, które stanowi jeden, zintegrowany współdzieleniem danych, monolit to nic innego jak zafundowanie sobie długu technologicznego w momencie podjęcia decyzji o takim zakupie. Żadna firma, działająca w obecnych czasach, nie da sama sobie gwarancji, że jej wewnętrzne aktywności nie zmienią się co do ich specyfiki, że nie przybędzie nowych, nie zrezygnuje z niektórych. Monolityczny całościowy system ERP stanowi hamulec każdej takiej zmiany. Oparcie całości na centralnym , współdzielonym module rejestrującym (jest z nim z reguły księgowość) to niemalże "zabetonowanie" architektury biznesowej firmy.