Diagram aktywności UML – kiedy
Wprowadzenie
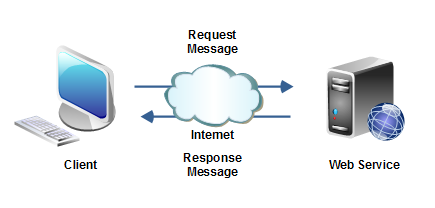
Od czasu do czasu jestem pytany o to, kiedy używać diagramu aktywności UML. Od 2015 roku specyfikacja UML wskazuje, że diagramy te są narzędziem modelowania metod czyli logiki kodu (dla Platform Independent Model): aktywności (activities) to nazwy metod, zadania/kroki (actions) to elementy kodu (przykłady w dalszej części).
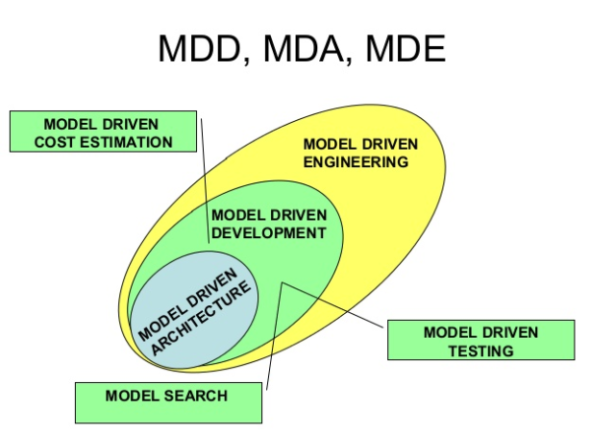
Gdy powstawał UML, diagramy aktywności były używane także do modelowanie procesów biznesowych. W roku 2004 opublikowano specyfikację notacji BPMN, która w zasadzie do roku 2015 “przejęła” po UML funkcję narzędzia modelowania procesów biznesowych. W 2015 roku formalnie opublikowano specyfikację UML 2.5, gdzie generalnie zrezygnowano z używania UML do modeli CIM. Obecnie Mamy ustabilizowaną sytuację w literaturze przedmiotu: BPMN wykorzystujemy w modelach CIM (modele biznesowe), UML w modelach PIM i PSM jako modele oprogramowania (a modele systemów: SysML, profil UML).

Tak więc obecnie:
Nie używamy diagramów aktywności do modelowania procesów biznesowych. Do tego służy notacja BPMN!
Diagram aktywności może być modelem kodu na wysokim lub niskim poziomie abstrakcji, operujemy wtedy odpowiednio aktywnościami (activity) lub działaniami (actions). Te ostatnie to w zasadzie reprezentacja poleceń programu.
Nie ma czegoś takiego jak “proces systemowy”, oprogramowanie realizuje “procedury”.
Projektując oprogramowanie zgodnie ze SPEM , powstaje Platform Independent Model. W praktyce już na tym etapie programujemy, bo tworzymy logikę i obraz przyszłego kodu. Taka forma dokumentowania pozwala także lepiej chronic wartości intelektualne zamawiającego.
(więcej…)