Wprowadzenie Bardzo często można w książkach i na blogach spotkać opisy wzorców architektonicznych, wzorców projektowych, dobrych praktyk. Jednak bardzo rzadko autorzy piszą o tym kiedy je stosować. Sam fakt, że jakiś wzorzec "rozwiązuje jakiś problem", co jest celem tworzenia i stosowania danego wzorca, nie mówi nic o tym jak często i kiedy dany problem się pojawia. Komputer może być częścią firmy, samochodu, lodówki, telewizora, może być platformą dla oprogramowania użytkowego albo dla gier komputerowych, ale te - użyte - staja sie częścią tego komputera (gramy na komputerze a nie na…

architektura systemu workflow
Wprowadzenie
Najbardziej wartościową umiejętnością architekta nie jest pisanie kodu, lecz umiejętność projektowania systemów, w których kod można łatwo usuwać i podmieniać. […] Kluczem do sukcesu jest projektowanie jeszcze przed napisaniem pierwszej linii kodu, ze szczególnym naciskiem na możliwość łatwego usuwania i podmieniania komponentów. Wyznaczenie granic między modułami, określenie interfejsów i interakcji, a także przewidzenie potencjalnych obszarów zmian to fundament dobrej architektury. [źr.: Dobry kod to taki, który łatwo usunąć]
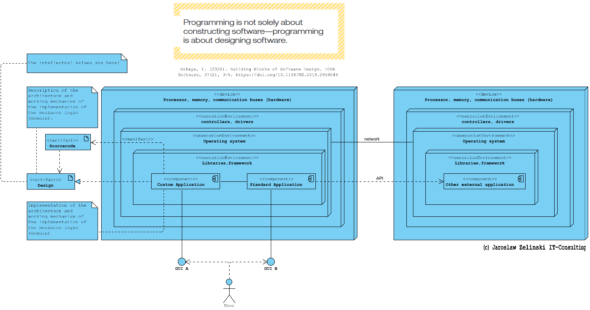
W 2017 roku napisałem referat na pewną konferencję naukową studentów. Artykuł dotyczył architektury kodu. Jedną z ilustracji była ta:
Artykuł kończyłem słowami:
Nie chodzi więc o to by podzielić oprogramowanie na “składowe, które łączą w sobie możliwość przechowywania danych oraz wykonywania operacji”. Chodzi o to by mechanizm, o dowiedzionej poprawności, zaimplementować w określonej wybranej technologii.Chodzi też o to by nie udawać, że programowanie jako “podzielone na obiekty” partie kodu, nadal korzystające z jednej wspólnej bazy danych, różni się czymkolwiek od “strukturalnego kodu”. Chodzi o to by kod programu faktycznie implementował określony (zbadany i opisany) mechanizm. (źr.: Architektura kodu aplikacji jako pierwszy etap tworzenia oprogramowania – Jarosław Żeliński IT-Consulting)
W 2021 roku opisałem Architektoniczne wzorce projektowe w analizie i projektowaniu modelu dziedziny systemu. Artykuł jest ukierunkowany na ich definicje i modelowanie. Tu kilka słów na temat tego “skąd się biorą i po co”.
(więcej…)
Wprowadzenie Na temat tego jakim uciążliwym długiem technologicznym jest monolityczny system napisano wiele, dzisiaj kolejne dwie ciekawe pozycje literatury: CMMI Compliant Modernization Framework to Transform Legacy Systems oraz Practical Event-Driven Microservices Architecture: Building Sustainable and Highly Scalable Event-Driven Microservices . Pierwsza publikacja opisuje metodę zaplanowania wyjścia z długu technologicznego z perspektywy analizy biznesowej, druga opisuje możliwą realizację techniczną z perspektywy architektury aplikacji i ewolucyjnej migracji z architektury monolitycznej do komponentowej (mikro-serwisy). Jedno jest ważne: analiza tabel SQL w starym systemie jest najmniej efektywna metodą wyjścia z takiej aplikacji. Czym jest…
Wprowadzenie Tym razem krótka recenzja pewnej książki z roku 2006, a raczej jej polecenie każdemu projektantowi i architektowi dzisiaj. Na końcu polecam także kolejną nowszą pozycję jako uzupełnienie. Adresatami tej recenzji są głównie analitycy i projektanci, jednak adresuję ten wpis także do developerów, zakładam że dla nich nie jest to "coś nowego", ale być może mają jakieś rady dla projektantów. Warto także podkreślić, że pomiędzy OOP a OOAD jest coraz większa różnica i podział na role: analiza i projektowanie oraz implementacja, a także postępująca separacja tych ról, stają się standardem…
This time a short article about an interesting construction. It was described by Rebecca Wirfs-Brock in 1999 (Miller & Wirfs-Brock, 1999) . The idea did not gain much popularity at the time, but now, in the era of patterns based on microservices and micro applications, it has a chance to come back into favour. I've been using it for a long time (see interface-oriented design). The abbreviations HLD and LLD are High-Level Design and Low-Level Design, respectively. These are the levels of abstraction in the PIM model. It is also a description of the design style of an interface-oriented system architecture (interface-oriented architecture).

Koder vs. projektant
https://dataedo.com/cartoon
Lektura na Nowy Rok... Co prawda wydana w 2007 roku, ale właśnie sobie o niej przypomniałem.. Ta książka Yourdona leży u mnie na półce niemalże od dnia jej wydania, gdy ją przypadkiem upolowałem, zaraz po jej ukazaniu się w księgarniach. Napisanie o niej odkładam od lat, bo praktycznie nie ma tam obrazków UML, opisów wzorców itp.. Od jej przeczytania mówię sobie: jutro o niej napiszę... i to trwało do tego momentu. To książka w całości napisana prozą, bez obrazków, w której autor dzieli sie swoimi przemyśleniami na temat architektury systemów,…
Tym razem o czymś co potrafi zabić ;) czyli czym jest dokument oraz fakt i obiekt. Czym się różni zakup kilku produktów, w tym samym sklepie, w np. godzinnych odstępach czasu, od zakupu wszystkich razem? Poza formą udokumentowania, niczym: w sklepie to samo i tyle samo zeszło ze stanu magazynu, a my wydaliśmy w obu przypadkach tyle samo pieniędzy (o promocjach później)! W pierwszym przypadku mamy kilka faktów zakupu, w drugim, jeden, ale zawsze tyle samo obiektów (produkt). Faktura (paragon) to dokument opisjący fakt, przedmiot sprzedaży jest obiektem. Tu obiektem…
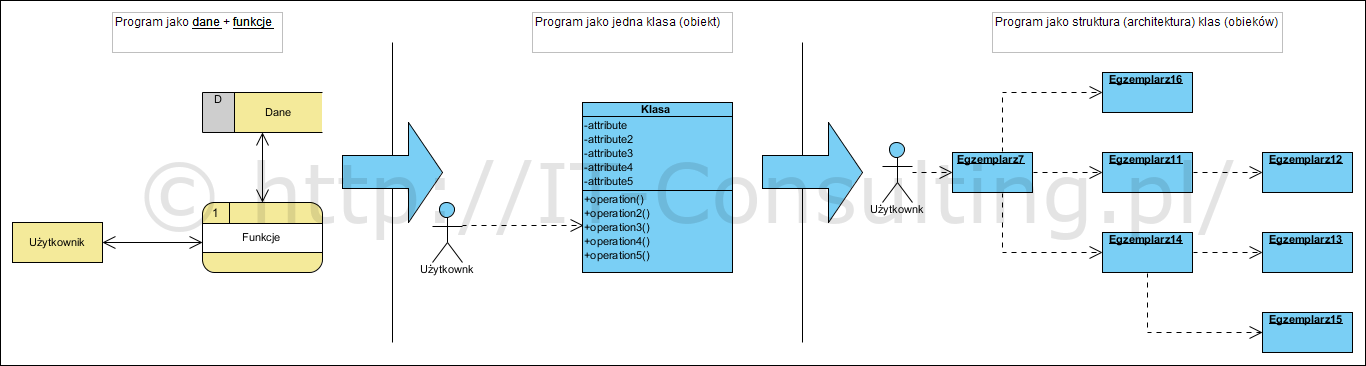
Ten artykuł to próba przybliżenia czytelnikowi pojęcia metamodel i model. To także mała próbka tego co jest produktem nadzoru autorskiego. Nieco ponad pięć lat temu w artykule Diagram obiektów czyli bottom-up pisałem o pojęciu instancji obiektu i diagramie obiektów. Wtedy skupiłem się na jednym tylko wątku, jakim jest analiza zmierzająca do opracowania ... no właśnie, czego? Z reguły autorzy dokumentów zawierających "diagramy klas" mówią, że tworzą modele. Czy zawsze są to modele? Wprowadzenie Jednym z bardzo niedocenianych typów diagramów UML są diagram obiektów i diagram wdrożenia (który jest rodzajem diagramu…
W artykule Ile przypadków użycia opisałem przypadki użycia jako narzędzie definiowania zakresu projektu, czyli sposób dokumentowania wymagań. Takie jego zastosowanie jest zdefiniowane w specyfikacji UML . Tym razem chcę ostrzec przed bezkrytycznym "uczeniem się" ze stron internetowych, nawet tych uznawanych powszechnie za "dobre i popularne". Sam niektóre z nich polecam, ale coraz częściej, nie całe serwisy jako takie, a tylko określone artykuły. Modernanalyst.com też do nich należy. Dziś będzie to artykuł, którego nie polecam, a opiszę go, bo autor powiela w nim dość powszechne błędy notacyjne, błędy które stały się…
Niedawno przeczytałem, że: "Chmura obliczeniowa szturmem zdobywa rynek IT. Liczba wdrożeń oprogramowania w modelu SaaS rośnie w tempie 20,1 proc. rdr ? podają analitycy z firmy Gartner. Na naszych oczach odbywa się rewolucja, której największą ofiarą jest oprogramowanie instalowane na własnej, firmowej infrastrukturze. Agonię wdrożeń ?on-premises? wieści Eric Kimberling, partner zarządzający w firmie doradczej Panorama Consulting. Jego zdaniem chmura obliczeniowa posiada tak wiele zalet, że porzucenie przez przedsiębiorstwa rozwiązań stacjonarnych jest jedynie kwestią czasu." https://fintek.pl/chmura-wykonczy-wdrozenia-on-premises-sm?/ Źródło: Chmura wykończy wdrożenia ?on-premises?. Ich śmierć ma być powolna, ale definitywna ? Fintek.pl…
Pojęcie nadzoru autorskiego budzi wiele emocji, w branży IT jest to chyba temat tabu, głównie z powodu nadużyć twórców i dostawców oprogramowania, a także dlatego, że tu (branża IT) prawo nie zabrania pełnienia przez jeden podmiot roli projektanta i wykonawcy. Z danych Panorama Consulting wynika, że zaledwie 12% przedsiębiorstw nie wprowadza żadnych modyfikacji systemu ERP jednak 70% firm wprowadza modyfikacje w aplikacji sięgające 25% (źr. 2017-ERP-Report): Na budowie Autor pewnego bloga prawnego poruszył ciekawy problem, który występuje także w projektach IT. Tu niezbyt często (a szkoda) ale występuje prawie zawsze…
W efekcie systemy nazywane nadal ERP to raczej już tylko jądro zarządzania (nadal bardzo ważne) integrowane z dziedzinowymi podsystemami (np. wymienionymi wyżej) innych producentów, aniżeli wielki zintegrowany, kosztowny i we wdrożeniu i w utrzymaniu moloch. ERP w reklamowanej jako "system do wszystkiego" ma raczej sens w małej firmie o nieskomplikowanej działalności, większe firmy wymagają jednak większej podatności ma zmiany czego ERP w "jednym kawałku" nigdy nie da, a duży jednorazowy koszt jest zbyt wielkim ryzykiem.