Dokument i jego struktura jako metoda zarządzania danymi
Wprowadzenie
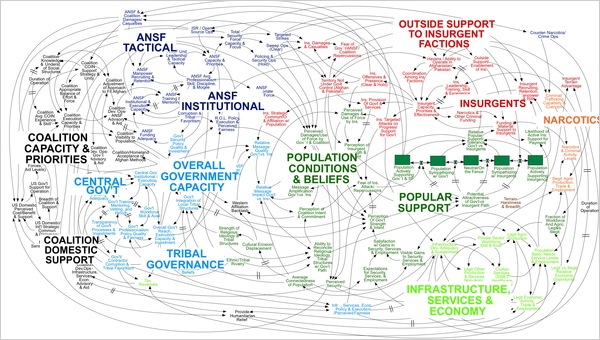
Bardzo wiele problemów w toku wdrożeń IT rodzą wadliwie zaprojektowane struktury dokumentów. Dotyczy to w szczególności zarządzania dostępem do treści, a patrząc szerzej: do informacji. Ostatnie lata to między innymi problemy urzędów z udzielaniem dostępu do informacji publicznej, od dwóch lat dodatkowo problemy stwarza RODO. Źródłem problemów jest treść dokumentów, rozumiana jako pytanie: “Czy te informacje muszą być zawarte w tym dokumencie”. Najpierw opiszę mechanizm powstawania przyczyn problemów i sposób ich rozwiązania. W podsumowaniu wskażę jak i gdzie sobie z tym radzić.
(więcej…)