Repozytorium w chmurze – NoSQL
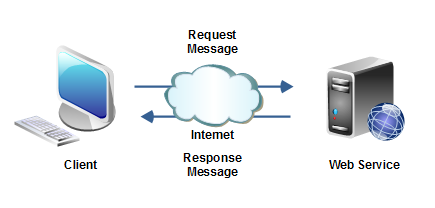
Wprowadzenie Coraz częściej czytamy o środowiskach "chmurowych" (nadal nie mogę się przekonać do pisania tego bez cudzysłowu). Nawet tak zaawansowane jak Amazon WS czy AZURE, są nadal bardzo często wykorzystywane tylko jako hosting aplikacji. Oba te serwisy można wykorzystywać jako sieciowy dysk, środowisko systemowe (Windows, Linux), bazę danych SQL, ale także jako bazy NoSQL. Jednym z najistotniejszych elementów systemów informacyjnych (patrz: information science) jest utrwalanie danych (pamiętajmy, że dane to zapisy, a informacja to to, co rozumie człowiek, który je czyta). Niedawno nawiązywałem do problemu utrwalania danych. Poprawna obiektowa architektura…