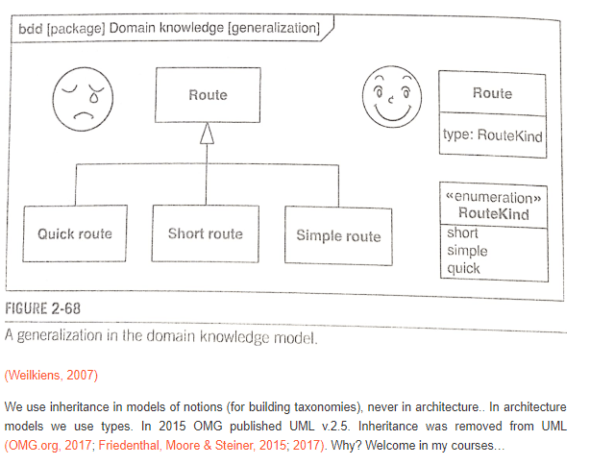
Wprowadzenie Jedną z największych pomyłek inżynierii oprogramowania jest dziedziczenie, czyli odtwarzanie w kodzie taksonomii modeli pojęciowych. Nie mniejszą pomyłką jest teza, że OO to łączenie funkcji i danych w obiekty (to jest antywzorzec projektowy, patrz np. DDD czy BCE). Obiektowy paradygmat to wymiana komunikatów między obiektami. Komputer nie przetwarza ani ludzi ani przedmiotów, więc odtwarzanie w architekturze kodu tego, że np. koń to rodzaj ssaka nie ma żadnego sensu, za to znakomicie komplikuje architekturę kodu. Utrwalanie tego w setkach powiązanych relacyjnie tabel dodatkowo komplikuje wszystko (kolejne setki linii kodu SQL).…
Wprowadzenie Tym razem krótka recenzja pewnej książki z roku 2006, a raczej jej polecenie każdemu projektantowi i architektowi dzisiaj. Na końcu polecam także kolejną nowszą pozycję jako uzupełnienie. Adresatami tej recenzji są głównie analitycy i projektanci, jednak adresuję ten wpis także do developerów, zakładam że dla nich nie jest to "coś nowego", ale być może mają jakieś rady dla projektantów. Warto także podkreślić, że pomiędzy OOP a OOAD jest coraz większa różnica i podział na role: analiza i projektowanie oraz implementacja, a także postępująca separacja tych ról, stają się standardem…
W dwóch ubiegłorocznych artykułach pisałem o modelach pojęciowych oraz o związkach w UML. Opisałem je od strony notacyjnej. Dzisiaj o ich zastosowaniu. Generalnie zagadnienia modeli pojęciowych, abstrakcji i metamodeli oraz związków między nimi są dość trudne (wbrew pozorom, większość ludzi ma problem z abstrakcyjnym myśleniem), jako narzędzia są bardzo przydatne w analizie i projektowaniu. Rzecz w tym, że systemy analizowane istnieją, co znaczy ni mniej ni więcej tylko to, że "są dobre bo są i działają". Gorzej jest gdy system, nie raz nietrywialny, jest na etapie projektowania. Wtedy o tym jest "dobry"…

#1 - a 3d render series showing change and motion
Wstęp Tym razem o kilku powszechnie popełnianych błędach w korzystaniu z UML. Chodzi o pojęcia abstrakcji, metamodeli i zależności oraz o związki między elementami na diagramach. Kluczową, moim zdaniem, przyczyną tworzenia "złych" modeli obiektowych jest używanie notacji UML do tworzenia modeli strukturalnych, nie mających z obiektowym paradygmatem nic wspólnego. Druga to niezrozumienie pojęcia paradygmatu obiektowego. Ogromna ilość diagramów wykonanych z użyciem symboli notacji UML, z UML i paradygmatem obiektowym ma niewiele wspólnego. Najpierw kilka definicji i pojęć. Paradygmat programowania (ang. programming paradigm) ? wzorzec programowania komputerów przedkładany w danym okresie…
Dzisiaj będzie bardzo krótki wpis, którym niemalże w całości będzie cytat z artykułu pewnego programisty. Każdy analityk i projektant powinien przeczytać cały artykuł (nie jest długi) i koniecznie komentarze pod nim. Jeden komentarz zacytuje bo jest znamienny, choćby dlatego, że moje doświadczenia są dokładnie takie same: Co Ty człowieku, życia nie znasz? Przecież w realu jakbyś poszedł do takiego i podzielił się takimi uwagami to foch na pare tygodni co najmniej gwarantowany. Kiedyś miałem podobną sytuację (a raczej serię sytuacji, ale dotyczących rzeczy o mniejszej skali) to efekt był taki,…