Zapraszam wszystkich, którzy szukają pomocy, wiedzy oraz wsparcia w swoich projektach informatyzacji. Działam od 1991 roku, mój Blog działa nieprzerwanie od 1998 roku.
Jeżeli nie potrafisz czegoś narysować to znaczy że nadal tego nie rozumiesz. Jeżeli potrafisz coś narysować to potrafisz to także zbudować.
Zależnie od szacunków (czyli od tego jak zdefiniowano sukces) 60 - 80% projektów IT to nieudane projekty. Pod pojęciem projektu IT rozumiemy tu systemy dla firm: szeroko pojęte systemy biznesowe. Na świecie każdego dnia inicjowanych są setki tysięcy projektów IT dla firm, śladowe ilości nowych gier i w zasadzie żaden nowy system operacyjny (co najwyżej jego drobne rozszerzenia i aktualizacje). Dlatego nie ma sensu by w projektach biznesowych stosować wzorce i metody sprawdzone w tworzeniu gier czy środowisk technologicznych. Dlatego zlecanie projektów biznesowych od razu deweloperom ma bardzo nikłe szanse…
Wprowadzenie Oprogramowanie na obecnym rynku, w ogromnej ilości, nadal stanowią produkty powstałe ponad dwie dekady temu (legacy systems). Znakomita większość powstawała ewolucyjnie. Lata 90-te to bardzo często monolity budowane w oparciu o EJB, JavaEE i nieco później Microsoft .NET. Są to wzorce powstała na bazie relacyjnego modelu danych i skryptów transakcyjnych. "W anemicznym projekcie domeny logika biznesowa jest zwykle implementowana w oddzielnych klasach, które przekształcają stan obiektów domeny. Fowler nazywa takie zewnętrzne klasy skryptami transakcyjnymi. Ten wzorzec jest powszechnym podejściem w aplikacjach Java, wspieranym przez technologie takie jak wczesne wersje…
Wprowadzenie Swego czasu opisywałem wzorce projektowe i API (Integracja systemów ERP jako źródło przewagi rynkowej. Projektowanie REST API i scenariuszy). Kluczowym wzorcem jest wzorzec SAGA, czyli sterowanie sekwencją wymiany danych z jednego miejsca. Wzorzec ten to typowy system klient-serwer (usługobiorca-usługodawca) i sprawdza się doskonale, gdy sterowanie z jednego miejsca rozwiązuje wszystkie problemy integracji. Pewnym problem jest tu jednak to, że serwer musi zostać odpytany by klient poznał jego stan, a nie zawsze jest to wystarczające. Opis problemu Wyobraźmy sobie, że mamy system WMS (ang. Warehouse Managements System, zarządzanie magazynami) oraz…
Wprowadzenie W 2021 roku, w artykule Transformacja Cyfrowa a dziedzictwo IT pisałem: Aby transformacja cyfrowa była w ogóle możliwa, musimy przenieść te dane (treści, informacje) z papieru „do komputera”, w sposób nieniszczący obecnych możliwości i pozwalający na tworzenie nowych. Trzeba też zniwelować posiadany dług technologiczny. Dług technologiczny to posiadane dziedzictwo, to zapóźnienie, to pozostawanie w tyle za trwającym postępem technologicznym. Dług taki ma bardzo wiele firm https://it-consulting.pl/2021/11/21/cyfrowa-transformacja-a-dziedzictwo-it/ W tym tekście poruszam pokrewny temat jakim jest zabezpieczenie się, bo kluczowe pytanie brzmi: co zabezpieczyć mając "wszystko w wersji elektronicznej"? Bardzo często…
Wprowadzenie W roku 2017 komentowałem dokument, który Ministerstwo Cyfryzacji opublikowało (Opublikowano: 22.11.2017), zatytułowany "Wzorcowe klauzule w umowach IT". Czytam tam między innymi: Klauzule zostały opracowane na zlecenie Ministra Cyfryzacji przez zespół kancelarii MARUTA WACHTA Sp. j. pod kierownictwem mec. Marcina Maruty i mec. Bartłomieja Wachty. Wykorzystano w nich również uwagi pracowników administracji publicznej, zarówno prawników, jak i specjalistów z dziedziny IT. (źr. https://www.gov.pl/cyfryzacja/wzorcowe-klauzule-w-umowach-it) Moje uwagi umieściłem we wpisie: Wzorcowe klauzule w umowach IT. Gorąco polecam przeczytanie, opisałem tam kwestie słownika w Umowie, który jest kluczem dla brzmienia Umowy i jej późniejszej interpretacji. Te klauzule nadal są oficjalne…
"Jeśli myślisz, że dobra architektura jest droga, spróbuj złej" Wstęp W roku 2008 pisałem (Forbs): W wielu firmach decyzja o wdrożeniu systemu informatycznego bardzo często nie jest poprzedzona żadnymi przygotowaniami w rodzaju oceny struktury organizacji, jej zdolności do zmian czy też uporządkowaniem obiegu informacji. Częstym grzechem jest próba ?wtłoczenia? w system informatyczny ?starego? porządku. Drugi grzech to brak opisanego systemu informacyjnego. W efekcie następuje zderzenie rygorów papierowego obiegu informacji z obiegiem danych w systemie informatycznym. Rezygnacja z wielu czynności (np. stawianie pieczątek i podpisów) lub zamiany ich na inne staje się kluczowym, bronionym jak niepodległości przez wielu kierowników…
Friedenthal, S., Moore, A., & Steiner, R. (2015). A practical guide to SysML: The systems modeling language (Third edition). Elsevier, MK, Morgan Kaufmann is an imprint of Elsevier. https://www.sciencedirect.com/book/9780128002025/a-practical-guide-to-sysml
Wprowadzenie Pojęcie 'system' stało się bardzo popularne, głównie za sprawą "systemów informatycznych", jednak jego rodowód jest starszy i pochodzi nie od technologii a od biologii . Poza IT mamy systemy bezpieczeństwa, system ubezpieczeń, system emerytalny, system prawa, i wiele innych. Słownik języka polskiego podaje taką definicję pojęcia system: układ elementów mający określoną strukturę i stanowiący logicznie uporządkowaną całość zespół wielu urządzeń, dróg, przewodów itp., funkcjonujących jako całość narządy lub inne części żywego organizmu pełniące razem określoną funkcję uporządkowany zbiór twierdzeń, poglądów, tworzących jakąś teorię określony sposób wykonywania jakiejś czynności lub…
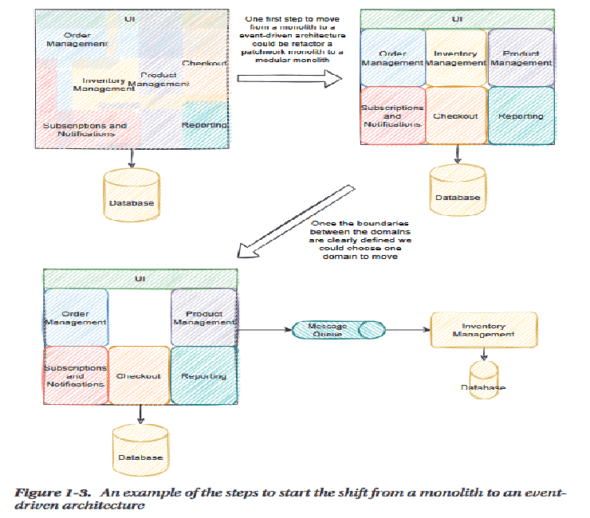
Wprowadzenie Na temat tego jakim uciążliwym długiem technologicznym jest monolityczny system napisano wiele, dzisiaj kolejne dwie ciekawe pozycje literatury: CMMI Compliant Modernization Framework to Transform Legacy Systems oraz Practical Event-Driven Microservices Architecture: Building Sustainable and Highly Scalable Event-Driven Microservices . Pierwsza publikacja opisuje metodę zaplanowania wyjścia z długu technologicznego z perspektywy analizy biznesowej, druga opisuje możliwą realizację techniczną z perspektywy architektury aplikacji i ewolucyjnej migracji z architektury monolitycznej do komponentowej (mikro-serwisy). Jedno jest ważne: analiza tabel SQL w starym systemie jest najmniej efektywna metodą wyjścia z takiej aplikacji. Czym jest…
Friedenthal, S., Moore, A., & Steiner, R. (2015). A practical guide to SysML: the systems modeling language (Third edition). Elsevier, MK, Morgan Kaufmann is an imprint of Elsevier. https://www.sciencedirect.com/book/9780128002025/a-practical-guide-to-sysml
Przykład Nie używamy notacji BPMN do modelowania tego co się dzieje na produkcji. Notacja BPMN nie operuje pojęciami takimi jak stanowisko, maszyna, operacja, produkt i półprodukt czy BOM zaś czynności ludzi w toku produkcji to nie "aktywności" w procesie a "operacje". Skoro nie BPMN to czego używamy? Produkcja (proces produkcji) to przekształcenie surowca (zestawu półwyrobów) w produkt, w BPMN jest to jedno zadanie na "modelu procesów biznesowych". Produkty oraz cały system ich wytwarzania to "system". Całość to nie jest "proces składający sie z kilkudziesięciu prac", całość to marszruta i operacje…
Wprowadzenie Notacja EPC (Event-driven Process Chain) została opracowana w 1992 roku w ramach projektu badawczo-rozwojowego z udziałem SAP AG na University of Saarland w Niemczech, a jej twórcą jest dr August-Wilhelm Scheer. Stanowi ona kluczowy element koncepcji modelowania SAP R/3 w zakresie inżynierii biznesowej i dostosowania tego systemu do potrzeb klienta, została włączona także do systemu NetWeaver firmy SAP. Ostatni duży projekt z jej użyciem realizowałem w 2008 roku dla polskiego oddziału niemieckiego banku WestLB Bank Polska SA. Później już jedynie okazjonalne wsparcie merytoryczne i audyty, nadal się zdarzają. EPC…
Artykuł ma dwie części. Pierwsza część jest adresowana do kadr zarządczych, cały artykuł (obie części) do osób zajmujących się projektowaniem rozwiązań.
Wstęp
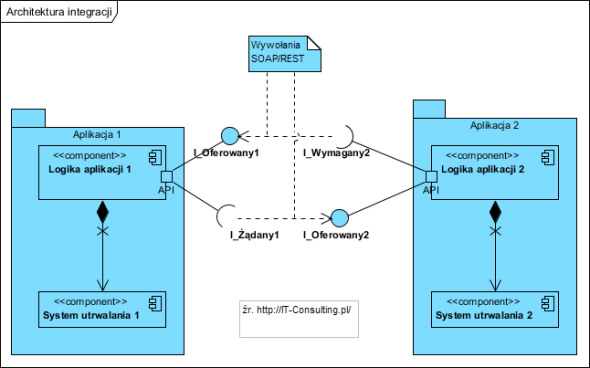
Mamy ogólnoświatową sieć Internet, aplikacje lokalne i w chmurze, aplikacje naszych kontrahentów i aplikacje centralnych urzędów. Wszystkie one współpracują i wymieniają dane, czyli są zintegrowane. Dlatego integracja stała się cechą każdego systemu informatycznego.
Wyjątkowo na początku (poniżej) umieszczam cały ten ciekawy referat, można bo pominąć i czytać dalej, jednak jeżeli ktoś chce poznać przewidywania z roku 2016 i ma czas, polecam (teraz lub później):
The Future of Software Engineering ? Mary Poppendieck ? GOTO 2016
Obecnie kluczowym pytaniem jest: Jak zintegrować, a nie: Czy zintegrować.
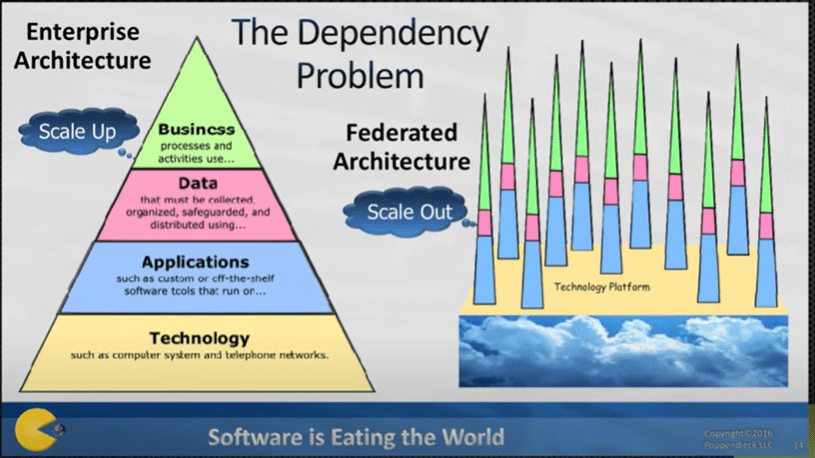
Pogodzenie się z tym, że świat systemó ERP już nigdy nie będzie tak prosty jak w czasach mainframe’ów, czyli jednej centralnej aplikacji, jest nieuniknione.
Czym jest obecnie integracja? To wymiana danych a nie ich współdzielenie: dane z urzędem wymieniamy, dane z kontrahentem wymieniamy, nie współdzielimy żadnych danych z tymi podmiotami, każdy ma swoje własne, bezpieczne bazy danych, i to wszystko ładnie działa! Idea zbudowania wszystkich funkcjonalności jako zintegrowanej aplikacji na jednej współdzielonej bazie danych w czasach obecnych jest utopią. Taką samą jak hipotetyczna centralna baza danych dla wszystkich sklepów internetowych, firm kurierskich i banków, a one są jednak zintegrowane: one wymieniają dane a nie współdzielą!
ERP to (ang.) Enterprise Resource Planning czyli Planowanie Zasobów Przedsiębiorstwa. To system wykorzystywany przez firmy do zarządzania i integrowania ważnych elementów ich działalności. Ale kto powiedział, że to ma być monolit od jednego producenta?
Nadal spotykam pejoratywne określenia “system pointegrowany” jako krytykę budowy systemu ERP z komponentów i integracji jako wymiany danych. Autor tego określenia najprawdopodobniej nadal żyje w świecie mainframe.
Chociaż dostawcy systemów ERP oferują aplikacje dla przedsiębiorstw i twierdzą, że ich zintegrowany system jest najlepszym rozwiązaniem, wszystkie moduły w jednym systemie ERP rzadko kiedy są najlepsze z najlepszych.
Autor recenzowanego tekstu odnosi sie do skutków ekonomicznych, pomija jednak całkowicie skutki prawne kastomizacji kodu oprogramowania, które mają wpływ na koszty i ochronę wartości intelektualnych. Autor pisze we wstępie:
Celem niniejszego opracowania jest analiza możliwych metod kastomizacji systemów informatycznych zarządzania przeprowadzona z ekonomicznego punktu widzenia, w tym w szczególności opłacalności stosowania oprogramowania standardowego i wykorzystania poszczególnych metod jego adaptacji. […] Kastomizację systemu informatycznego ogólnie należy rozumieć jako jego adaptację do potrzeb konkretnego podmiotu. M. Flasiński określił kastomizację, jako ?konfigurację systemu, osadzenie w systemie za pomocą prac programistycznych dodatkowych funkcjonalności oraz modyfikację istniejących funkcjonalności systemu?
Dostarczanie oprogramowania i jego wdrażanie, wiąże się jego ewentualnym dostosowaniem do potrzeb użytkownika. Autor powyższego opracowania, stosując nieprecyzyjne definicje pojęć, wprowadza czytelnika w błąd, opisując przyczyny i konsekwencje związane z szeroko pojętym dostosowaniem oprogramowania do potrzeb użytkownika.
Niestety z tego dokumentu korzysta wielu prawników, nazywając go nie raz nawet “wykładnią”.