Szperałem w sieci szukając informacji o architekturze i microservisach, a wpadłem na to: ... communication between two different software modules is proportional to the communication between the designers and developers of these modules. Conway?s law exposes the vulnerability in monoliths as they grow in size. Micro-services may not be the best, but better than monoliths for the contemporary web based applications. (Źródło: Micro-Services: A comparison with Monoliths | My Blog) To "prawo" wyjaśnia dlaczego powstają złe interfejsy a nawet zła architektura: z reguły dlatego, że to - architektura - jest lepszym lub…
Jedna z ciekawszych i popularniejszych książek (ja mam dodruk z 2010 roku). Bardzo często spotykam się w sieci z powoływaniem się na tę książkę w kwestii "wzorców analitycznych". Jednak po pierwsze nie należy zapominać, że napisana została w 1996 roku (od tamtej pory mamy jednak pewien postęp, do tego książka jest ilustrowana symbolami opartymi na notacji ERD a nie UML), a po drugie, o czym wielu zapomina, Fowler prezentuje w niej modele koncepcyjne a nie strukturalne (wytłuszczenie moje): Analysis Patterns provides a catalogue of patterns that have emerged in a wide…
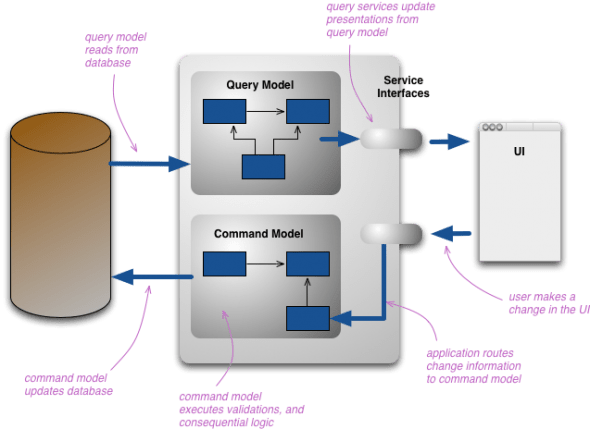
Rok temu pisałem o wzorcu CQRS, tamten wpis bazował głównie na artykule M.Fowlera i stanowił raczej zajawkę tematu. Teraz mam troszkę własnych doświadczeń, także w dyskusjach z programistami, i przytoczę tu moja konkluzję, nieco chyba odbiegającą od opisu M.Fowlera, którego albo nie zrozumiałem ale on uprościł swój wpis (dzięki czemu ja wtedy nie zrozumiałem). Mamy problem polegający na tym, że firma ma ogromną ofertę pewnych bardzo złożonych podzespołów, żeby nie psuć ich opisu i możliwości rozbudowy, model dziedziny odwzorowuje strukturę tych części. Jednak bardzo duża liczba użytkowników sklepu internetowego…
Często słyszę, że to trudne i pracochłonne (dodatkowe klasy w modelu) ale niestety zbyt prosty projekt potrafi być kosztowniejszy w rozbudowie w porównaniu z pierwotnym wytworzeniem, dlatego jak klient w ramach wymagań wpisuje (a wpisuje coraz częściej): system ma umożliwiać łatwe rozszerzenia funkcjonalności, to należy go tak projektować, w przeciwnym wypadku wymaganie to nie jest spełnione...Druga uwaga: często sami klienci zabijają swoje projekty żądając na samym początku dokumentowania wszystkich szczegółów jakie im do głowy przyjdą nie potrafiąc jednocześnie opisać mechanizmu działania ich organizacji. To niestety często spotykane zjawisko, z którym moim zdaniem należy walczyć. Paradoksalnie złożoność systemów biznesowych tkwi w mechanizmie ich funkcjonownia a nie w danych które zbierają (których nie raz jest po prostu za dużo...)
Swego czasu na jednej z konferencji o analizie wymagań, mówiłem o potrzebie zrozumienia funkcjonowania analizowanej organizacji (firmy):...wszystko to co nas otacza, samo w sobie jest naturalnie proste. Złożone są, nie poszczególne rzeczy, a to, że jest ich wiele i mają na siebie wzajemny wpływ. Pamiętajmy, że jedna z najtrudniejszych gier na świecie ? szachy ? to tylko kilkanaście figur i proste reguły ich przemieszczania. Nawet największą organizację można, w toku analizy, rozłożyć na skończoną liczbę ról i reguł ich postępowania i zrozumieć jej funkcjonowanie. (żr. Jarosław Żeliński, referat na konferencji o systemach ERP).Analiza biznesowa to etap opisu (zrozumienia) modelowanej organizacji (modele procesów itp.). Potem, powstaje model rozwiązania, którym jest nie raz własnie oprogramowanie, jego logika (patrz powyższy cytat) to "obiektowy model dziedziny systemu", a nie jakiś diagram klas nafaszerowany atrybutami i pozbawiony operacji bo jest dokładnie odwrotnie...
Opisując wymagania wyłącznie jako "czarną skrzynkę" nie wiem co dostanę. Większość developerów będzie dążyło do uproszczenia implementacji (ich koszt, nie raz brak wiedzy) by zaspokoić na minimalnym poziomie wymagania opisane przypadkami użycia. Nie raz klient słyszy "tu musimy to uprościć bo tak się nie da", a zamawiający, nie mając kompetencji by polemizować z taką opinią, zgadza się i dostarczony system staje się zgniłym kompromisem opartym właśnie na "czarnej skrzynce" jako specyfikacji zamówień: "dostaliśmy dokładnie to co zamówiliśmy ale zupełnie nie to czego naprawdę potrzebujemy".Tak więc,nie ma znaczenia fakt, że na pewno są na rynku developerzy znający problem, który opisałem i stosujący opisane tu rozwiązanie takich problemów. Jednak nawet cień ryzyka (a jest ono na prawdę duże), że dostaniemy bubla, daje zamawiającemu prawo do szczegółowego definiowania wymagań jako "białej skrzynki", bo dzięki temu zamawiający dostanie "to czego potrzebuje a nie tylko to co zamówił".
Fowler pyta o to, o co wielu wielu informatyków: czy dostarczenie firmie kolejnych nowych możliwości, powinno się realizować poprzez napisanie (tworząc dedykowane) potrzebne nowe oprogramowanie, czy poprzez zakup gotowego oprogramowania. Ogólnie opinia, zalecane podejście przez Fowlera to: jeżeli proces wymagający wsparcia nowym oprogramowaniem, to proces kluczowy dla utrzymania konkurencyjności lepiej stworzyć oprogramowanie dedykowane do tego procesu. Jeżeli to jeden z procesów pomocniczych, efektywniej będzie kupić gotowe oprogramowanie i dostosowanie do niego procesu w firmie. Co ciekawe, podobnie jak ja, zaleca w przypadku gotowego oprogramowania dostosowanie się do niego a nie dostosowywanie oprogramowania do siebie.