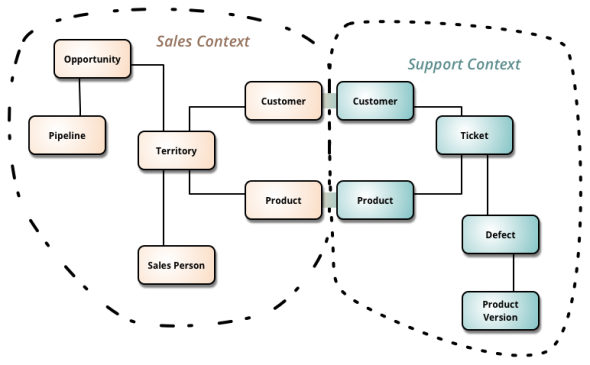
Separacja kontekstu i znaczeń w metodach obiektowych
Separacja kontekstu dziedziny oraz separacja synonimów jako metoda zapewnienia jednoznaczności modeli obiektowych. Streszczenie: Przedstawiono metodę pozwalającą zapewnić jednoznaczność modeli obiektowych mimo istnienia synonimów w słownictwie analizowanego problemu. Wykorzystano znaną juz metodę separowania kontekstów, autor proponuje dodatkowy prosty metamodel (profil UML) pozwalający na bezpieczne użycie tego samego pojęcia zarówno jako nazwy obiektu jak i nazwy cechy obiektu. Słowa kluczowe: UML, profil, metody obiektowe, kontekst ___ Wprowadzenie Wielu autorów piszących o projektowaniu oprogramowania zwraca uwagę na problemy związane z kontekstem i synonimami pojęć w badanej dziedzinie. Jednym z popularniejszych autorów, zwracających uwagę na…