(źr.: https://www.redhat.com/en/topics/microservices/what-are-microservices)
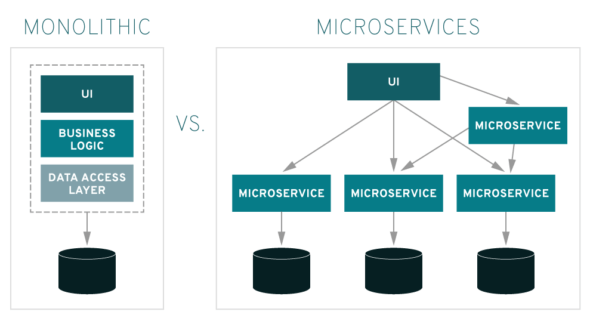
Wprowadzenie Często spotykaną definicją mikro-serwisów jest W inżynierii oprogramowania architektura mikro-serwisów to wzorzec architektoniczny, który organizuje aplikację w zbiór luźno powiązanych, drobnoziarnistych usług, które komunikują się za pośrednictwem lekkich protokołów. Wzorzec ten charakteryzuje się możliwością niezależnego opracowywania i wdrażania usług, poprawiając modułowość, skalowalność i zdolność adaptacji. Wprowadza on jednak dodatkową złożoność, szczególnie w zarządzaniu systemami rozproszonymi i komunikacją między usługami, czyniąc początkową implementację trudniejszą w porównaniu do architektury monolitycznej. (https://en.wikipedia.org/wiki/Microservices) To samo źródło dalej: Nie istnieje jedna, powszechnie uzgodniona definicja mikro-serwisów. Ogólnie jednak charakteryzują się one skupieniem na modułowości, a…
Ten często aktualizowany przeze mnie wpis, stał się niemalże kompletnym opisem metodyki projektowania oprogramowania. Nie jest to "moja metodyka", to dorobek dziesiątek autorów, z którego ja także korzystam (artykuł zaopatrzyłem w bogaty spis literatury źródłowej i kilka ciekawych referatów konferencyjnych). Polecam szczególnie moim studentom oraz obecnym i potencjalnym klientom, bo to opis produktu jaki ode mnie dostaną (polecam także wpis: Moja rola w projektach). Prowadzę również warsztaty analizy i projektowania. Programming is not solely about constructing software—programming is about designing software. [Programowanie nie polega wyłącznie na tworzeniu oprogramowania - programowanie…
Wprowadzenie Na temat tego jakim uciążliwym długiem technologicznym jest monolityczny system napisano wiele, dzisiaj kolejne dwie ciekawe pozycje literatury: CMMI Compliant Modernization Framework to Transform Legacy Systems oraz Practical Event-Driven Microservices Architecture: Building Sustainable and Highly Scalable Event-Driven Microservices . Pierwsza publikacja opisuje metodę zaplanowania wyjścia z długu technologicznego z perspektywy analizy biznesowej, druga opisuje możliwą realizację techniczną z perspektywy architektury aplikacji i ewolucyjnej migracji z architektury monolitycznej do komponentowej (mikro-serwisy). Jedno jest ważne: analiza tabel SQL w starym systemie jest najmniej efektywna metodą wyjścia z takiej aplikacji. Czym jest…
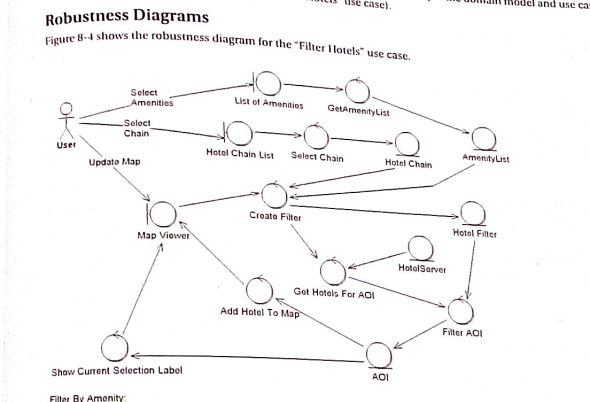
Wprowadzenie Jest to diagram, który na równi z Diagramem Klas, budzi bardzo często ogromne problemy interpretacyjne (patrz: Diagram klas...). Bardzo wielu autorów przypisuje temu diagramowi role, których on nie pełni, a nie raz prezentowane w sieci i literaturze przykłady są niepoprawne. Znakomita większość autorów tych diagramów używa ich jako "zbioru możliwych kliknięć" co jest całkowitym niezrozumieniem celu użycia i idei tego diagramu. Nawet jeżeli ktoś potrzebuje takiej mapy klikania, to są do tego lepszych narzędzia i metody (przykład: Mapa ekranów aplikacji ? podstawa dobrego UX/UI design). Tworzenie niezgodnych z notacją…
Practical Event-Driven Microservices Architecture Building Sustainable and Highly Scalable Event-Driven MicroservicesHugo Rocha ma prawie dziesięcioletnie doświadczenie w pracy z wysoce rozproszonymi, sterowanymi zdarzeniami architekturami mikroserwisów. Obecnie jest szefem inżynierii w wiodącej globalnej platformie ecommerce dla produktów luksusowych (Farfetch), świadczącej usługi dla milionów aktywnych użytkowników, wspieranej przez architekturę sterowaną zdarzeniami z setkami mikroserwisów przetwarzających setki zmian na sekundę. Wcześniej pracował dla kilku referencyjnych firm telekomunikacyjnych, które przechodziły od aplikacji monolitycznych do architektur zorientowanych na mikroserwisy. Hugo kierował kilkoma zespołami, które każdego dnia bezpośrednio stykają się z ograniczeniami architektur sterowanych zdarzeniami. Zaprojektował…

(źr. Martin Fowler, Analysis Patterns, 1997)
Wprowadzenie W 2019 opisałem swoistą próbę rewitalizacji wzorca BCE (Boundary, Control, Entity). Po wielu latach używania tego wzorca i dwóch latach prób jego rewitalizacji uznałem jednak, że Zarzucam prace nad wzorcem BCE. Podstawowy powód to bogata literatura i utrwalone znaczenia pojęć opisujących ten wzorzec. Co do zasady redefiniowanie utrwalonych pojęć nie wnosi niczego do nauki. Moja publikacja zawierająca także opis tego wzorca bazowała na pierwotnych znaczeniach pojęć Boundary, Control, Entity. Sprawiły one jednak nieco problemu w kolejnej publikacji na temat dokumentów . Dlatego w modelu pojęciowym opisującym role komponentów przyjąłem następujące bazowe stwierdzenie:…
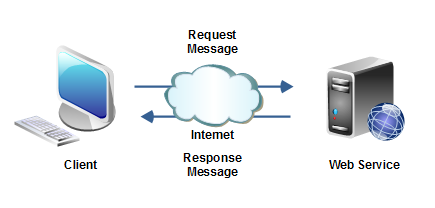
Architektura referencyjna przeglądarki internetowej i aplikacji webowych.
Dwa lata temu pisałem o mikroserwisach: Obecnie mamy już dość dobrze wypracowane wzorce projektowe ale nadal jest problem ze zrozumieniem ?kiedy i jak?. Ładnie to opisał swego czasu E.Evans przy okazji wzorca DDD, Tu poprzestanę jedynie na pojęciu bounded context czyli ?granica kontekstu?. Granica ta ma podwójne znaczenie: kontekst nadaje (zmienia) znaczenia w modelu pojęciowym (bałwan w kontekście zimy to co innego niż bałwan w kontekście członków zespołu projektowego) oraz kontekst (bardzo często) wyznacza zakres projektu (inne aspekty wzorca DDD tu pominę). Pierwsza uwaga: kontekst dziedzinowy (pojęciowy) jest ważniejszy (powinien…
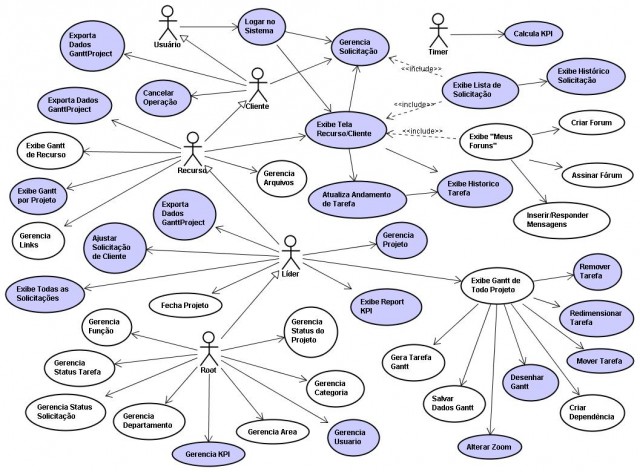
Analizy biznesowe wymagają oderwania się od technokracji, nie ma czegoś takiego jak dziesiątki przypadków użycia dla jednej faktury, nie ma systemowych przypadków użycia (nawet w specyfikacji UML ich nie znajdziecie), są kompletne (dające jako efekt przydatne produkty) usługi aplikacyjne i korzystający z tych usług aktorzy, w tym inne aplikacje lub komponenty. Dokumentacje zawierające setki przypadków użycia to nieporozumienie, technokratyczni zabójcy projektów. Warto się zastanowić zanim powierzycie analizę i projekt logiki systemu technokratycznemu developerowi...