(źr.: https://www.redhat.com/en/topics/microservices/what-are-microservices)
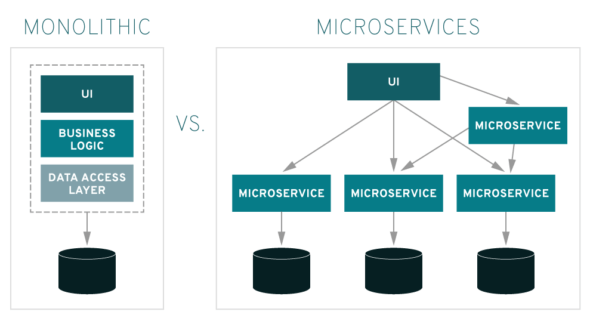
Wprowadzenie Często spotykaną definicją mikro-serwisów jest W inżynierii oprogramowania architektura mikro-serwisów to wzorzec architektoniczny, który organizuje aplikację w zbiór luźno powiązanych, drobnoziarnistych usług, które komunikują się za pośrednictwem lekkich protokołów. Wzorzec ten charakteryzuje się możliwością niezależnego opracowywania i wdrażania usług, poprawiając modułowość, skalowalność i zdolność adaptacji. Wprowadza on jednak dodatkową złożoność, szczególnie w zarządzaniu systemami rozproszonymi i komunikacją między usługami, czyniąc początkową implementację trudniejszą w porównaniu do architektury monolitycznej. (https://en.wikipedia.org/wiki/Microservices) To samo źródło dalej: Nie istnieje jedna, powszechnie uzgodniona definicja mikro-serwisów. Ogólnie jednak charakteryzują się one skupieniem na modułowości, a…
Wprowadzenie Jest to diagram, który na równi z Diagramem Klas, budzi bardzo często ogromne problemy interpretacyjne (patrz: Diagram klas...). Bardzo wielu autorów przypisuje temu diagramowi role, których on nie pełni, a nie raz prezentowane w sieci i literaturze przykłady są niepoprawne. Znakomita większość autorów tych diagramów używa ich jako "zbioru możliwych kliknięć" co jest całkowitym niezrozumieniem celu użycia i idei tego diagramu. Nawet jeżeli ktoś potrzebuje takiej mapy klikania, to są do tego lepszych narzędzia i metody (przykład: Mapa ekranów aplikacji ? podstawa dobrego UX/UI design). Tworzenie niezgodnych z notacją…
Dwa lata temu pisałem o mikroserwisach: Obecnie mamy już dość dobrze wypracowane wzorce projektowe ale nadal jest problem ze zrozumieniem ?kiedy i jak?. Ładnie to opisał swego czasu E.Evans przy okazji wzorca DDD, Tu poprzestanę jedynie na pojęciu bounded context czyli ?granica kontekstu?. Granica ta ma podwójne znaczenie: kontekst nadaje (zmienia) znaczenia w modelu pojęciowym (bałwan w kontekście zimy to co innego niż bałwan w kontekście członków zespołu projektowego) oraz kontekst (bardzo często) wyznacza zakres projektu (inne aspekty wzorca DDD tu pominę). Pierwsza uwaga: kontekst dziedzinowy (pojęciowy) jest ważniejszy (powinien…
Niestety wiele systemów ERP i i nie tylko, powstało w latach 90'tych, mają one niestety scentralizowaną architekturę strukturalną (jedna baza danych i "nad nią" funkcje przetwarzające te dane). Efekty tego widać przy wdrożeniach, w których dopuszczono tak zwaną kastomizacje systemu, czyli właśnie wprowadzanie, nie raz bardzo wielu, zmian. To bardzo kosztowne projekty o praktycznie nieprzewidywalnym budżecie. Niestety współdzielenie danych wewnątrz takiego systemu jest jego poważną wadą a nie - jak to zachwalają ich dostawcy - zaletą...
Analizy biznesowe wymagają oderwania się od technokracji, nie ma czegoś takiego jak dziesiątki przypadków użycia dla jednej faktury, nie ma systemowych przypadków użycia (nawet w specyfikacji UML ich nie znajdziecie), są kompletne (dające jako efekt przydatne produkty) usługi aplikacyjne i korzystający z tych usług aktorzy, w tym inne aplikacje lub komponenty. Dokumentacje zawierające setki przypadków użycia to nieporozumienie, technokratyczni zabójcy projektów. Warto się zastanowić zanim powierzycie analizę i projekt logiki systemu technokratycznemu developerowi...