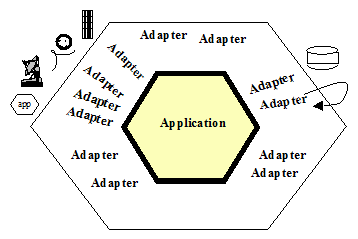
Wprowadzenie Bardzo wiele emocji budzą kwestie styku aplikacji i jej środowiska: mój wpis na LinkedIn "Czy logowanie jest przypadkiem użycia" wzbudził burzliwą dyskusję i wiele kontrowersji. Ten artykuł to opis modelu aplikacji i jej środowiska. Kluczowe pojęcia Pojęcie aplikacja jest definiowane (SJP) jako "komputerowy program użytkowy". Biorąc pod uwagę fakt, że słownikowo "użytkownik" to osoba (użytkownik - osoba lub instytucja użytkująca coś, SJP), aplikacja to "program użytkowy dla człowieka". W specyfikacji notacji UML czytamy: Przypadki Użycia są środkiem do uchwycenia wymagań systemów, tj. tego, co systemy mają robić. Kluczowymi pojęciamiw…
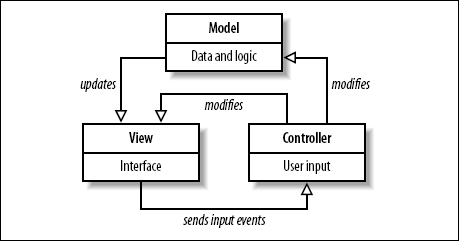
Wprowadzenie Wzorzec ten budzi wiele kontrowersji co do tego czym są te trzy komponenty. Popatrzmy do anglojęzycznej WIKI: Model - Centralny komponent wzorca. Jest to dynamiczna struktura danych aplikacji, niezależna od interfejsu użytkownika. Bezpośrednio zarządza danymi, logiką i regułami aplikacji. W Smalltalk-80, model jest całkowicie pozostawiony programiście. W WebObjects, Rails i Django, model zazwyczaj reprezentuje tabelę w bazie danych aplikacji. https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller Jest to dominująca definicja w literaturze, zaś spory o to czym jest Model w architekturze MVC jak widać mają jedno główne źródło: jakiego frameworka używa osoba wchodząca w takie…
W perspektywie krótkoterminowej architektura oprogramowania pomaga zredukować czas i koszty rozwoju.W dłuższej perspektywie architektura oprogramowania pomaga zredukować koszty utrzymaniu. https://medium.com/@learnwithwhiteboard_digest/basics-of-software-architecture-a-guide-for-developers-8098a76881ca Wstęp W 2017 roku pisałem dość ogólnie o logice wzorca architektonicznego MVC kończąc artykuł słowami: A gdzie mityczna baza danych? Tam gdzie jej miejsce: zarządza danymi utrwalanymi w pamięci. Baza danych i systemy zarządzania danymi w architekturze obiektowej nie stanowią miejsca na logikę biznesową, standardowym wzorcem projektowym jest tu active records. Podstawową zaletą stosowanie tego wzorca jest separacja utrwalonych danych od aplikacji. To pozwala skupić całą logikę i jej zmienność w kodzie aplikacji i jego architekturze. Dzięki temu…
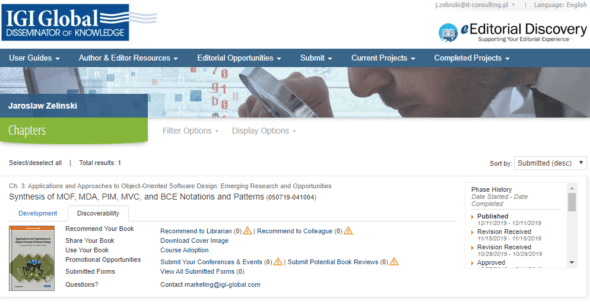
Miło mi poinformować, że moja publikacja naukowa (tu była zapowiedź) na temat syntezy wzorców architektonicznych i wzorców projektowych, systemów obiektowo-zorientowanych zatytułowana: Synthesis of MOF, MDA, PIM, MVC, and BCE Notations and Patterns po długim procesie selekcji i recenzowania, została zakwalifikowana do publikacji i właśnie się ukazała jako jeden z rozdziałów książki: Applications and Approaches to Object-Oriented Software Design: Emerging Research and Opportunities. Jeszcze milej mi poinformować, że - jako współautor - mogę Wam zaoferować kod promocyjny dający 40% zniżki na zakup: IGI40. Poniżej informacje o książce i o wydawcy. O…
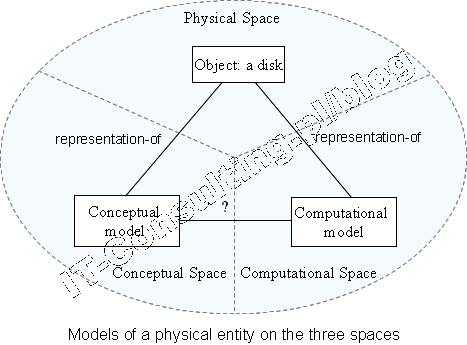
W ostatnim artykule zwracałem uwagę między innymi na bardzo ważny element analizy i projektowania jakim jest abstrahowanie od detali, ponieważ: ...analityk musi abstrahować od wszelkich detali, bez tego projekt zostanie już na samym początku ?zabity? ich ilością. [1] Nieco wcześniej (2013 r.) pisałem o tym, kiedy uzgadniać detale, które i gdzie one są: Cała logika biznesowa jest wykonywana wewnątrz aplikacji (informacje o ewentualnych błędach pojawią się po zatwierdzeniu formularza), np. upust może być sprawdzony (albo naliczony) dopiero po skompletowaniu danych wymaganych do jego wyliczenia, czyli będzie to kilka różnych pól (najmniej dwa…
Wprowadzenie bardzo często mozna spotkać opisu typu: MVC architecture. AngularJS divides your web app into three distinct parts — Model (data), View (the UI layer), and Controller (business logic). The three units can be developed in parallel and separately tested. As a result, the code becomes easier to understand, maintain, and extend. (https://www.altexsoft.com/blog/the-good-and-the-bad-of-angular-development/) Niestety jest to powielanie podejścia z czasów lat 90-tych i JavaEE/SE. Patrząc na te trzy pojęcia View to owszem "widoki" czyli GUI, nieporozumienia dotyczą Model'u i Controler'a. Poniżej obecne źródło (jedno z wielu) tego nieporozumienia: Model to…
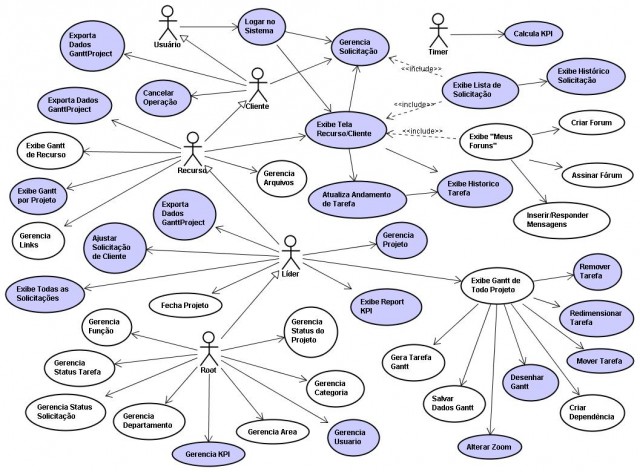
Tak więc przypadkami użycia opisujemy abstrakcję jaką jest [[Model Dziedziny Systemu]]. Są one wtedy proste, zawierają scenariusz, który w skrócie ma postać: aktor inicjuje usługę, system prezentuje formularz do wypełnienia, aktor wypełnia go i potwierdza, system potwierdza odebranie danych i pokazuje wynik swojej pracy (lub komunikaty o błędach). Tu skupiamy się na opisie tego jakie usługi są wymagane od systemu. Kolejny etap to "komplikowanie" każdego scenariusza w postaci projektowania, dla każdego przypadku użycia, różnego rodzaju wizardów lub wprowadzamy ograniczenia związane z uprawnieniami użytkowników. Ten etap to praca projektantów UX i grafików, specjalistów od ergonomii itp.
Jak wspomniałem, wielu dostawców oprogramowania jak Rejtan, broni się przed ujawnianiem architektury, swoich produktów. Głównym powodem jest zapobieganie przedwczesnego wyjawienia opisanych wyżej wad systemów z grubym klientem (znacznie rzadziej spektakularny pomysł, w końcu mamy jednak jakieś standardy). Przypadki, w których zakup systemu był relatywnie niski ale koszt utrzymania, rozwoju i dostosowania nie raz wręcz ogromny, to z reguły właśnie zakup systemu w tej kosztownej architekturze.
Jak starać się tego unikać? Na etapie definiowania wymagań poza-funkcjonalnych, żądać takich cech jak opisane powyżej czyli własnie: dostęp do całości przez przeglądarkę WWW, niskie wymagania na łącza przy zdalnej pracy i pracy w sieci rozproszonej terytorialnie, oddzielenie komponentu z własną dedykowaną logiką biznesową.

Słownik pojęć (często występuje w dokumentach jako czysto polskie słowo glossariusz ;)) bywa często przedmiotem burzliwych negocjacji, bo nie raz (a w zasadzie zawsze ;)) biznes stosuje slang, w którym to samo słowo ma różne znaczenie, zależnie od kontekstu użycia. Może to mieć sens w języku mówionym gdy pełna treść wypowiedzi daje ten kontekst, ale na poziomie analizy i projektu każde pojęcie musi mieć jedno unikalne znacznie mimo braku kontekstu (tym bardziej, że np. nazwy klas nie są elementami pełnych zdań ani opowieści :)).[...] Biznes także musi zrozumieć, że ma dwa różne elementy opisu swoich działań: praca z dokumentami i tworzenie dokumentów. Jednak uznanie tego faktu to jedno, nie wierzę w to, że biznes się tego nauczy, bo nie nauczył się formalnego opisu lub modelowania procesów podczas wdrożeń ISO, jednak uważam, że biznes nie ma takiej potrzeby. Moim zdaniem od dobrego analityka nie ma ucieczki, to inna kompetencja. Nie ma ucieczki od projektantów mody mimo istnienia kobiet chcących mieć ładne sukienki i bardzo dobrych krawców. Nikt tu nikogo nie zastąpi.
Dzisiaj krótki artykuł o wymaganiach dziedzinowych. W jednym z poprzednich artykułów pisałem o wymaganiach, że problem tkwi w ich zrozumieniu i o tym, że przyszły użytkownik nie powinien pisać "jaki ma być ten program", bo popycha projekt w stronę chaotycznych oczekiwań. I tu jest sedno: analiza nie powinna być tylko pasmem wywiadów, którego produktem będę setki stron zapisów z ankiet i przeprowadzonych rozmów. Analiza, to duża praca, której celem powinno być zrozumienie a nie tylko opisanie. (Analiza wymagań na oprogramowanie czyli opisanie czy zrozumienie). Wymagania najczęściej dzielimy na funkcjonalne i…

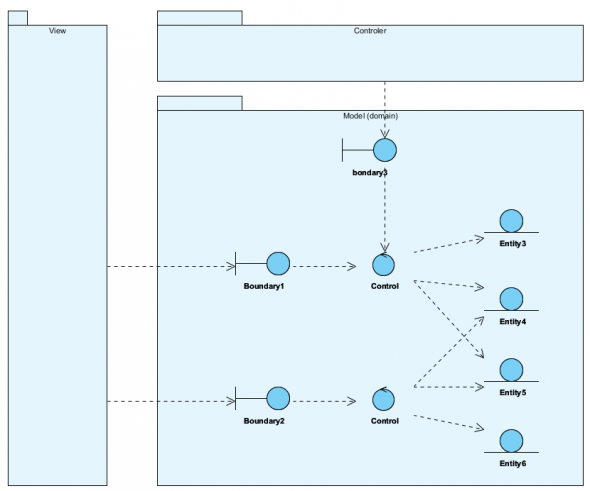
Opisywałem ostatnio wzorzec DDD jako narzędzie dokumentowania analizy. Faktycznie, czytelnicy mają wiele racji, jest on dość "bliski implementacji". Niejednokrotnie "lepszym pomysłem" jest opis logiki systemu na nieco wyższym poziomie abstrakcji pozostawiając tym samym więcej swobody developerowi. [...] Nieco inne podejście, to które stosuję obecnie, opisuję poniżej. Zachowując podstawowe znaczenia tych trzech klas, dostosowałem je do wzorca MVVC. Jest to o tyle wygodne i ważne, że stosowanie wzorca BCE wyłącznie do modelowania logiki biznesowej wymaga zachowania hermetyzacji komponentu Model. W takim układzie boundary nie będzie elementem komponentu View a Modelu. Jego rola to stworzenie dedykowanego interfejsu do model np. pomiędzy komponentem View lub Controlerem. Dzięki temu możliwe jest stworzenie odrębnego interfejsu dla View na duży ekran i odrębnego dla View na np. małych ekranach smartfonów. Tak więc jest moim zdaniem droga do modelowania wymagań metodą "tak to ma działać" a nie tylko "tak to ma wyglądać", bo to drugie jest przyczyną wielu problemów...

zły model to złe oprogramowanie....Duży system ERP to setki i tysiące jego przypadków użycia, nie ma sensu ich specyfikowanie podobnie jak nie ma sensu pytanie o nie przyszłych użytkowników tego systemu bo nie są w stanie ich wyliczyć. Ma jednak sens zrozumienie tego jak firma działa. Po raz kolejny posłużę się metaforą [[Martina Fowlera]]: grę w snookera można opisać relacjonując (zapisując) setki kolejnych partii, ale i tak nigdy nie wyspecyfikujemy nawet ułamka możliwych zagrań. Zdecydowanie lepszą metodą jest przyjrzenie się kilku partiom i wychwycenie cech bili, ich ilości, wymiarów stołu oraz reguł gry, bo to będzie zgodne nie tylko z historią odegranych partii snookera ale z każda przyszłą partią.Dlatego zamiast prowadzenia żmudnych wywiadów i tworzenie nieskutecznej listy setek szczegółowych opisów możliwego użycia oprogramowania, lepiej jest zrozumieć organizację, stworzyć jej model (dziedziny) i wyspecyfikować jakie usługi ma to oprogramowanie świadczyć użytkowników teraz (bo tak należy rozumieć pojęcie przypadku użycia systemu). Poprawny model dziedziny pozwoli także na obsługę przyszłych wymagań mimo, że nie znamy ich teraz. Podobnie jak stół bilardowy: nie zna przyszłych uderzeń ale wiemy, że na pewno zostaną "obsłużone".