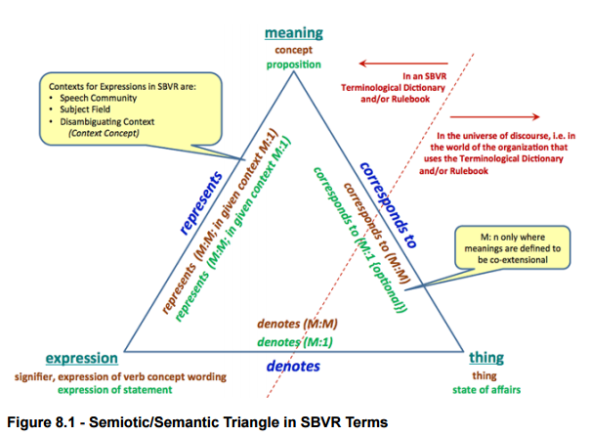
Model pojęciowy IT – przykład analizy pojęciowej
Wprowadzenie W branży IT dość często mylone są pojęcia dotyczące techniki i technologii. Dobrym więc ruchem było uporządkowanie tego. Na stronie Rady Języka przy Prezydium Polskiej Akademii Nauk ukazała się ciekawa publikacja (jako, że to definicje, które omówię, cytuję w całości) : Definicje podstawowych pojęć związanych z techniką i technologią Komunikat Zespołu Terminologii Informatycznej RJP Nr 2/2021 z 16 czerwca 2021 roku Definicje podstawowych pojęć: {technika|technologia}{informacyjna|przetwarzania informacji|informatyczna|cyfrowa} Wychodząc od zasady, że częścią pojęcia „technika” jest „technologia”, a z kolei w definicji „technologii” należy się odwołać do użytych technik (tzw. definicja rekurencyjna), przedstawiamy zestaw tych definicji.…