Zapraszam wszystkich, którzy szukają pomocy, wiedzy oraz wsparcia w swoich projektach informatyzacji. Działam od 1991 roku, mój Blog działa nieprzerwanie od 1998 roku.
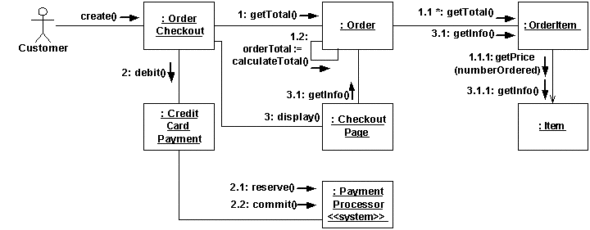
Jeżeli nie potrafisz czegoś narysować to znaczy że nadal tego nie rozumiesz. Jeżeli potrafisz coś narysować to potrafisz to także zbudować.
Publikacja zawiera ontologiczną analizę pojęć dokument, podpis, uwierzytelnienie i prawdziwość treści oraz dedukcyjne wnioski na temat prawdziwości treści i pojęcia autorskich praw osobistych. Zbudowano i opisano dziedzinowy model pojęciowy obszaru utrwalania treści i jej prawdziwości a także problem wiarygodności treści, omówiono pojęcie utrwalania i archiwizacji. Poruszono także tematykę pojęć dane i metadane. Wprowadzenie W styczniu 2025 UOKiK wydał decyzję, w której Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego…
Wprowadzenie Niedawno miała miejsce kolejna moja dyskusja na LinkedIn, która pokazała że prawo własności intelektualnej jest bardzo trudne do przyswojenia, głównie dlatego że – z uwagi na swoją „niematerialność” – wymyka się intuicyjnej i materialnej manierze postrzegania świata przez człowieka. Na to nakłada się przeświadczenie koderów, że z zasady są samodzielnymi twórcami, i niestety wielu prawników także tak uważa. Rzecz w tym, że koder zawsze jest twórcą, ale nie zawsze jest projektantem. Gdy koder nie jest projektantem, jego utwory (kod źródłowy) to utwory zależne od utworów pierwotnych, jakimi są projekty techniczne wyrażone np. z pomocą…
Często spotykam się z różnymi metodami uwzględniania prawa w dokumentacji wymagań. Jakim wymaganiem jest zgodność z obowiązującym prawem? I trudniejsze pytanie: czy zmiana prawa to zmiana wymagań? Inny aspekt problemu to analiza i definicja (opis) tej zgodności z prawem. Spotkać można się z metodą polegającą na traktowaniu każdego (mającego wpływ na system) paragrafu np. ustawy jako wymagania. Problem zgodności oprogramowania z prawem ma dwa aspekty. Zgodność oprogramowania z prawem polega na tym, że ??oprogramowanie nie może ograniczać stosowania prawa to jest nie może wymuszać swoimi ograniczeniami działań niezgodnych z prawem?. Ja osobiście rekomenduję rozciągnięcie tej definicji na ??ani nie powinno pozwalać na łamanie prawa?. Tu jednak wielu uważa, że ??zamawiam narzędzie i używam jak chcę, na swoja odpowiedzialność?. Coś w tym jest, warto jednak zostawić ??włącznik?. (źr.: Prawo a wymagania … )
Dzisiaj czytam:
To administrator odpowiada za zabezpieczenia systemów, a więc także za to, że pracownik zdołał skopiować dane osobowe na zewnętrzny nośnik. […] W ocenie WSA w toku postępowania PUODO prawidłowo ustalił, iż w SGGW dopuszczono się licznych uchybień, w szczególności nie przeprowadzono właściwej analizy ryzyka i oceny zagrożeń już na etapie projektowania systemów (privacy by design) oraz nie wdrożono odpowiednich środków zapewniających bezpieczeństwo danych, w tym przed możliwością wyeksportowania danych z systemu na zewnątrz.(źr.: Odpowiedzialność administratora za naruszenie zasady privacy by design), wyrok WSA w Warszawie z 13 maja 2021 r. (II SA/Wa 2129/20).
Rzecz w tym, że administrator, w rozumieniu prawa, to także podmiot zlecający powstanie oprogramowania, które go wspiera w realizacji jego obowiązków, a jednym z tych obowiązków jest egzekwowanie ustalonych zasad. Dzisiaj o tym, że zbieranie “podpisów pod oświadczeniami” to nie jest bezpieczeństwo.
Autor recenzowanego tekstu odnosi sie do skutków ekonomicznych, pomija jednak całkowicie skutki prawne kastomizacji kodu oprogramowania, które mają wpływ na koszty i ochronę wartości intelektualnych. Autor pisze we wstępie:
Celem niniejszego opracowania jest analiza możliwych metod kastomizacji systemów informatycznych zarządzania przeprowadzona z ekonomicznego punktu widzenia, w tym w szczególności opłacalności stosowania oprogramowania standardowego i wykorzystania poszczególnych metod jego adaptacji. […] Kastomizację systemu informatycznego ogólnie należy rozumieć jako jego adaptację do potrzeb konkretnego podmiotu. M. Flasiński określił kastomizację, jako ?konfigurację systemu, osadzenie w systemie za pomocą prac programistycznych dodatkowych funkcjonalności oraz modyfikację istniejących funkcjonalności systemu?
Dostarczanie oprogramowania i jego wdrażanie, wiąże się jego ewentualnym dostosowaniem do potrzeb użytkownika. Autor powyższego opracowania, stosując nieprecyzyjne definicje pojęć, wprowadza czytelnika w błąd, opisując przyczyny i konsekwencje związane z szeroko pojętym dostosowaniem oprogramowania do potrzeb użytkownika.
Niestety z tego dokumentu korzysta wielu prawników, nazywając go nie raz nawet “wykładnią”.
Dzisiejszy wpis to efekt lektury artykułu Pani Mec. Marty Pasztaleniec na stronie IP Procesowo. Kluczowe dla dzisiejszego wpisu jego fragmenty to:
Programy komputerowe w świetle krajowego prawa autorskiego korzystają ze szczególnej ochrony. Z uwagi na ich specyfikę wyłączono stosowanie niektórych regulacji z ogólnej części prawa autorskiego, w szczególności przepisów dotyczących dozwolonego użytku, który umożliwia w ściśle określonych okolicznościach korzystanie z utworów bez zgody twórcy, a nawet wbrew takiej zgodzie. Co do zasady zatem jakiekolwiek zwielokrotnienie programu komputerowego wymaga zgody twórcy. […] Spór ma swą genezę w 2005 r. kiedy to Google nabył startup Android Inc i rozpoczął starania by wejść na rynek smartfonów, tworząc platformę do budowy systemów dla urządzeń mobilnych. Platforma w swym założeniu miała być nieodpłatna po to by popularyzować środowisko Google. Jako że język programistyczny Java był wówczas jednym z najbardziej popularnych i powszechnych wśród programistów, Google podjął rozmowy z Sun Microsystems ? twórcą Java ? na temat licencjonowania całej platformy Java. Ostatecznie zdecydował się jednak na budowę własnej platformy. Aby jednak zapewnić jej powszechność i łatwość stosowania wśród programistów zastosowano w nim nazwy funkcji i formatów danych charakterystyczne dla języka Javy. Google de facto opracował własne odpowiedniki funkcji Javy i nadał im nazwy takie same jak w Javie. Oracle, po przejęciu spółki Sun Microsystems, pozwał w 2010 r. Google o naruszenie przysługujących Oracle praw autorskich i patentów. Zarzucono Google skopiowanie blisko 11 500 linii deklaracji API programu Java (co stanowiło 0,4 % deklaracji). […] Sąd uznał, że działanie Google było ?zgodne z kreatywnym ?postępem?, który jest podstawowym konstytucyjnym celem samego prawa autorskiego?. Według sądu dozwolony użytek pełni więc istotną rolę w rozwoju oprogramowania, a prawo autorskie nie powinno hamować tego rozwoju. (żr.: Dozwolony użytek programów komputerowych ? jak Google pokonał Oracle w USA).
Powyższy tekst wskazuje na dwa ciekawe aspekty oprogramowania, o których dzisiaj napiszę. Pierwszy to tak zwany dozwolony użytek, bardzo często przywoływany w sporach o bezpłatne użycie oprogramowania i zakres tego użycia. Najczęściej dotyczy gier komputerowych ale nie tylko. Drugi to charakter oprogramowania, jakim jest kod źródłowy będący tekstem, oraz efekt ostateczny, jakim jest “komputer realizujący określony mechanizm”, gdzie komputer definiujemy jako “procesor, pamięć i program” . Warto tu zwrócić uwagę na pewien “drobiazg”: autorka (jak wielu innych prawników) traktuje treść programu jako “tekst” i nie raz stosuje analogię do typowych utworów pisanych takich jak proza czy poezja, co jest poważnym błędem. Fragmenty tekstów (esej, praca doktorska, powieść, itp.) bardzo często mają wartość, czego o nie można powiedzieć o oprogramowaniu (nie działa w kawałkach). Owszem, można potraktować fragmenty kodu “literaturowo”, jako przykłady jego struktry i składni (np. literatura na temat wzorców projektowych w inżynierii oprogramowania), jednak nie można mówić o fragmencie kodu, że to “oprogramowanie”, gdyż to z zasady “musi działać”, a jest to możliwe tylko wtedy gdy do komputera załadujemy kompletny program a nie “cytowany fragment”.
Od czasu do czasu jestem pytany o to, kiedy używać diagramu aktywności UML. Od 2015 roku specyfikacja UML wskazuje, że diagramy te są narzędziem modelowania metod czyli logiki kodu (dla Platform Independent Model): aktywności (activities) to nazwy metod, zadania/kroki (actions) to elementy kodu (przykłady w dalszej części).
Gdy powstawał UML, diagramy aktywności były używane także do modelowanie procesów biznesowych. W roku 2004 opublikowano specyfikację notacji BPMN, która w zasadzie do roku 2015 “przejęła” po UML funkcję narzędzia modelowania procesów biznesowych. W 2015 roku formalnie opublikowano specyfikację UML 2.5, gdzie generalnie zrezygnowano z używania UML do modeli CIM. Obecnie Mamy ustabilizowaną sytuację w literaturze przedmiotu: BPMN wykorzystujemy w modelach CIM (modele biznesowe), UML w modelach PIM i PSM jako modele oprogramowania (a modele systemów: SysML, profil UML).
Na przełomie lat 80/90-tych rozpoczęto prace nad standaryzację notacji modelowania obiektowego, w 1994 opublikowano UML 0.9, w 2001 roku pojawiają się pierwsze publikacje o pracach nad notacją BPMN, jednocześnie pojawia się Agile Manifesto, od 2004 roku ma miejsce spadek zainteresowania dokumentowaniem projektów programistycznych, w 2004 rok publikowano specyfkację BPMN 1.0, od tego roku ma miejsce wzrost zainteresowania modelowaniem procesów biznesowych, powoli stabilizuje się obszar zastosowania notacji UML. W 2015 roku opublikowano UML 2.5, stosowanie analizy (CIM) i i projektowania (PIM), jako etapu poprzedzającego implementacje, stało się standardem (źr. wykresu: Google Ngram).
Tak więc obecnie:
Nie używamy diagramów aktywności do modelowania procesów biznesowych. Do tego służy notacja BPMN!
Diagram aktywności może być modelem kodu na wysokim lub niskim poziomie abstrakcji, operujemy wtedy odpowiednio aktywnościami (activity) lub działaniami (actions). Te ostatnie to w zasadzie reprezentacja poleceń programu.
Nie ma czegoś takiego jak “proces systemowy”, oprogramowanie realizuje “procedury”.
Projektując oprogramowanie zgodnie ze SPEM , powstaje Platform Independent Model. W praktyce już na tym etapie programujemy, bo tworzymy logikę i obraz przyszłego kodu. Taka forma dokumentowania pozwala także lepiej chronic wartości intelektualne zamawiającego.
Tym razem o czymś co potrafi zabić ;) czyli czym jest dokument oraz fakt i obiekt. Czym się różni zakup kilku produktów, w tym samym sklepie, w np. godzinnych odstępach czasu, od zakupu wszystkich razem? Poza formą udokumentowania, niczym: w sklepie to samo i tyle samo zeszło ze stanu magazynu, a my wydaliśmy w obu przypadkach tyle samo pieniędzy (o promocjach później)! W pierwszym przypadku mamy kilka faktów zakupu, w drugim, jeden, ale zawsze tyle samo obiektów (produkt). Faktura (paragon) to dokument opisjący fakt, przedmiot sprzedaży jest obiektem. Tu obiektem…
Ten artykuł to pewnego rodzaju kontynuacja poprzedniego: Vendor lock-in. Starałem się tu wyjaśnić czym jest projekt i wskazać, że pewne wywody prawników wydają się nie mieć żadnego uzasadnienia. Prawo autorskie Pomysł, aby ochronę rozwiązań branży IT oprzeć na prawie autorskim nie był specjalnie szczęśliwy. Prawo autorskie stworzono z myślą o twórcach oraz odbiorcach. (źr.: Prawa autorskie w projektach IT. Głównie o różnicach między przeniesieniem praw a licencjami) Zaskakuje mnie taka teza, bo prawo autorskie, jak sama nazwa wskazuje, stworzono z myślą o autorach. To, że ta konkretna ustawa zawiera wiele…
Powyższy tytuł to oryginalny tytuł jednego z cytowanych poniżej artykułów. Wybrałem go, bo obrazuje pewien problem na rynku IT (ale nie tylko na tym rynku). Ten problem to właśnie tak zwane "życzeniowe myślenie". Dotyczy ono zarówno oczekiwań jak i zobowiązań, tak dostawców jak i nabywców oprogramowania. Celowo nie piszę usługodawców IT, bo znakomita większość tak zwanych "projektów IT" ma za cel tylko to, by nabywca zyskał oprogramowanie, którego użyje jako narzędzia w prowadzonej przez siebie działalności. To czy kupi gotowe i wdroży, czy zleci jego stworzenie dla siebie, czy też…
Bardzo częste zapisy w umowach z dostawcami oprogramowania, mówiące że wszelkie wartości intelektualne powstające w trakcie projektu, przechodzą na własność dostawcy oprogramowania są potężnym nadużyciem, żeby nie powiedzieć: kradzieżą know-how.
Wstęp W artykule na temat ochrony know-how napisałem: Projektant (analiza biznesowa i projektowanie), na podstawie wymagań (biznesowych) Inwestora tworzy autorskie dzieło jakim jest Projekt rozwiązania. Na tej podstawie powstają Projekt implementacji i Kod aplikacji. Wszystkie te dokumenty chroni prawo autorskie, jednak Projekt implementacji i Kod aplikacji to dzieła zależne, pierwotnym utworem jest tu Projekt rozwiązania. Dlatego autor Projektu rozwiązania ma ustawowy nadzór autorski nad jego realizacją. (źr. Ochrona know-how Prawo autorskie) Dzisiaj opiszę problem prawnych zależności pojęciowych w projekcie informatycznym i odpowiedzialności (zobowiązań) stron umów, oraz to, jakie ma to konsekwencje…
Wprowadzenie Tematem numer jeden, niemalże w każdym moim projekcie, jest model biznesowy i tajemnica przedsiębiorstwa. Z perspektywy lat muszę powiedzieć, że to fobia wielu (jak nie większości) przedsiębiorców i nie tylko przedsiębiorców. Nie dlatego, że chcą coś chronić, ale dlatego co i jak chronią. Nie raz już pisałem, że firmy nie raz, najpierw podpisują z dostawcami rozwiązań i konsultantami umowy o poufności, a potem wyzbywają praw do swojego know-how na ich rzecz: W branży inżynierii oprogramowania dość powszechna jest sytuacja, gdy programista jest także projektantem, innymi słowy programista ma pełnię…