Wprowadzenie Ukazała się książka Prawo w IT. Praktycznie i po ludzku . Jako, że profesjonalnie zajmuję się tak zwanym IT, a z prawem dotyczącym IT mam ogromne doświadczenia jako biegły (ale prawnikiem nie jestem), ta książka od razu po wydaniu wylądowała się na moim biurku. Jak tylko zacząłem czytać zapadła decyzja: napisze recenzję. Czytam bardzo dużo, ale recenzuję (tu na blogu) książki bardzo dobre lub bardzo szkodliwe. Autor książki, Szymon Ciach (profil LinkedIn: "Attorney-at-law | Counsel @Osborne Clarke Poland | IT & Data".), profil na Cybergov.pl: Patron medialny książki ITwiz.…

Semiotic/Semantic Triangle in SBVR Terms
Ronald G. Ross Ronald G. Ross jest autorem lub współautorem wielu opracowań na temat modeli pojęciowych i zarządzania wiedzą . Jest także współzałożycielem Business Rule Solution LLC, oraz współtwórcą specyfikacji i notacji SBVR . Książka Najnowsze z powyższych opracowań to rodzaj podsumowania pewnej części dorobku autora. Modele pojęciowe są często mylone z projektowaniem relacyjnego modelu danych, a bywa gorzej, gdy są utożsamiane z "modelem dziedziny systemu" w projektach dotyczących tworzenia aplikacji określanych jako"obiektowe". Książka traktuje o modelach pojęciowych, i autor definiuje je jako: model pojęciowy: uporządkowany zbiór pojęć i związków…
Wprowadzenie W toku niejednej analizy można spotkać się z sytuacją gdy standardowe podejście polegające na badaniu dokumentów i analizie zstępującej (od ogółu do szczegółu, ang. top-down) może być trudne lub wręcz nie możliwe. Dotyczy to analizy systemów słabo udokumentowanych lub wręcz nieudokumentowanych, gdzie jedyne dostępne dane to obserwacja lub relacja obserwatora (uczestnika, itp. czyli relacja z drugiej ręki). Jest to sytuacja podobna to serii (pakietu) zebranych "user story" (w nomenklaturze metodyk zwinnych historyjki użytkownika), nieformalnych relacji. Jak ugryźć taką sytuację? UML i obiekty czyli instancje klas Z pomocą przychodzi pojęcie…
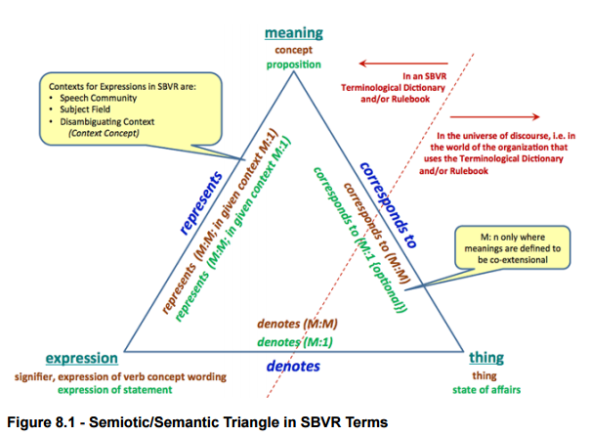
O analizie pojęciowej pisałem nie raz, chyba pierwszy raz w krótkim artykule Analityk biznesowy czyli wyplenić dwuznaczność z dokumentów analitycznych. Niestety nadal problemem większości dokumentów, takich jak analizy i specyfikacje, jest ich niespójność i niejednoznaczność. W niedawnym artykule SBVR czyli reguły biznesowe i słownik pisałem o diagramie faktów, o regułach i o słowniku pojęć, dzisiaj co nieco o pojęciach (tych ze słownika pojęć ;)). Ostatnia wersja specyfikacji SBVR v.1.3. z maja tego roku, zawiera rozszerzony rozdział: 8 Linguistic Foundations, 8.1 Things, Meanings, and Expressions, 8.1.1 Semiotic/Semantic Triangle in SBVR Terms rozpoczynający się tak: This sub…
Tak więc, warto rozważyć stosowanie reguł biznesowych i słowników pojęć (Semantics Of Business Vocabulary And Rules), gdyż jest to sprawdzona i bardzo przydatna technika analizy i dokumentowania logiki biznesowej. Polecam także stronę The Business Rules Group i zamieszczony tam Manifest Reguł Biznesowych. Tworzenie monstrualnych dokumentów wymagań, zawierających dziesiątki razy powielane "walidacje" prowadzi do wielu kłopotów z utrzymaniem spójności i kompletności takich specyfikacji. Pomijam już ich uciążliwą objętość. Jako materiał dla programisty są one wtedy trudne w użyciu, do tego skłaniają do najgorszych praktyk, jakimi jest między innymi umieszczanie logiki biznesowej w kodzie formatek ekranowych.
I tu dochodzimy do sedna: aby stworzyć profil notacji - co czasami bywa niezbędne dla jakości analizy - należy zbudować słownik pojęć z dziedziny analizowanego problemu. Bez takiego słownika analiza może być niewykonywalna, albo jej jakość będzie bardzo niska - czytaj użycie jej wyników będzie bardzo ryzykowne.
Na konferencjach i forach toczą się stale dyskusje na ten temat. Większość firm doradczych, informatycznych i ich analitycy bronią tezy, że celem analizy jest zebranie informacji w postaci dokumentów i zestawień. Niestety takie dokumenty są kompletnie nieprzydatne, mają wartość nagrania (patrz wyżej zdjęcie lotnicze), nie da się na ich postawie wyciągać żadnych pozwalających na dowodzenie ich słuszności, wniosków nie licząc może oceny estetyki edytorskiej. Niewątpliwą "zaletą takiej analizy" jest to, że nie wymaga ona absolutnie żadnych kompetencji poza umiejętnością komunikacji. Takim analitykiem może być niemalże każdy (łatwa rekrutacja, niski koszt), ale czy taki jest cel analiz poprzedzających projekty, warte setki tysięcy złotych a nie raz miliony?Na zakończenie dodam, że najgorszym sposobem jaki znam i jaki niestety często spotykam, na modelowanie struktury organizacyjnej, jest użycie diagramu klas lub diagramu przypadków użycia i modelowanie z zastosowaniem dziedziczenia (klas lub aktorów).

Słownik pojęć (często występuje w dokumentach jako czysto polskie słowo glossariusz ;)) bywa często przedmiotem burzliwych negocjacji, bo nie raz (a w zasadzie zawsze ;)) biznes stosuje slang, w którym to samo słowo ma różne znaczenie, zależnie od kontekstu użycia. Może to mieć sens w języku mówionym gdy pełna treść wypowiedzi daje ten kontekst, ale na poziomie analizy i projektu każde pojęcie musi mieć jedno unikalne znacznie mimo braku kontekstu (tym bardziej, że np. nazwy klas nie są elementami pełnych zdań ani opowieści :)).[...] Biznes także musi zrozumieć, że ma dwa różne elementy opisu swoich działań: praca z dokumentami i tworzenie dokumentów. Jednak uznanie tego faktu to jedno, nie wierzę w to, że biznes się tego nauczy, bo nie nauczył się formalnego opisu lub modelowania procesów podczas wdrożeń ISO, jednak uważam, że biznes nie ma takiej potrzeby. Moim zdaniem od dobrego analityka nie ma ucieczki, to inna kompetencja. Nie ma ucieczki od projektantów mody mimo istnienia kobiet chcących mieć ładne sukienki i bardzo dobrych krawców. Nikt tu nikogo nie zastąpi.

Wiele firm ma problemy zarządcze nie dlatego, że są źle zarządzane, ale dlatego, że stopień złożoności tych firm jest zbyt duży by podejmować je na wyczucie. W obecnych czasach decyzje muszą być podejmowane w relatywnie krótkim czasie bo rynek nie czeka, jednak jakość tych decyzji nie powinna być zła. Dlaczego bywa zła? Bo decyzje są nie raz podejmowane z niepełnym zrozumieniem sytuacji. Podejmowana decyzja, by była możliwie najlepsza, wymaga pełnego zrozumienia, tego czego dotyczy (co chyba nie jest dziwne). Jeżeli dotyczy firmy, nie powinno się podejmować decyzji bez pełnego zrozumienia potencjalnego wpływu tej decyzji na firmę. W przeciwnym wypadku skutki są dość losowe, czyli nie zarządzamy a staramy się zarządzać.[...] Analiza biznesowa organizacji poprzedzająca np. wdrożenie nowego oprogramowania, powinna polegać na wykonaniu audytu i uporządkowaniu reguł decyzyjnych oraz opracowaniu modeli procesów biznesowych by je zweryfikować. Drugi krok to ocena, jakiej wiedzy oczekujemy od ludzi (ich umiejętności i wiedza). Dokumentujemy ją z obawy przed "błędem ludzkim". Tu zwracam uwagę na to, że wymaganiem na oprogramowanie może być tablica decyzyjna, jeżeli planujemy automatyzację jakiejś czynności. Proces biznesowy nie jest wymaganiem, to co najwyżej kontekst wykonywanych czynności.

Model organizacji to: opis motywacji jej działania, opis ludzi, jacy realizują wewnętrzne zadania, opis reguł jakie regulują ich zachowaniami. Całość (model) powinna być na tyle uporządkowana, by model był w 100% jednoznaczny, czyli kluczowe pojęcia w nim użyte powinny być zebrane w jeden wewnętrzny, spójny biznesowy słownik tej organizacji. To wszystko dopiero pozwoli stworzyć model procesów biznesowych, czyli wewnętrzne scenariusze zachowania.Samo utworzenie map (bo nie modeli) w postaci diagramów procesów z pomocą wywiadów, sesji warsztatowych i obserwacji, da produkt podobny do zdjęcia lotniczego rzeki: wiemy którędy płynie, ale kompletnie nie rozumiemy dlaczego akurat tak. Mamy jedynie udokumentowany stan obecny.Ingerencja w ten stan rzeczy, bez zrozumienia reguł rządzących tym jak i którędy płynie woda, kończy się nie raz katastrofami jakie znamy z doniesień o powodziach i zalaniach ostatnich lat. Bez poznania zasad rządzących zachowaniem się organizacji można "nie uniknąć problemów przy wprowadzaniu zmian".Każda reorganizacja, a w szczególności jest nią wdrażanie nowego oprogramowania, jest taką zmianą. Ta książka jest o modelowaniu organizacji.

Stosowanie opisanych tu formalizmów to uznanie, że dobre i sprawdzone standardy pozwalają zminimalizować ryzyko projektów analitycznych.Analiza to nie zbieranie danych o firmie i ich sortowanie, bo czy to nie brzmi jak ekologiczne zbieranie śmieci? Analiza to porządkowanie zebranej wiedzy o organizacji, korzystając z wypracowanych systemów pojęciowych, czyli przyporządkowywanie wszystkiego co wiemy do skończonej liczby pojęć, oraz uzupełnianie lub naprawianie wszystkiego czego zabranie w tak opracowanym modelu. Kluczem dobrej analizy jest uogólnianie czyli wychwytywanie rzeczy istotnych oraz odsiewanie informacji zbędnych, nie mających wpływu na cel projektu a zaciemniających go. Analiza to odkrywanie i rozumienie reguł, panowanie nad złożonością organizacji.Większość projektów takich jak np. wdrażanie nowych metod kontrolingu, zrównoważonej karty wyników, nowych systemów IT itp. cierpi głównie z powodu posiadania nadmiaru informacji z jednej strony i kompletnego jej niezrozumienia z drugiej. Sławne już w badaniach "złe i niekompletne wymagania" czy "zmiany zakresu projektu w trakcie jego trwania" to klasyczne skutki złej (a często pomijania!) analizy biznesowej. Koszty tych porażek wielokrotnie przewyższają koszt takich analiz.