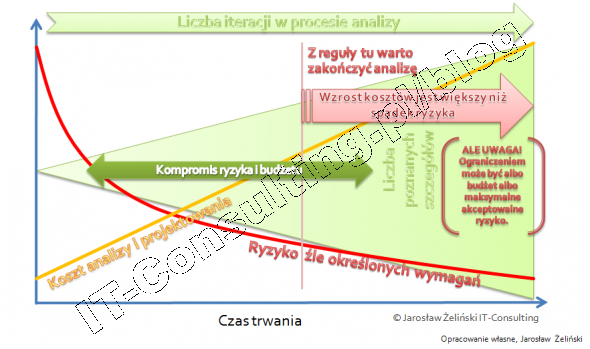
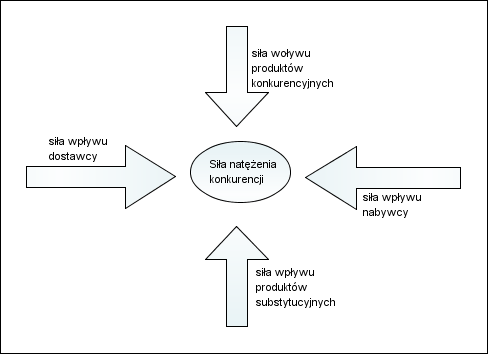
Wdrożenie nowego oprogramowania, jeżeli ma mieć sens, powinno więc wspierać tworzenie dodatkowego zysku lub przychodu, w przeciwnym wypadku w zasadzie nie ma sensu. Innym powodem może być ratowanie posiadanego już przychodu czyli utrzymania się na rynku.Dodatkowy zysk, to efekt obniżania kosztów. Ratowanie posiadanego rynku, to efekt reakcji na siły rynku: siły dostawcy (np. jego system EDI wymusza inwestycje u nas), siły odbiorcy (oczekuje obsługi podobnej do tej, jaką oferuje konkurencja), siły konkurencji (ich produkty i usługi są wyższej jakości, musimy też zainwestować).Powyższy model obrazuje to co ma wpływ na to Dlaczego zarabiamy. Zbudowanie takiego modelu dla konkretnej firmy, zrozumienie Dlaczego zarabia, pozwala szukać sposobu i miejsc mogących przyczynić się do realizacji celu projektu, jednak cel ten należy wcześniej Nazwać. Drugi krok to ocena możliwości realizacji i prognozowanie skutków, by określić cel: miarę i wielkość tego co chcemy osiągnąć by wiedzieć czy się udało.PodsumowanieModel biznesowy moim zdanie nie odnosi się do procesów biznesowych, to procesy biznesowe są konsekwencją modelu biznesowego. Dlaczego? Bo jeśli przyjmiemy, że model biznesowy obrazuje (dokumentuje) źródła zysku firmy w łańcuchu wartości na rynku, to procesy biznesowe są opisem tego, w jaki sposób ta wartość wewnątrz firmy powstaje. To pozwala dopiero wskazać jakie działania (procesy) wesprzeć i jak, by "ulepszyć" firmę. Dlatego brak modelu biznesowego jest poważnym utrudnieniem analizy wymagań... bo czego wymagać od oprogramowania skoro nie wiemy co i jak pomoże w zarządzaniu firmą?