Zapraszam wszystkich, którzy szukają pomocy, wiedzy oraz wsparcia w swoich projektach informatyzacji. Działam od 1991 roku, mój Blog działa nieprzerwanie od 1998 roku.
Jeżeli nie potrafisz czegoś narysować to znaczy że nadal tego nie rozumiesz. Jeżeli potrafisz coś narysować to potrafisz to także zbudować.
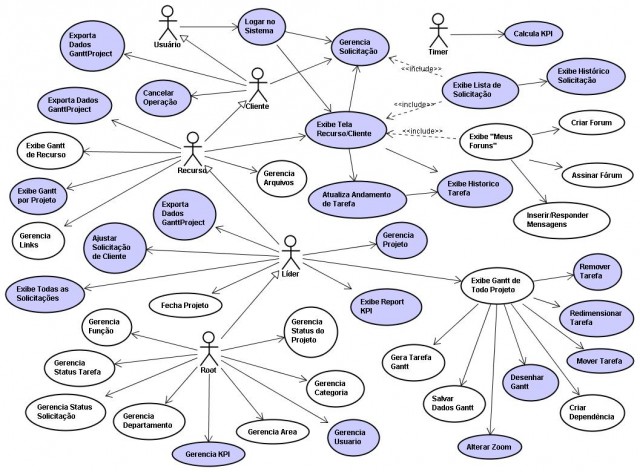
Wprowadzenie Jest to diagram, który na równi z Diagramem Klas, budzi bardzo często ogromne problemy interpretacyjne (patrz: Diagram klas...). Bardzo wielu autorów przypisuje temu diagramowi role, których on nie pełni, a nie raz prezentowane w sieci i literaturze przykłady są niepoprawne. Znakomita większość autorów tych diagramów używa ich jako "zbioru możliwych kliknięć" co jest całkowitym niezrozumieniem celu użycia i idei tego diagramu. Nawet jeżeli ktoś potrzebuje takiej mapy klikania, to są do tego lepszych narzędzia i metody (przykład: Mapa ekranów aplikacji ? podstawa dobrego UX/UI design). Tworzenie niezgodnych z notacją…
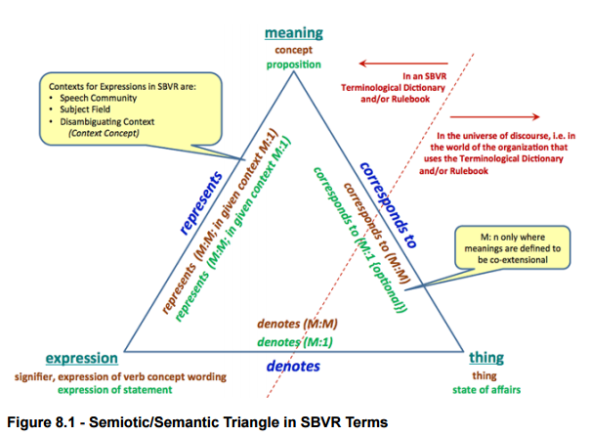
Ronald G. Ross Ronald G. Ross jest autorem lub współautorem wielu opracowań na temat modeli pojęciowych i zarządzania wiedzą . Jest także współzałożycielem Business Rule Solution LLC, oraz współtwórcą specyfikacji i notacji SBVR . Książka Najnowsze z powyższych opracowań to rodzaj podsumowania pewnej części dorobku autora. Modele pojęciowe są często mylone z projektowaniem relacyjnego modelu danych, a bywa gorzej, gdy są utożsamiane z "modelem dziedziny systemu" w projektach dotyczących tworzenia aplikacji określanych jako"obiektowe". Książka traktuje o modelach pojęciowych, i autor definiuje je jako: model pojęciowy: uporządkowany zbiór pojęć i związków…
This time a short article about an interesting construction. It was described by Rebecca Wirfs-Brock in 1999 (Miller & Wirfs-Brock, 1999) . The idea did not gain much popularity at the time, but now, in the era of patterns based on microservices and micro applications, it has a chance to come back into favour. I've been using it for a long time (see interface-oriented design). The abbreviations HLD and LLD are High-Level Design and Low-Level Design, respectively. These are the levels of abstraction in the PIM model. It is also a description of the design style of an interface-oriented system architecture (interface-oriented architecture).
Wstęp Od lat spotykam się w literaturze z zakresu zarządzania, z krytyką poczty elektronicznej jako narzędziem zarządzania czymkolwiek (patrz: Sabotaż...2013). Poczta elektroniczna (podobnie jak pakiety biurowe w ogóle) jest typowym przykładem maksymy: ułatwienie nie zawsze jest ulepszeniem. W kliencie poczty elektronicznej zarówno treść jak i sposób adresowania (co i do kogo, kopia, itp.) nie podlega żadnej standaryzacji ani restrykcji (poczta elektroniczna często służy do wyprowadzania danych z firmy). Jak dodać do tego fakt, że załączniki są niewidoczne w narzędziach do lokalnego wyszukiwania, że mamy na serwerach filtry antyspamowe których reguły…
Zostałem niedawno zapytany czy pomogę bo “mamy już ponad 150 przypadków użycia w dokumentacji…”. Myślę sobie, to niemożliwe, nie ma tak wielkich systemów (wycena okazała się w efekcie pięciokrotnie zawyżona tylko dlatego, że użyto metody zorientowanej na “user story”).
W artykule o aplikacjach webowych, ponad rok temu, pisałem:
Generalnie kluczową cechą micro-serwisów, czyniącą z nich tak zwaną zwinną architekturę, jest całkowita wzajemna niezależność implementacji poszczególnych usług aplikacyjnych. (źr.: Aplikacje webowe i mikroserwisy czyli architektura systemów webowych).
Przy innej okazji pisałem o wzorcach:
Wzorce projektowe to bardzo ważna część ??zawodu? analityka i architekta oprogramowania. […] Generalnie wzorce są to skatalogowane standardy i dobre praktyki . (Obiektowe wzorce projektowe )
Szkolenia dla analityków poprzedzam ankietami przed szkoleniowymi, jak do tej pory żadna nie zawierała pytań o wzorce projektowe: ani tego że są używane ani tego, że są celem szkolenia, niemalże każdy deklaruje albo, że używa UML lub, że chce zacząć używać UML, nawet gdy są to programiści. Zauważyłem, że wzorce projektowe w świadomości analizy biznesowej i projektowania (OOAD) “nie istnieją”. Wśród programistów, jeżeli jest spotykana, to wiedza o wzorcach przydatnych w tworzeniu bibliotek i narzędzi, często też powielane są wyuczone stare i złe praktyki programistyczne rodem z lat 60-tych (np. praktyki SmallTalk, patrz dalej).
Niedawno napisał do mnie czytelnik pod jednym z artykułów:
Załóżmy, że realizujemy proces biznesowy: zarządzanie kursami walut. W ramach procesu pracownik musi przygotować plik csv zawierający wyłącznie listę słownikową par walut (np. usdpln, eurpln, eurusd). Nazwa pliku to np bieżącą data. Następnie systemX łączy się z API zewnętrznej platformy i pobiera tabele kursów tych par walut (aktualne i historyczne miesiąc wstecz) i wystawia plik xls zawierający dane: nazwa pary walut, data kursu, wartość kursy) Plik ten system X wysyła do szyby ESB. Szyna przesyła ten plik do systemuY. SystemY wykorzystuje te dane do wyznaczenia wewnętrznych kursów walut wg. ustalonego modelu matematycznego. Wynik obliczeń odkładany jest w bazie danych tego systemu. Na końcu procesu jest pracownik, który wykorzystuje te informacje za pośrednictwem SystemuZ. Wybiera parę walut, określa datę i system zwraca mu wewnętrzny kurs wyznaczony przez SystemY. Technicznie odbywa się poprzez odpytanie systemu Y poprzez jego API. Czyli mamy SystemX, SystemY, SystemZ, pracownika, szynę, plik csv, plix xls, 2XAPI no i przepływ danych (najpierw plików, potem poszczególnych atrybutów) . I jak to wszystkim pokazać żeby było czytelne? (źr.: : Model pojęciowy, model danych, model dziedziny systemu)
Prawdę mówiąc, mniej więcej w takiej formie dostaje materiały od moich klientów.. ;). Co możemy zrobić? Pomyślałem, że dobry reprezentatywny przykład pomoże. Popatrzmy…
W toku szkoleń, a także audytów, powstają nie raz spory o interpretacje znaczenia symboli notacji: ich semantyki i syntaktyki (co oznaczają i jak je można łączyć z innymi). Dzisiaj o dość częstym sporze czyli bramki OR (inclusive) i XOR (exclusive) w notacji BPMN oraz o tym, że z 380 stron specyfikacji BPMN, w modelach analitycznych stosujemy tylko niecałe 40 stron rozdziału 7., pozostałe rozdziały służą wyłącznie lepszemu zrozumieniu teorii i modelom wykonywalnym. Czyli dlaczego w analizach stosujemy kilka, a nie kilkadziesiąt symboli notacji BPMN.
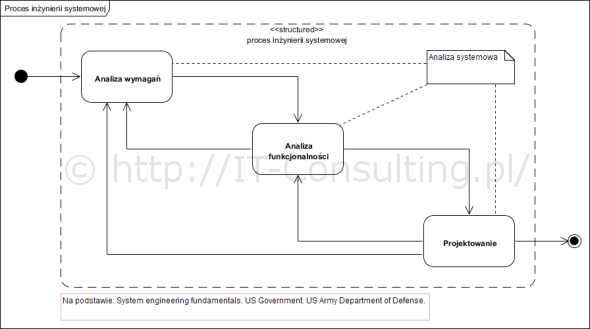
Od czasu do czasu jestem pytany o to, kiedy używać diagramu aktywności UML. Od 2015 roku specyfikacja UML wskazuje, że diagramy te są narzędziem modelowania metod czyli logiki kodu (dla Platform Independent Model): aktywności (activities) to nazwy metod, zadania/kroki (actions) to elementy kodu (przykłady w dalszej części).
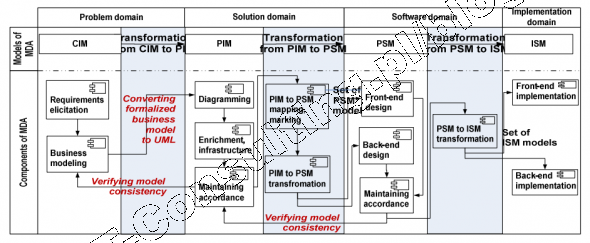
Gdy powstawał UML, diagramy aktywności były używane także do modelowanie procesów biznesowych. W roku 2004 opublikowano specyfikację notacji BPMN, która w zasadzie do roku 2015 “przejęła” po UML funkcję narzędzia modelowania procesów biznesowych. W 2015 roku formalnie opublikowano specyfikację UML 2.5, gdzie generalnie zrezygnowano z używania UML do modeli CIM. Obecnie Mamy ustabilizowaną sytuację w literaturze przedmiotu: BPMN wykorzystujemy w modelach CIM (modele biznesowe), UML w modelach PIM i PSM jako modele oprogramowania (a modele systemów: SysML, profil UML).
Na przełomie lat 80/90-tych rozpoczęto prace nad standaryzację notacji modelowania obiektowego, w 1994 opublikowano UML 0.9, w 2001 roku pojawiają się pierwsze publikacje o pracach nad notacją BPMN, jednocześnie pojawia się Agile Manifesto, od 2004 roku ma miejsce spadek zainteresowania dokumentowaniem projektów programistycznych, w 2004 rok publikowano specyfkację BPMN 1.0, od tego roku ma miejsce wzrost zainteresowania modelowaniem procesów biznesowych, powoli stabilizuje się obszar zastosowania notacji UML. W 2015 roku opublikowano UML 2.5, stosowanie analizy (CIM) i i projektowania (PIM), jako etapu poprzedzającego implementacje, stało się standardem (źr. wykresu: Google Ngram).
Tak więc obecnie:
Nie używamy diagramów aktywności do modelowania procesów biznesowych. Do tego służy notacja BPMN!
Diagram aktywności może być modelem kodu na wysokim lub niskim poziomie abstrakcji, operujemy wtedy odpowiednio aktywnościami (activity) lub działaniami (actions). Te ostatnie to w zasadzie reprezentacja poleceń programu.
Nie ma czegoś takiego jak “proces systemowy”, oprogramowanie realizuje “procedury”.
Projektując oprogramowanie zgodnie ze SPEM , powstaje Platform Independent Model. W praktyce już na tym etapie programujemy, bo tworzymy logikę i obraz przyszłego kodu. Taka forma dokumentowania pozwala także lepiej chronic wartości intelektualne zamawiającego.
Tym razem artykuł adresowany do zaawansowanych analityków.
Ta specyfikacja (SPEM) jest datowana na 2008 rok. Stanowi sobą tło dla MDA oraz uzasadnia wzorce projektowane oparte na przypadkach użycia (mikroserwisy, Use Case 2.0, inne podobne). Podstawowa różnica między specyfikacją SPEM a specyfikacją UML polega na tym, że UML to profile MOF stanowiące opisy notacji i systemów pojęciowych. SPEM to metamodel procesu wytwórczego oprogramowania czyli generalne zasady budowania procesów wytwarzania i dostarczania oprogramowania.
Wprowadzenie W 2019 opisałem swoistą próbę rewitalizacji wzorca BCE (Boundary, Control, Entity). Po wielu latach używania tego wzorca i dwóch latach prób jego rewitalizacji uznałem jednak, że Zarzucam prace nad wzorcem BCE. Podstawowy powód to bogata literatura i utrwalone znaczenia pojęć opisujących ten wzorzec. Co do zasady redefiniowanie utrwalonych pojęć nie wnosi niczego do nauki. Moja publikacja zawierająca także opis tego wzorca bazowała na pierwotnych znaczeniach pojęć Boundary, Control, Entity. Sprawiły one jednak nieco problemu w kolejnej publikacji na temat dokumentów . Dlatego w modelu pojęciowym opisującym role komponentów przyjąłem następujące bazowe stwierdzenie:…
Dane niestrukturalne stanowią ponad 80% składowanych danych, to oznacza, że model relacyjny pozwala opisać i przetwarzać tylko ułamek posiadanej informacji (UNSTRUCTURED DATA AND THE 80 PERCENT RULE) Wstęp W podsumowaniu niedawnego artykułu o NoSQL w chmurze, napisałem: Problem projektowania struktur dokumentów, także w bazach dokumentowych, to osobne i trudne zagadnienie. Opisałem go w najnowszym artykule, który ukaże się za niedługo w wydawnictwie IGI Global: Emerging Challenges, Solutions, and Best Practices for Digital Enterprise Transformation. (Repozytorium w chmurze - NoSQL - Jarosław Żeliński IT-Consulting - Systemy Informacyjne) Artykuł sie właśnie ukazał. We wstępie napisałem: Dokumenty…