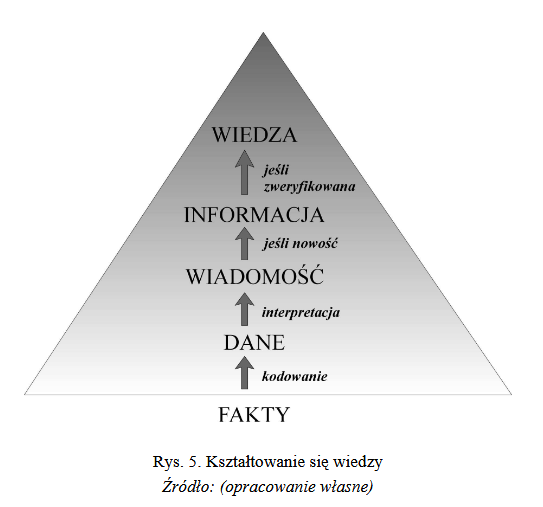
Wprowadzenie Nie raz tu już pisałem, że analizy i projekty związane bezpośrednio z wymaganiami na oprogramowanie to "tylko" ok. 3/4 moich projektów. Jednak nawet, jeżeli projekt nie jest "nazwany" informatycznym, to zawsze jest "informacyjny" w rozumieniu zarządzania informacją (także zarządzanie wiedzą). Tym razem kilka słów na temat dokumentów. Stanowią one podstawową jednostkę informacji (i danych) w każdym systemie biznesowym. Są także źródłem danych dla hurtowni danych. Wiele projektów związanych z dokumentami jest sprowadzanych do problemu: "jakie mamy dokumenty i co z nimi robimy?" Zaniedbuje się bardzo ważny element: odpowiedź na…
Tak więc kim jest CIO? Czym jest IT? W naszym języku utrwaliło się I jako informatyka (technologia), w języku angielskim I oznacza informację. Jeżeli CIO ma brać udział w tworzeniu strategi, moim zdaniem musi zostać wyniesiony do poziomu zarządu i zarządzać informacją a nie tylko informatyką czyli pewnym wycinkiem informacji. Czy to, CIO w zarządzie, się komuś uda? Jeżeli nie, to CIO będzie tylko zarządcą zasobów IT, najważniejszych ale jednak jednych z wielu w organizacji.

Wiele firm ma problemy zarządcze nie dlatego, że są źle zarządzane, ale dlatego, że stopień złożoności tych firm jest zbyt duży by podejmować je na wyczucie. W obecnych czasach decyzje muszą być podejmowane w relatywnie krótkim czasie bo rynek nie czeka, jednak jakość tych decyzji nie powinna być zła. Dlaczego bywa zła? Bo decyzje są nie raz podejmowane z niepełnym zrozumieniem sytuacji. Podejmowana decyzja, by była możliwie najlepsza, wymaga pełnego zrozumienia, tego czego dotyczy (co chyba nie jest dziwne). Jeżeli dotyczy firmy, nie powinno się podejmować decyzji bez pełnego zrozumienia potencjalnego wpływu tej decyzji na firmę. W przeciwnym wypadku skutki są dość losowe, czyli nie zarządzamy a staramy się zarządzać.[...] Analiza biznesowa organizacji poprzedzająca np. wdrożenie nowego oprogramowania, powinna polegać na wykonaniu audytu i uporządkowaniu reguł decyzyjnych oraz opracowaniu modeli procesów biznesowych by je zweryfikować. Drugi krok to ocena, jakiej wiedzy oczekujemy od ludzi (ich umiejętności i wiedza). Dokumentujemy ją z obawy przed "błędem ludzkim". Tu zwracam uwagę na to, że wymaganiem na oprogramowanie może być tablica decyzyjna, jeżeli planujemy automatyzację jakiejś czynności. Proces biznesowy nie jest wymaganiem, to co najwyżej kontekst wykonywanych czynności.

Warto tworzyć dobrze przemyślane systemy metadanych dla systemów archiwizacji gdyż pozwala to z jednej strony "spiąć" archiwum dokumentów z hurtownią danych z drugiej "pozbyć się" śmieci. Tempo przyrostu danych stale rośnie gdyż biznesowe oprogramowanie, automatyzując wiele naszych czynności, wytwarza je w tempie w jakim człowiek nigdy nie był by w stanie. Po drugie narasta zjawisko powielania, co nazywam to syndromem "copy&paste". Wiele dokumentów (o zgrozo także tych podobno "autorskich") i powstaje coraz częściej metodą powielania tego co znajdzie się w firmowych archiwach (wiedza korporacyjna czyli po prostu jej zanik, bo wiedza to umiejętność napisania czegoś a nie skopiowania) czy w sieci.
Moja praktyka (to co dostaje do audytu u klientów) pokazuje, że dokumenty wytworzone "od zera" praktycznie zawsze mają większą wartość merytoryczną. Do tego dochodzi ryzyko przeniesienia, podczas kopiowania, treści niechcianych. Kopiując dziesiątki stron "starej oferty" lub poprzedniego "opracowania doradczego", tworząc kolejne "indywidualne autorskie opracowanie" narazić się można nie tylko na ujawnienie tajemnicy ale także na zwykłe ośmieszenie. Dlatego system zarządzania dokumentami i wiedzą należy dobrze zaprojektować. W przeciwnym wypadku narażamy się na budowę wielkiego śmietnika.
Mamy przyjemność zaprosić Państwa na II edycję bezpłatnej konferencji, która jest szansą na uzyskanie lepszych wyników i przewagi nad konkurencją. Konferencję Knowledge Management ? systemy wspomagające zarządzanie wiedzą GigaCon kierujemy do osób decydujących o sposobie funkcjonowania przedsiębiorstwa, odpowiedzialnych za zarządzanie przepływem informacji, zarządzanie wiedzą oraz dobór rozwiązań i technologii służących wspieraniu tych procesów; osób odpowiedzialnych za optymalne wykorzystanie posiadanych zasobów wiedzy. Tematyka konferencji: - Systemy zarządzania dokumentami (document management) - Systemy obiegu pracy (workflow) - Systemy wspomagania pracy grupowej (groupware) - Hurtownie danych (data warehouse) - Portale korporacyjne (enterprise portals)…
Tak więc moim zdaniem zarządzanie wiedzą to nie tylko jej gromadzenie i udostępnianie, ale przede wszystkim selekcja! Nasz mózg robi dokładnie to samo: zapomina o wszystkim co nie jest bezpośrednio używane do bieżącego życia i przeżycia.Na pewno nie jest to miejsce na streszczanie takich konferencji ale w jednej z prezentacji pojawiło się ważne stwierdzenie: retencja danych (gromadzenie ich, tu w kontekście wiedzy należy rozumieć: celowo, wybiórczo i w kontrolowany sposób). Jest to moim zdaniem druga najważniejsza cecha systemów zarządzania wiedzą (pierwszą była powiązana z tym pojęciem selekcja danych).