Dość często spotykam sie z tezami, że użycie przypadków użycia nie wymaga modelowania procesów i odwrotnie, albo że są to “narzędzia” oferujące podobne lub takie same korzyści, np. tak jak tu:
So, as you can see we used different techniques and basically the result is the same. It was not really important what techniques were used unless solution design is complete. It?s just a matter of a habit so if you?re more comfortable with use cases then stick to them or if you?re more familiar with process maps then draw a map. But note that in some cases you may be requested to use a specific technique that is a corporate standard or because there is an agreement that all BAs on the project will use one template (technique) for consistency. (Źródło: Use cases or business process maps, what technique to use?)
Sugeruję najpierw zapoznać się z cytowanym powyżej tekstem a po zapoznaniu się z nim zapraszam do dalszej lektury. Jak się komuś nie chce powyższego czytać, może potraktować mój tekst jak zwykły post a nie jak polemikę ;).
Zacznę od modelu procesów w BPMN jaki prezentuje jego autor;
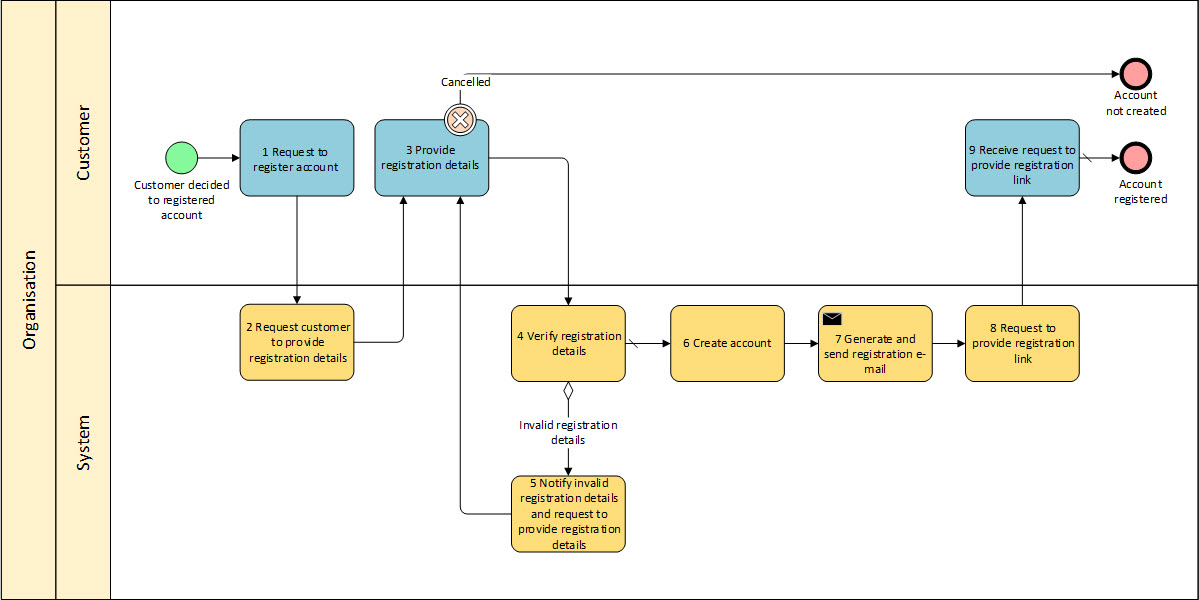
Pierwsza rzecz: co do zasady Klient i Podmiot go obsługujący to dwa odrębne podmioty więc diagram ten powinien zawierać dwie pule, a nie jedną wspólną pulę (albo jak kto woli baseny). Dalej. BPMN w specyfikacji traktuje tory wyłącznie jak uniwersalne elementy grupujące (nie są one jednak eksportowane do plików wymiany XPBL czy BPEL4WS), nie ma zakazu stosowanie torów do reprezentowania “systemów”, model biznesowy CIM (definicja MDA) zakazuje. Od siebie dodam, że to czym będą tory należy zdefiniować na początku analizy (i powinna to być jedna spójna definicja).
Autor powyższego diagramu na jednym diagramie pokazał wszystko co wie, łamiąc notacyjne zasady stosowani puli (basenu) oraz dobre praktyki nie mieszania różnych kontekstów na jednym modelu.
Model procesu powinien mieć zawsze konkretny kontekst i być osadzony w jakiejś metodyce, bez tego trudno podjąć decyzję, które informacje są istotne i jakie detale pokazywać (bo notacje są nadmiarowe i nie są metodyką). Bez tego także trudno innej osobie taki diagram jednoznacznie zinterpretować. Najgorsze wyjście to “nie wiem, więc pokaże wszystko co wiem” z czym tu mamy moim zdaniem do czynienia.
Jak to robić? Przyjmuję postępowanie zgodne MDA/MDE (pisałem tu o tym nie raz), więc najpierw tworzymy model CIM (Computation Independent Model), którego celem jest zrozumienie i udokumentowanie mechanizmu – tu – rejestracji konta, typowy mechanizm opt-in:
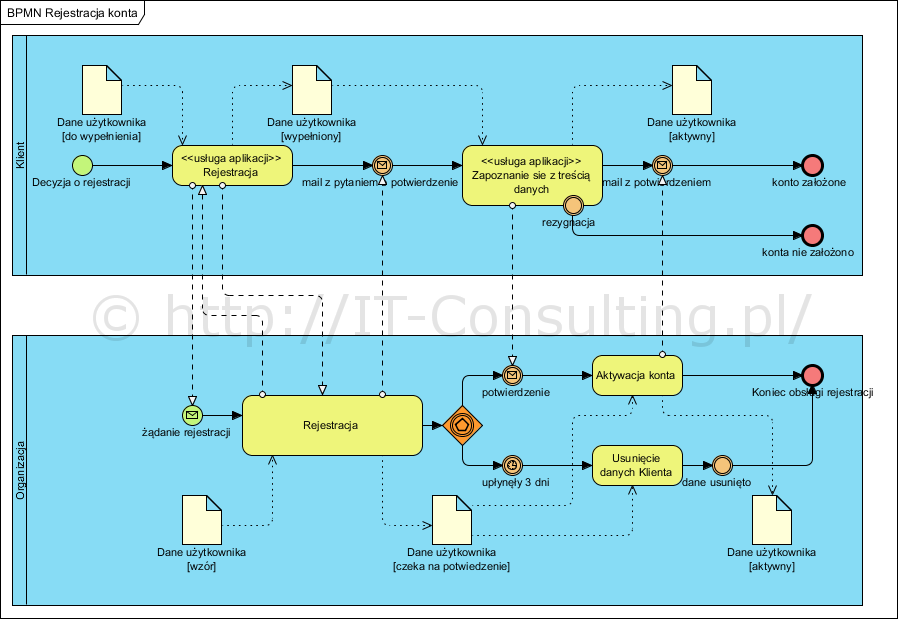
Co do zasady aktywność w procesie to coś co stanowi kompletnie wykonaną pracę (bo proces to aktywność przekształcająca wejście w wyjście), więc dzielenie jej na kawałki nie ma żadnego uzasadnienia. Detale aktywności pokazujemy na odrębnym diagramie, a częściej jako zapisaną tekstem procedurę (jest niepodzielna bo aktywność jest jedna). Np. aktywność Rejestracja po stronie (w puli) Klienta to:
- inicjacja rejestracji konta
- SYSTEM wyświetla formularz Dane użytkownika
- wypełnienie pól formularza i potwierdzenie
- jeżeli
- dane są poprawne – SYSTEM potwierdza przyjęcie danych
- dane są niepoprawne – SYSTEM prezentuje formularz Dane użytkownika i wyświetla komunikat (lub idź do punkt 2.)
- (koniec)
(czasami dodaję pseudo krok procedury koniec aby czytelnik miał pewność, że to ukończona praca).
Po stronie (w puli) Organizacji zainicjowane żądanie rejestracji spowoduje obsługę pierwszego dialogu z Klientem, tu ostatnim krokiem procedury jest wysłanie monitu mailem. Następnie Organizacja czeka, jeżeli dostanie potwierdzenie to aktywuje konto Klienta, zaś po trzech dniach bezczynności, Dane użytkownika zostaną usunięte, i proces rejestracji zostanie uznany za zakończony (tu niepowodzeniem).
Na tym etapie prac wiemy co i jak Organizacja robi w przypadku rejestracji Klienta. Cały ten ambaras jednak do czegoś służy, służy do udostępniania Klientowi możliwości składania zamówień i danych o stanie jego rozrachunków. W przykładzie mamy diagram przypadków użycia, więc i ja pójdę tym tropem (zakres projektowania).
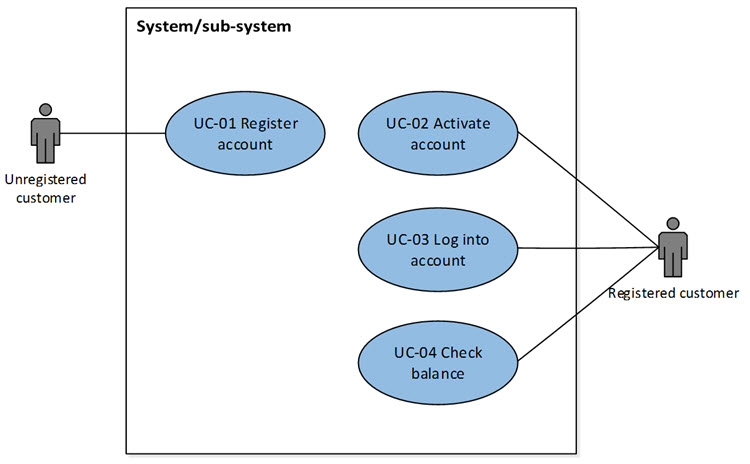
Mamy tu cztery przypadki użycia. Skąd? O tym dalej. Pisałem już wcześniej o transformacji z modelu BPMN na model Przypadków użycia. Tu pokaże efekt końcowy.
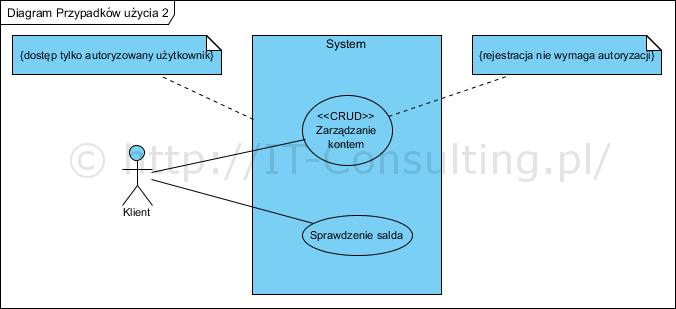
Dlaczego tak?
Przede wszystkim logowanie (wbrew wielu przykładom w sieci) nie jest przypadkiem użycia, czyli nie jest usługą aplikacji, jest cechą środowiska, jednym z wielu sposobów autoryzowania użytkownika do pracy (inne to LDAP, Activedirectory, odcisk palca, itp., jest to metoda realizacji wymagania pozafunkcjonalnego o niedopuszczaniu do korzystania z usług aplikacji nieautoryzowanych osób). Nie jest dobrym pomysłem uznawanie takich czynności jako usług aplikacji (kto kupi coś co służy wyłącznie do logowani się?)
Mamy tu przypadek użycia Zarządzanie kontem. Jest to usługa polegająca na tworzeniu, aktualizacji, podglądzie lub usunięciu danych użytkownika (standardowo oznacza sie takie usługi CRUD, ang. Create, Retrieve, Update, Delete, są to rejestry pozbawione dziedzinowej logiki biznesowej, kontrolujemy wyłącznie poprawność samych pól). Korzysta z niej Klient, pierwsze użycie (kontekst Create) to nic innego jak rejestracja w systemie, każde kolejne użycie to będzie kolejna aktualizacja danych (kontekst Update) lub ostatecznie polecenie ich usunięcia (kontekst Delete).
Scenariusz rejestracji, opisany wcześniej, wyglądał by tak:
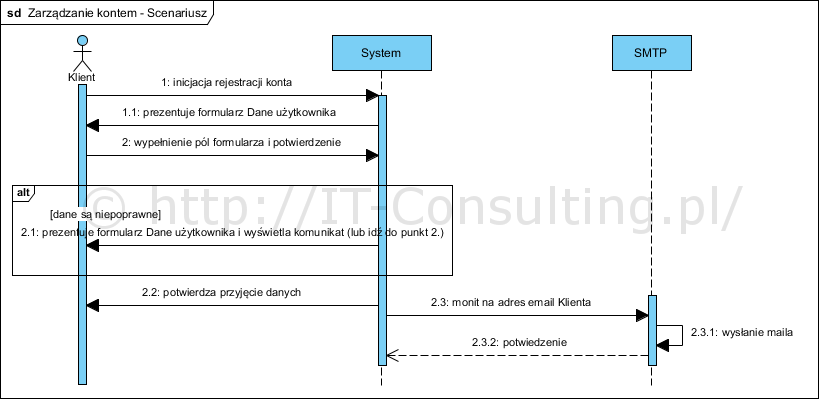
To tu są pokazane (udokumentowane) kolejne kroki realizowane przez projektowany System. W tym przypadku cały proces samoobsługi Klienta (zarządzanie danymi o sobie) został zautomatyzowany (czyli nie robią tego już pracownicy Organizacji a aplikacja). W efekcie model procesu biznesowego przybierze ostateczny kształt “to-be”:
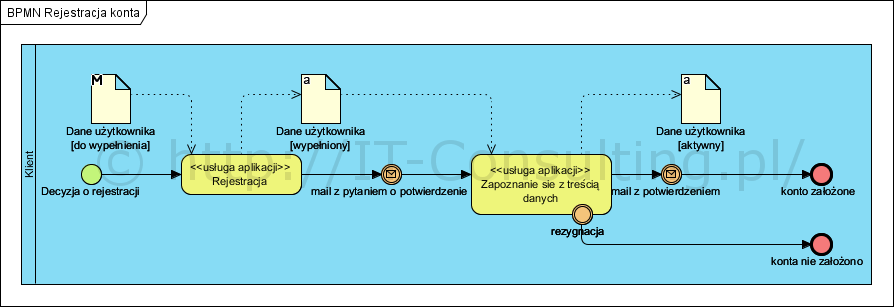
Jedynie Klient używa aplikacji, to kto jest właścicielem oprogramowania nie ma żadnego znaczenia i nie modelujemy tego. Wskazane na wcześniejszym diagramie reguły biznesowe (np. oczekiwanie na powiedzenie rejestracji wygasa po trzech dniach) można zebrać w postaci zestawienia i dołączyć do dokumentacji przypadków użycia, albo po prostu przekazać developerowi całą dokumentację (osobiście powielam zestawienia reguł biznesowych przy przypadkach użycia, co polecam, zaś nadmiarowa dokumentacja jest łatwiejsza w użyciu dla developera).
Autor cytowanego artykułu umieścił w nim także taki diagram:
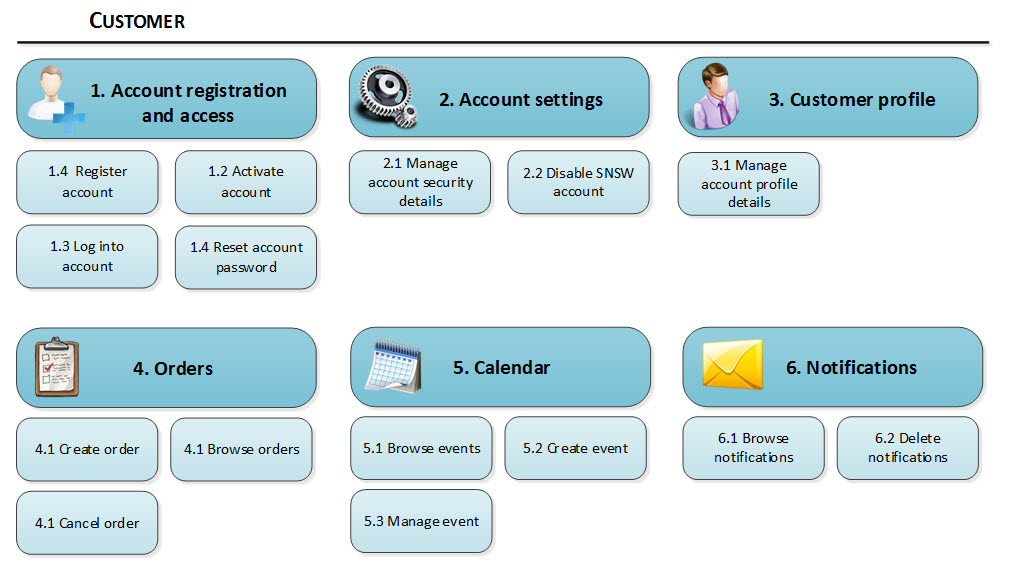
Mogę to teraz skomentować tak:
- jest to jakieś nieformalne zestawienie “funkcjonalności”
- funkcjonalności oznaczone 1, 2 oraz 3 to nic innego jak użycie, w różnym kontekście, przypadku użycia (CRUD) Zarządzanie kontem.
Nie modelowałem już procesu składania zamówienia (mam nadzieję że nie trzeba :)). Kalendarz to pewna forma zobrazowania terminów (np. zamówień, jeżeli było takie wymaganie), być może na stronie “panel Klienta” (robota dla UX designera). Monitowanie (6. Notification) to nic innego jak kolejne pozafunkcjonalne wymaganie (monitowanie o czymś jako takie to nie jest przypadek użycia), realizowane w sposób udokumentowany na diagramie sekwencji (scenariusz realizacji przypadku użycia). Diagram sekwencji jak wyżej, po drobnych korektach, będzie pasował do każdej operacji z danymi Klienta, także do aktywności Zapoznanie się z treścią danych w toku potwierdzania rejestracji (tu kontekst prostego potwierdzenia operacji Retrive).
Przedstawiłem wersję, która nie wymaga używania żadnych nieformalnych diagramów (UML i BPMN w zupełności wystarczą). Wersję, która jest zgodna z MDA, więc wpisuje się dobrze w proces analizy biznesowej (model CIM), oddzielonej od projektowania (model PIM) i implementacji (model PSM, tu pominięty i realnie rzadko wykonywany u developera). Wersję, która w 100% pozwala na śladowanie wymagań. To co opisałem jest także zgodne z zaleceniami BABoK, tworzenia jako wymagania modeli “białej skrzynki” czyli projektu rozwiązania (produktu).
Jak widać, możliwe jest, że jeden przypadek przypadek użycia (dotyczy to szczególnie tych oznaczanych CRUD) jako usługa aplikacji, będzie wykorzystywany w wielu kontekstach (podobnie jak młotek i jego usługa “uderz w to”, może być użyty zarówno do wbijania gwoździa jak i do wybijania szyby).
Chciałem także kolejny raz pokazać, że zamiast dokumentowania wymagań metodą monstrualnych opisów prozą i zestawień w tabelach, z którymi to opisami autorzy mają nie raz ogromne problemy z utrzymaniem ich kompletności, spójności i niesprzeczności zaś developerzy ogromne problemy z interpretacją, warto wymagania przekazywać w postaci spójnego i przetestowanego i logicznego projektu. Warto także zadbać by schematy blokowe (modele) były tworzone zgodne z określonymi zasadami (notacje, dobre praktyki) bez czego będą trudne w jednoznacznej interpretacji.
Moi zdaniem podejście MDA zaprezentowane powyżej jest znacznie skuteczniejsze i daje lepsze zrozumienie, niż wersja pokazana przez autora artykułu Use cases or business process maps, what technique to use?, ale ocenę pozostawiam czytelnikom (zachęcam do zadawania pytań i dyskusji).
Co z tytułowym pytaniem: Przypadki użycia czy model procesu, czego używać?
Używać obu diagramów zgodnie z ich przeznaczeniem…

Czy te stereotypy (tu <>) w aktywnościach BPMN to jakiś autorski pomysł (diagram ‘BPMN Rejestracja konta’)? Przejrzałem na szybko książkę Sz. Drejewicza, B. Silvera i specyfikację i nic takiego tam nie widzę.
Btw czy w ‘Diagram przypadków użycia 2’ nie powinien być tylko jeden przypadek ‘Zarządzanie kontem’? To ‘Sprawdzenie salda’ to imho jest to R w CRUDzie 🙂
BPMN od wersji 2.0 dopuszcza dodawanie nowych “znaków” pod warunkiem poprawnego ich zdefiniowania (mechanizm analogiczny do profili w UML). W literaturze spotykane są różne konwencje klasyfikowania aktywności na modelach analitycznych (np. tych transformowanych na przypadki użycia): kolorowanie, kojarzenie z ikoną “komputer”, odpowiednikiem kolorowania jest stereotypowanie (niektóre narzędzia CASE mają wbudowane możliwości użycia wszystkich te możliwości). Moim zdaniem stereotypowanie jest najwygodniejsze bo pojęcie profilu jest dobrze zdefiniowane w OMG/UML. Generalnie OMG normalizuje “swoje” notacje (co widać bardzo w zmianach w UML 2.5). Co do zasady nie stosuję żadnych “autorskich” konstrukcji 🙂 bo niszczą komunikację (inni mogą nie zrozumieć) i przenoszalność diagramów między narzędziami.
Co do przypadków użycia (PU): Konto Klienta to dane o nim (kartoteka), saldo płatności to wyliczenie aktualnego salda na bazie faktur i np. przelewów. To dwa różne “obiekty biznesowe”. Z powodów czysto technicznych (nie rozpisywałem się) nie precyzowałem tego, wspomina o tym jednak autor artykułu cytowanego i miałem cichą nadzieję, że widać to na cytowanych diagramach. Niewątpliwie, pilnując granic kontekstów, “kartoteka klienta”, czyli jego dane rejestracyjne, nie są obiektem, który przechowuje dane finansowe. Dlatego saldo klienta to Retrive innego obiektu więc i odrębny PU. Dodam, że nie widzę żadnego uzasadnienia dla oddzielenia rejestracji klienta od aktualizacji danych o nim, co proponuje autor artykułu cytowanego. Kolejna wada pierwowzoru to brak słownika pojęć, ja osobiście zresztą unikam nazwy “konto” na dane rejestrowe ;)…
Dzięki za wyczerpującą odpowiedź 🙂 Rzeczywiście to słowo “konto” mnie zmyliło w kontekście tych przypadków użycia.
Dlaczego ZAWSZE (tu już o tym nie pisałem) zwracam uwagę by zaczynać od słowników pojęć i kontekstowych modeli pojęciowych (co autor artykułu także pominął). O złym nazewnictwie jako źródle wielu problemów pisałem tu “Czym jest model…“
Czy czynności rejestracja i zapoznanie się z treścią będą realizowane jako jeden pu?
Zakładając konwencję stosowania CRUD tak. Za pierwszym razem to dwa kroki: Create potem Retrive, każdy następny raz to krok: Update i Retrive. Obiekt reprezentujący dane użytkownika jest jeden… Za pierwszym razem będzie inicjowany, potem już tylko aktualizacja lub wgląd.., Dla pewności można zostawić cykl konieczność potwierdzania (opt-in) każdej dokonanej zmiany (co często zalecam).
Dziękuję za informację.
Nie rozumiem Pańskiego wytłumaczenia, dlaczego muszą być 2 pu ‘zarządzanie kontem (crud)’ i ‘sprawdzenie salda’. Pisze Pan, że muszą być 2, gdyż dotyczą operacji na różnych obiektach (kartoteka i dane finansowe). Z tego co wiem, pu reprezentują funkcjonalności użyteczne dla aktora, co oznacza, że dana funkcjonalność może operować na różnych obiektach. Inaczej, punktem wyjścia do specyfikowania pu są funkcjonalności, a nie obiekty. Czy się mylę?
PU reprezentują usługi (ja piszę wyłącznie o UML). PU nie reprezentują “funkcjonalności”.
Specyfiakcja UML 2.5:
18 UseCases
18.1 Use Cases
18.1.1 Summary
UseCases are a means to capture the requirements of systems, i.e., what systems are supposed to do. The key concepts
specified in this clause are Actors, UseCases, and subjects. Each UseCase?s subject represents a system under
consideration to which the UseCase applies. Users and any other systems that may interact with a subject are represented
as Actors.
A UseCase is a specification of behavior. An instance of a UseCase refers to an occurrence of the emergent behavior
that conforms to the corresponding UseCase. Such instances are often described by Interactions.
18.1.3 Semantics
18.1.3.1 Use Cases and Actors
A UseCase may apply to any number of subjects. When a UseCase applies to a subject, it specifies a set of behaviors
performed by that subject, which yields an observable result that is of value for Actors or other stakeholders of the
subject.
Tak więc czym innym jest “aktualizacja danych użytkownika” (potocznie zwane kontem w systemie) a czym innym “stan rozrachunków” (które dotyczą użytkownika, jest to stan jego konta finansowego, nie są to “dane go opisujące”).
W UML, nie ma wyróżnianego ścisłego pojęcia “funkcjonalność”, za jest pojęcie “usługi aplikacyjnej”.
Sugeruję w kontekście UML korzystać ze specyfikacji tego języka.
1. OK – PU reprezentują usługi systemu.
2. Nadal uważam, że przy projektowaniu PU wychodzę od usług, które system świadczy aktorowi, a nie od obiektów, które są związane z usługami.
3. Nie rozumiem zapisu ‘”A UseCase may apply to any number of subjects.” Myślałem, że konkretny PU należy do konkretnego systemu (subject). Prośba o wyjaśnienie.
1. ok 🙂
2. tu ważna uwaga: architektura nie jest obojętna, mamy to co nazywamy wzorcami projektowymi i dobrymi praktykami, jednym z nich jest wzorzec architektoniczny “przypadek użycia jako mikroserwis” a do tego mamy SOLID, w tym separacja kontekstów czy hermetyzacja komponentów itp.. (temat na osobny wykład lub małe studia), generalnie PU powinien być quasi niezależną usługą (w dobrze zaprojektowanym systemie kolejność implementacji PU nie powinna być ograniczona), w konsekwencji PU to usługi bazujące na jednym obiekcie biznesowym (lub złożonym agregacie). Polecam np. te dwa wpisy Fowlera:
https://martinfowler.com/bliki/BoundedContext.html
https://martinfowler.com/articles/microservices.html
3. to proste: PU to usługa i np. “System pozwala wystawić faktury i zarządzać nimi” a może to być usługa systemu ERP, prostego FK, systemu CRM…. zdarzały mi projekty, gdzie gdzie faktury wystawiane były w kilku systemach i integrowane w centralnym ERP/FK…
Rozumiem, że w przypadku integracji faktur w systemie centralnym był jeden PU ‘Wystawianie faktur’, który był realizowany w kilku systemach?
Tak: fakturę mogła wystawić księgowa w ERP i sprzedawca w CRM (w kilkunastu oddziałach). Nie ma w tym nic niezwykłego.
1. Wystawienie faktury rozumiemy jako wygenerowanie dokumentu z zapisanych danych w systemie ERP albo CRM.
2. Rozumiem, że logika generowania faktury opisana w jednym PU została zaimplementowana w 2 systemach (ERP i CRM) +- obsługa pobierania zapisanych danych.
1. Wystawienie faktury to utworzenie dokumentu będącego fakturą, myślenie bazodanowe (wszystko jest raportem) jest bardziej szkodliwe niż pomocne.
2. PU to zewnętrzne objawy zachowania systemu. Logika (wewnętrzny mechanizm) może być różna, np. tylko w CRM będzie logika upustów dla stałych klientów ale obie usługi, w efekcie, dadzą jako swój produkt fakturę zgodną z prawem.
1. Dlaczego wystawienie faktury jest czymś więcej niż wystawieniem raportu?, są dane sprzedażowe, z których generujemy dokument?
2. Tak się zastanawiam się, czy ERP i CRM traktujemy jako jeden system (gdzie ERP I CRM to komponenty), czy jako 2 niezależne systemy?
1. bo mowa o “stworzeniu dokumentu o określonej strukturze z użyciem określonego mechanizmu”, po drugie baza danych nie przechowuje żadnych dokumentów tylko rozdzielone znormalizowane dane…. dlatego używając relacyjnego systemu i bazy danych “wszystko jest raportem”… a faktura w rzeczywistości jest (i powinna być) zmaterializowanym bytem powstałym w dniu wystawienia, czego zresztą wymaga od systemów prawo.
2. oczywiście jako dwa odrębne systemu, tym bardziej, że w dowolnym momencie przyszłości jeden z nich może wymagać zmiany lub nawet wymiany i nie powinno to pociągać za sobą “zmiany całości”…
OK. Dziękuję za wyjaśnienie.