Big Data czyli jak świat poradził sobie z ogromną ilością zmiennych informacji: NoSQL Wykład otwarty na WIT https://youtu.be/pJZekd6PHm4 Nagromadzenie danych to jeszcze nie jest nauka (Galileusz) Duże bazy danych na określony temat - najczęściej mowa o zachowaniach klientów ? to ostatnio temat pierwszych, najdalej drugich, stron gazet. BigData to temat przewodni konferencji i artykułów na pierwszych stronach periodyków branży IT. W 2011 roku artykuł na podobny temat kończyłem pytając: Budowanie modeli na bazie małych partii danych jest po pierwsze wiarygodniejsze (paradoksalnie) niż proste wnioskowanie statystyczne, po drugie daje szanse odkrycia…
W dużym skrócie: nie warto dublować kompetencji bo to nomen omen powielanie ich kosztów. Jeżeli firma ma wdrożone procedury kontrolingowe, to naturalnym jest przekazanie danych (produktu) modelowania i optymalizacji procesów, zamiast wzajemne konkurowanie, tym bardziej, że dane z kontrolingu zawsze - jak sądzę - zostaną uznane za bardziej wiarygodne . Bardzo dobrym "narzędziem" łączącym kontroling, modelowanie procesów i zasoby (nie tylko IT) jest architektura korporacyjna, ale to materiał na kolejny artykuł ;).

Technologia IT pozwala zapisywać ogromne ilości danych. W cytowanym na początku artykule namawia się nas na inwestycje w technologie, które dają szanse na "przerobienie" tego. A czy aby na pewno musimy gromadzić to wszystko? Mózg ludzki ma doskonała obronę przed nadmiarem informacji, jak wiemy radzimy sobie całkiem nieźle mimo tego, że wiele rzeczy zapominamy. To miliony lat ewolucji stworzyły ten mechanizm! Wystarczy go naśladować.Zmierzam do tego, że projektowanie systemów informatycznych to także projektowanie tego jakimi danymi zarządzać i które zachowywać np. w hurtowni danych. Gdyby nasza firma zawierała nieskończoną ilość transakcji sprzedaży rocznie (:)) czy musimy analizować wszystkie by ocenić udziały w rynku, podział na regiony, najlepszych i najgorszych sprzedawców, nadużycia w transporcie? Nie! wystarczy mieć dane reprezentatywne, rejestrować do analiz tylko ustalona część ([retencja danych]]). Niestety nie jest łatwo podjąć decyzje, która to część i to jest (powinno być) tak na prawdę część analizy wymagań. A koszt takiej analizy nijak się nie ma, jest znacznie mniej kosztowna, niż systemy do przetwarzania wszystkich tych danych. Nie dajmy się zwariować z wydatkami na rosnące pojemności systemów składowania i przetwarzania danych.
Hurtownia danych to model stworzony pod kątem przetwarzania faktów historycznych na prostym modelu danych (diagram powyżej, górny, to tak zwana kostka OLAP). Opracowanie takiego modelu wymaga specjalnej analizy i projektu, ale nie zapominajmy: analizę się robi raz a raporty stale...Tak więc szanowni Państwo. Jeśli tylko Wasza firma jest bliżej czołówki niż ogona rankingu rynku w Waszej branży, nie dajcie się namówić na jeden zintegrowany ERP i jakiś model referencyjny, bo nawet jak uda się go wdrożyć, to zmiana czegokolwiek będzie trudna a upgrade do nowszej wersji niemożliwy. Opracowanie projektu systemu składającego się z komponentów, pozwoli Wam dobrać najlepiej spełniające Wasze wymagania aplikacje. Jak z klocków LEGO złożycie "dedykowany system" pomagający utrzymać przewagę na rynku, a nie cofający Waszą firmą do poziomu "innych podmiotów w branży".

Warto tworzyć dobrze przemyślane systemy metadanych dla systemów archiwizacji gdyż pozwala to z jednej strony "spiąć" archiwum dokumentów z hurtownią danych z drugiej "pozbyć się" śmieci. Tempo przyrostu danych stale rośnie gdyż biznesowe oprogramowanie, automatyzując wiele naszych czynności, wytwarza je w tempie w jakim człowiek nigdy nie był by w stanie. Po drugie narasta zjawisko powielania, co nazywam to syndromem "copy&paste". Wiele dokumentów (o zgrozo także tych podobno "autorskich") i powstaje coraz częściej metodą powielania tego co znajdzie się w firmowych archiwach (wiedza korporacyjna czyli po prostu jej zanik, bo wiedza to umiejętność napisania czegoś a nie skopiowania) czy w sieci.
Moja praktyka (to co dostaje do audytu u klientów) pokazuje, że dokumenty wytworzone "od zera" praktycznie zawsze mają większą wartość merytoryczną. Do tego dochodzi ryzyko przeniesienia, podczas kopiowania, treści niechcianych. Kopiując dziesiątki stron "starej oferty" lub poprzedniego "opracowania doradczego", tworząc kolejne "indywidualne autorskie opracowanie" narazić się można nie tylko na ujawnienie tajemnicy ale także na zwykłe ośmieszenie. Dlatego system zarządzania dokumentami i wiedzą należy dobrze zaprojektować. W przeciwnym wypadku narażamy się na budowę wielkiego śmietnika.
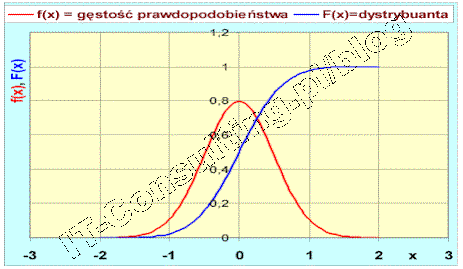
Dlatego hurtownie danych i tak zwane systemy Business Inteligence, wszelkie systemy wspomagania decyzji, to albo analiza historii albo prognozowanie oparte na modelach. Owszem analiza historii to także analiza korelacji ale to inny temat :). W kwestii marketingu lepiej jest, moim zdaniem, opracować model zjawiska, jednak do tego nie potrzebne są duże ilości danych a jedynie minimalny [[zestaw danych reprezentatywnych]] i to się nazywa zasadą ekonomii myślenia. Wielką zaś sztuką projektowania hurtowni danych dla systemów BI, nie jest samo gromadzenie danych a właśnie ich odsiewanie, dlatego systemy analityczne integrowane z systemami CRM bywają czasem bardziej szkodliwe niż pomocne.
 Pewna firma, dostawca znanego systemu [[ERP]], opublikowała krótki tekst o tak zwanych mitach dotyczących “obaw przed zakupem dużego ERP”. Mitów na ten temat faktycznie jest wiele i są bardzo różne. Rzecz w tym, że moim zdaniem jedne faktycznie są mitami inne już nie koniecznie. Dostawca jakiegokolwiek produktu ma prawo uczciwie opisywać swój produkt i jego cechy. W kwestii zaś opisywania tak zwanych korzyści to tylko wtedy gdy oferta dotyczy konkretnego zastosowania u konkretnego klienta. Także jeżeli opis korzyści dotyczy dobrze zdefiniowanej grupy odbiorców ([[grupa docelowa]] w marketingu to grupa potencjalnych odbiorców o tych samych lub podobnych potrzebach) to ma to sens. Jeżeli zaś dostawca pozwala sobie na komentarze w rodzaju “to na pewno jest dobre dla każdego odbiorcy” (nawet jeśłi to grupa MSP) to popełnia w moich oczach nadużycie, polegające choćby na braku szacunku dla adresatów tych “wywodów”….. bo wmawianie mi co jest dla mnie dobre lub krytyczna ocena tego co robię, bez zapoznania się ze mną jest… wciskaniem mi tego czegoś.
Pewna firma, dostawca znanego systemu [[ERP]], opublikowała krótki tekst o tak zwanych mitach dotyczących “obaw przed zakupem dużego ERP”. Mitów na ten temat faktycznie jest wiele i są bardzo różne. Rzecz w tym, że moim zdaniem jedne faktycznie są mitami inne już nie koniecznie. Dostawca jakiegokolwiek produktu ma prawo uczciwie opisywać swój produkt i jego cechy. W kwestii zaś opisywania tak zwanych korzyści to tylko wtedy gdy oferta dotyczy konkretnego zastosowania u konkretnego klienta. Także jeżeli opis korzyści dotyczy dobrze zdefiniowanej grupy odbiorców ([[grupa docelowa]] w marketingu to grupa potencjalnych odbiorców o tych samych lub podobnych potrzebach) to ma to sens. Jeżeli zaś dostawca pozwala sobie na komentarze w rodzaju “to na pewno jest dobre dla każdego odbiorcy” (nawet jeśłi to grupa MSP) to popełnia w moich oczach nadużycie, polegające choćby na braku szacunku dla adresatów tych “wywodów”….. bo wmawianie mi co jest dla mnie dobre lub krytyczna ocena tego co robię, bez zapoznania się ze mną jest… wciskaniem mi tego czegoś.
(więcej…)


 Pewna firma, dostawca znanego systemu [[ERP]], opublikowała krótki tekst o tak zwanych mitach dotyczących “obaw przed zakupem dużego ERP”. Mitów na ten temat faktycznie jest wiele i są bardzo różne. Rzecz w tym, że moim zdaniem jedne faktycznie są mitami inne już nie koniecznie. Dostawca jakiegokolwiek produktu ma prawo uczciwie opisywać swój produkt i jego cechy. W kwestii zaś opisywania tak zwanych korzyści to tylko wtedy gdy oferta dotyczy konkretnego zastosowania u konkretnego klienta. Także jeżeli opis korzyści dotyczy dobrze zdefiniowanej grupy odbiorców ([[grupa docelowa]] w marketingu to grupa potencjalnych odbiorców o tych samych lub podobnych potrzebach) to ma to sens. Jeżeli zaś dostawca pozwala sobie na komentarze w rodzaju “to na pewno jest dobre dla każdego odbiorcy” (nawet jeśłi to grupa MSP) to popełnia w moich oczach nadużycie, polegające choćby na braku szacunku dla adresatów tych “wywodów”….. bo wmawianie mi co jest dla mnie dobre lub krytyczna ocena tego co robię, bez zapoznania się ze mną jest… wciskaniem mi tego czegoś.
Pewna firma, dostawca znanego systemu [[ERP]], opublikowała krótki tekst o tak zwanych mitach dotyczących “obaw przed zakupem dużego ERP”. Mitów na ten temat faktycznie jest wiele i są bardzo różne. Rzecz w tym, że moim zdaniem jedne faktycznie są mitami inne już nie koniecznie. Dostawca jakiegokolwiek produktu ma prawo uczciwie opisywać swój produkt i jego cechy. W kwestii zaś opisywania tak zwanych korzyści to tylko wtedy gdy oferta dotyczy konkretnego zastosowania u konkretnego klienta. Także jeżeli opis korzyści dotyczy dobrze zdefiniowanej grupy odbiorców ([[grupa docelowa]] w marketingu to grupa potencjalnych odbiorców o tych samych lub podobnych potrzebach) to ma to sens. Jeżeli zaś dostawca pozwala sobie na komentarze w rodzaju “to na pewno jest dobre dla każdego odbiorcy” (nawet jeśłi to grupa MSP) to popełnia w moich oczach nadużycie, polegające choćby na braku szacunku dla adresatów tych “wywodów”….. bo wmawianie mi co jest dla mnie dobre lub krytyczna ocena tego co robię, bez zapoznania się ze mną jest… wciskaniem mi tego czegoś.