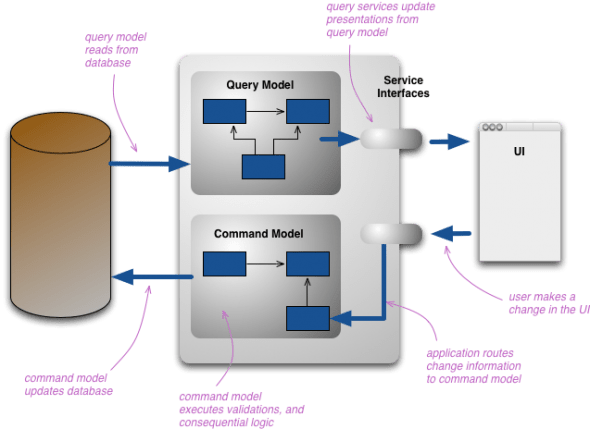
Wprowadzenie Jednym z najczęściej stosowanych wzorców projektowych w warstwie dziedzinowej jest wzorzec CQRS (Command Query Responsibility Segregation) oraz często wykorzystywany razem z nim Event Sourcing. W 2012 roku pisałem o tym wzorcu w kontekście optymalizacji wydajnosci: Idea tego pomysłu na tym, by nie optymalizować wydajności systemu metodą, nie raz zgniłego, kompromisu, a podejść do problemu dzieląc go na dwa problemy: zgodność modelu z rzeczywistością i wydajność całego systemu. Pierwszy problem rozwiązujemy tworząc wierny model struktury opisującej produkty, drugi problem ? wydajności ? rozwiązujemy tworząc drugi uproszczony model produktów, do celów szybkiej realizacji kilku…

Wprowadzenie
Napisałem o orientacji na dokumenty w toku analiz:
Często jestem i ja pytany o to ??Jak wyjaśnić złożone rozwiązanie techniczne interesariuszom nietechnicznym?? Jak wielu mi podobnych odpowiadam: rozmawiaj dokumentami. Sponsor projektu, przyszli użytkownicy, postrzegają swoją pracę poprzez dokumenty: ich treść i układ. (Wymagania na formularze czyli diagramy struktur złożonych i XML)
Dzisiaj pójdziemy dalej, omówimy to gdzie i jak zachować tę informację. Posłużę się prostym przykładem przychodni weterynaryjnej. Artykuł będzie opisem metody podejścia do analizy zorientowanej na procesy i dokumenty.
Tekst ma dwie części: pierwsza jest opisem drogi jaka prowadzi nas do zdefiniowania tego jakie dokumenty, jaką mają (mieć) zawartość i strukturę. Praktycznie jest to opis analizy i projektowania. Druga – krótka – to przykładowa architektura logiki realizacji aplikacji, pokazująca miejsce dokumentowej bazy danych w architekturze i projekcie, czyli także projektowanie.
Celem tego wpisu jest pokazanie czym może być analiza oraz jej produkt jakim jest Techniczny Projekt Oprogramowania.
(więcej…)
Rok temu pisałem o wzorcu CQRS, tamten wpis bazował głównie na artykule M.Fowlera i stanowił raczej zajawkę tematu. Teraz mam troszkę własnych doświadczeń, także w dyskusjach z programistami, i przytoczę tu moja konkluzję, nieco chyba odbiegającą od opisu M.Fowlera, którego albo nie zrozumiałem ale on uprościł swój wpis (dzięki czemu ja wtedy nie zrozumiałem). Mamy problem polegający na tym, że firma ma ogromną ofertę pewnych bardzo złożonych podzespołów, żeby nie psuć ich opisu i możliwości rozbudowy, model dziedziny odwzorowuje strukturę tych części. Jednak bardzo duża liczba użytkowników sklepu internetowego…
Opisując wymagania wyłącznie jako "czarną skrzynkę" nie wiem co dostanę. Większość developerów będzie dążyło do uproszczenia implementacji (ich koszt, nie raz brak wiedzy) by zaspokoić na minimalnym poziomie wymagania opisane przypadkami użycia. Nie raz klient słyszy "tu musimy to uprościć bo tak się nie da", a zamawiający, nie mając kompetencji by polemizować z taką opinią, zgadza się i dostarczony system staje się zgniłym kompromisem opartym właśnie na "czarnej skrzynce" jako specyfikacji zamówień: "dostaliśmy dokładnie to co zamówiliśmy ale zupełnie nie to czego naprawdę potrzebujemy".Tak więc,nie ma znaczenia fakt, że na pewno są na rynku developerzy znający problem, który opisałem i stosujący opisane tu rozwiązanie takich problemów. Jednak nawet cień ryzyka (a jest ono na prawdę duże), że dostaniemy bubla, daje zamawiającemu prawo do szczegółowego definiowania wymagań jako "białej skrzynki", bo dzięki temu zamawiający dostanie "to czego potrzebuje a nie tylko to co zamówił".

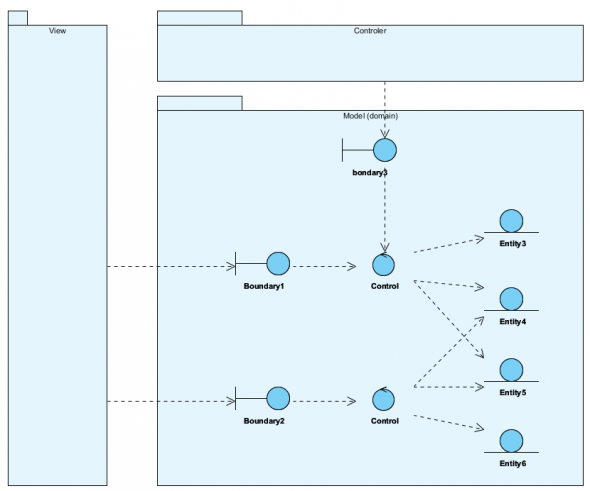
Opisywałem ostatnio wzorzec DDD jako narzędzie dokumentowania analizy. Faktycznie, czytelnicy mają wiele racji, jest on dość "bliski implementacji". Niejednokrotnie "lepszym pomysłem" jest opis logiki systemu na nieco wyższym poziomie abstrakcji pozostawiając tym samym więcej swobody developerowi. [...] Nieco inne podejście, to które stosuję obecnie, opisuję poniżej. Zachowując podstawowe znaczenia tych trzech klas, dostosowałem je do wzorca MVVC. Jest to o tyle wygodne i ważne, że stosowanie wzorca BCE wyłącznie do modelowania logiki biznesowej wymaga zachowania hermetyzacji komponentu Model. W takim układzie boundary nie będzie elementem komponentu View a Modelu. Jego rola to stworzenie dedykowanego interfejsu do model np. pomiędzy komponentem View lub Controlerem. Dzięki temu możliwe jest stworzenie odrębnego interfejsu dla View na duży ekran i odrębnego dla View na np. małych ekranach smartfonów. Tak więc jest moim zdaniem droga do modelowania wymagań metodą "tak to ma działać" a nie tylko "tak to ma wyglądać", bo to drugie jest przyczyną wielu problemów...