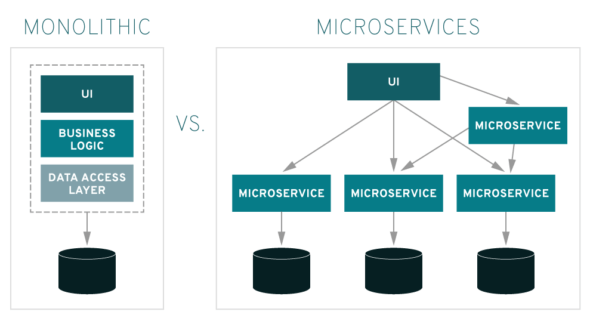
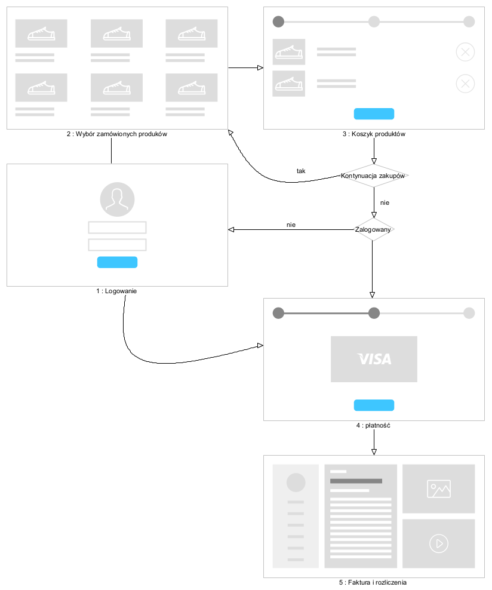
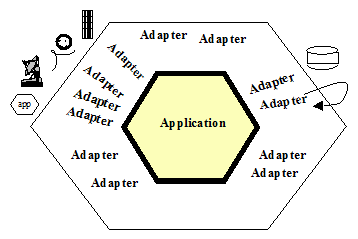
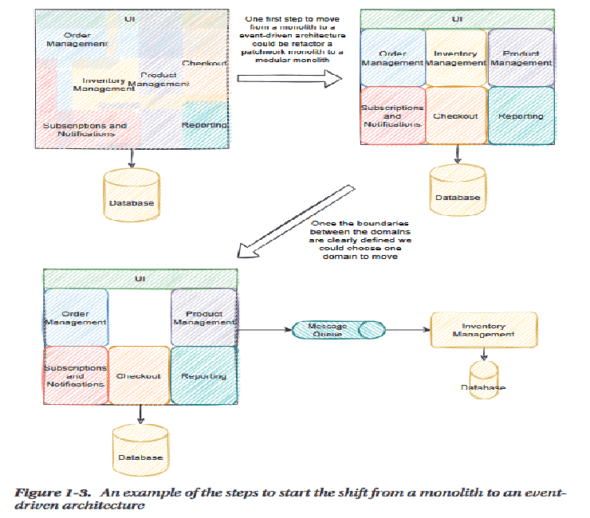
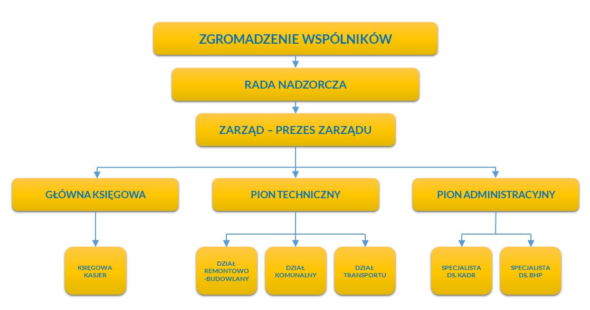
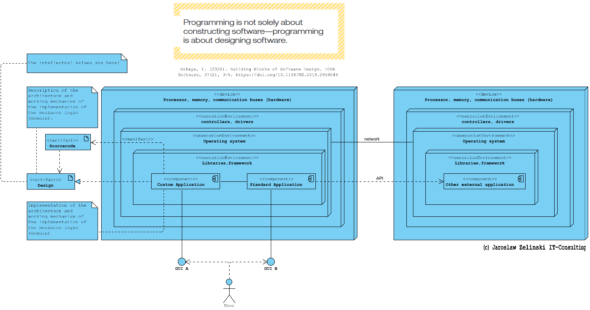
Sygnatariusze Agile Manifesto o UML
Wprowadzenie Wiele się mówi o Agile i o ograniczaniu roku dokumentacji i UML w inżynierii oprogramowania. Mam na półce wiele książek o projektowaniu i o UML, wiele z nich to książki napisane przez sygnatariuszy Agile Manifesto. Postanowiłem przygotować krótkie zestawienie. Poniżej zestawienie zawierające obszary i przypadki wykorzystania UML w książkach napisanych przez sygnatariuszy Agile Manifesto. Uwzględnia pełne spektrum: autorów, tytuły, typy diagramów UML oraz obszary modelowania. 1. Martin Fowler Książki zawierające UML UML Distilled Analysis Patterns Patterns of Enterprise Application Architecture Refactoring Domain-Specific Languages Typ UML Diagramy klas Diagramy sekwencji…