Wprowadzenie
Na ten wpis pewnie wielu z Was czeka, tak przynajmniej sugerują listy do mnie i głosy na forach, a także potencjalni klienci. Ci, których niestety czasem krytykuję, także pewnie czekają. Pokażę na prostym przykładzie, proces od analizy przez wymagania aż do projektu dedykowanego oprogramowania. Całość będzie zgodna z fazami CIM/PIM (www.omg.org/mda). Projekt dziedziny, który powstanie będzie spełniał zasady SOLID projektowania obiektowego, projektowania przez kompozycje (zamiast dziedziczenia) (polecam artykuł Łukasza Barana) i DDD. Opis dotyczy każdego projektu związanego z oprogramowaniem, także gotowym np. ERP, CRM, EOD itp.
Korzystałem z opisu zasad gry w szachy zamieszczonego na WIKI:
Zasady gry w szachy ? prawidła regulujące sposób rozgrywania partii szachów. Choć pochodzenie gry nie zostało dokładnie wyjaśnione, to współczesne zasady ukształtowały się w średniowieczu. Ewoluowały one do początków XIX wieku, kiedy to osiągnęły właściwie swą bieżącą postać. W zależności od miejsca zasady gry różniły się od siebie, współcześnie za przepisy gry odpowiada Międzynarodowa Federacja Szachowa (Fédération Internationale des Échecs, FIDE). Przepisy te mogą się różnić w przypadku różnych wariantów gry, np. dla szachów szybkich, błyskawicznych czy korespondencyjnych. (Zasady gry w szachy ? Wikipedia, wolna encyklopedia).
To na co chcę zwrócić tu uwagę w szczególności, to metafora:
projektując (modelując) oprogramowanie dla człowieka, modelujemy narzędzie dla tego człowieka a nie jego samego.
Swego czasu pisałem, w artykule o nazywaniu klas, że oprogramowanie z reguły zastępuje dotychczasowe narzędzie człowieka a nie człowieka jako takiego. Druga ważna rzecz: aktor jest równoprawnym elementem systemu (tu systemem jest organizacja z jej ludźmi i używanymi przez nich narzędziami). No to zaczynamy.
Cel zamawiającego
Często projekt zaczyna się od pustej kartki, ale nie raz Zamawiający (sponsor projektu) ma już swoje wymagania, z reguły jest to jakaś lista w rodzaju:

Z reguły z listy wymagań (a potrafi mieć setki pozycji) nie wynika wprost cel sponsora, a jedynie to jak sobie on wyobraża rozwiązanie swojego problemu (wyobraźcie sobie powyższą listę bez skrajnej lewej i prawej kolumny). Wstępne uporządkowanie tej listy pozwala uznać, że wymaganiem jest wytworzenie programu do gry w szachy na tablet i smartfon. Pozostałe to pewne cechy tego “głównego” wymagania biznesowego.
Od dłuższego czasu przestałem na tym etapie używać pojęcia wymagań funkcjonalnych i niefunkcjonalnych. Na prawie każdym szkoleniu i większości projektów usłyszycie, że to kanon analizy wymagań, a ja – i nie tylko jak pokazuje literatura- uważam, że skoro sponsor projektu (tak zwany biznes) z reguły nie rozumie tych pojęć, to nie należy ich używać w dialogu z biznesem na tym etapie projektu, a tym bardziej żądać takiego podziału. No to kiedy? Zobaczycie pod koniec :). Nie znam przypadku, by zamawiający “biznes” poprawnie rozróżnił te dwie grupy wymagań albo potrafił samemu spisać “przypadki użycia”. A jeżeli jeszcze zażądamy podziału na FURPS to będzie “masakra”. Czy ma to robić od razu analityk? A po co skoro Zamawiający i tak tego nie zweryfikuje a jest adresatem tego dokumentu? Na tym etapie, powyższa lista, można poprzestać na uznaniu powyższej listy za “wymagania biznesowe” (czyli te, które wprost formułuje “biznes”).
Tak więc na tym etapie warto raczej poświęcić czas, by zrozumieć cel Zamawiającego, wywiady pozwalają na stworzenie obrazu celu biznesowego i tak zwanej motywacji biznesowej:
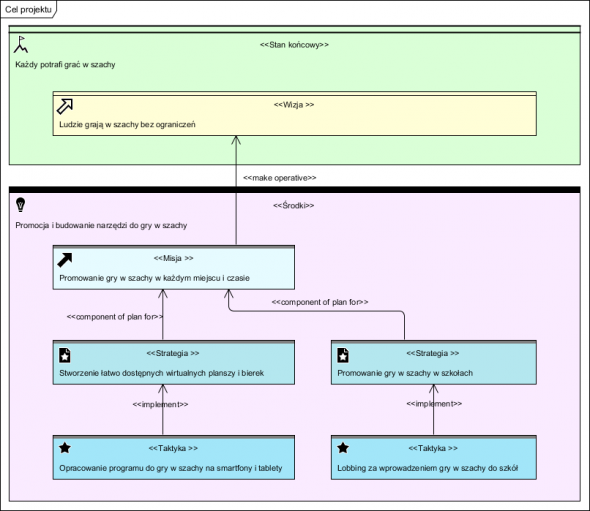
Powyższe bardzo pomaga w projekcie gdyż po pierwsze, stanowi przysłowiowe światełko w tunelu, po drugie każde szczegółowe wymaganie, jeżeli ma stanowić element zakresu projektu, musi wspierać cele biznesowe. To podstawowe narzędzie panowania nad zakresem projektu.
W naszym przypadku, w sferze tworzenia oprogramowania, pozostaje Opracowanie programu do gry w szachy (tak nazywa to sponsor projektu! ciekawe co powstanie). Nadal jednak kryje się tu pewna niewiedza: co to znaczy “do gry w szachy”?
Model pojęciowy – zrozumieć problem i cel projektu
Warto na samym początku opracować słownik pojęć i reguł biznesowych, które także staną się wymaganiem biznesowym. Tak, słownik i reguły są wymaganiem i to bardzo ważnym. Najpierw model pojęciowy:
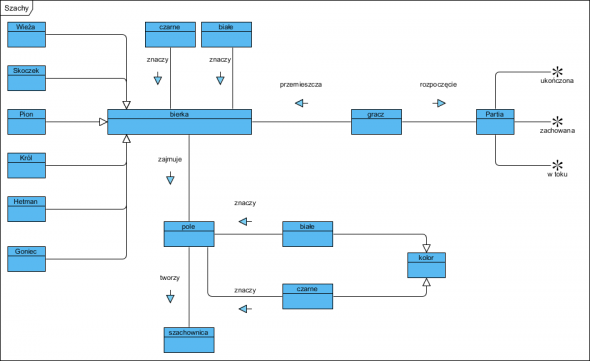
Nie jest to absolutnie żaden model dziedziny. To diagram klas UML (albo SBVR) pokazujący zdefiniowane pojęcia biznesowe oraz fakty jakie łączą je w jeden kontekst. Nie jest to obiektowy model, a terminy słownikowe. Budowanie biznesowego słownika pojęć dla wielu analityków jest gehenną budowania listy dziesiątek i setek definicji. Otóż błędem jest zaliczanie do tego słownika wszystkich pojęć związanych z dziedziną (branża itp.) organizacji Zamawiającego, to prosta droga do przepisania słownika np. j.polskiego. Interesują nas wyłącznie te pojęcie, które stanowią specyfikę problemu a nie wszystkie z nim związane. Narzędziem do budowy takiego słownika (modelu pojęciowego, przestrzeni nazw) są fakty, do słownika biznesowego dodajemy wyłącznie te pojęcia, które są związane ze sobą faktami (zdarzenia) z analizowanej dziedziny i celu projektu. Wtedy pojęć na liście będzie mniej pojęć i będą to tylko te, które służą zachowaniu jednoznaczności dokumentacji projektu, a więc i całej komunikacji w projekcie.
Model procesu biznesowego – zrozumieć co i po co jest robione
Kolejne rozmowy i opis procesu, jaki realizuje (będzie realizował) użytkownik przyszłego programu. Nie jest to proste wbrew pozorom, bo okazuje się, że nie chodzi o grę jaką znamy z komputerów, a o wirtualną planszę, co widać z procesu:
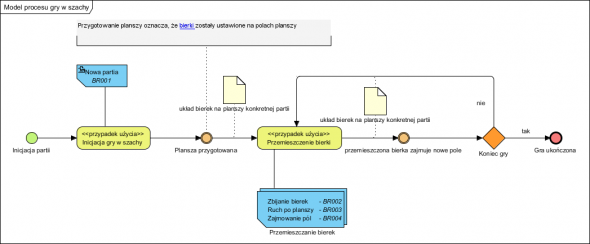
Powyższy proces (jego model, notacja BPMN) może budzić początkowo zdziwienie z powodu pętli. Otóż nie jest to “pętla wstecz” a specyficzna konstrukcja pokazania tego, że dana aktywność (czyli procedura) jest wykonywana wielokrotnie. Standardowo na diagramie była by jedna aktywność bez pętli. Jeżeli chcemy jednak “jasno pokazać” pewną specyfikę np. tego, że “człowiek wykonuje pewną pracę cyklicznie dopóki trwa gra” można użyć poniższej konstrukcji:
Należy pamiętać, że “rombik” (bramka) to graficzne pokazanie tego co zaszło wewnątrz aktywności (w projektach biznesowych nie stosują tej konstrukcji by nie powodować nieporozumień w projekcie).
Ale przypominam, że proces ma (powinien mieć) swój kontekst, jest nim tu korzystanie z planszy do gry w szachy. Dlaczego nie ma np. dwóch graczy na przemian przestawiających pionki? To “ostateczny model”, dojście do niego to efekt testów (tak, modele testujemy żeby wykazać ich poprawność!). Jakie to testy? Ano w szachy może grać jeden człowiek sam ze sobą, może grać dwóch przeciwko sobie, może grać jeden przeciwko wielu na wielu szachownicach (gra symultaniczna), ten model musi “być dobry” w każdym z tych kontekstów – testów (przypadków) i taki jest (jak ktoś ma wątpliwości niech narysuje model procesu gry przez dwóch graczy a potem sprawdzi czy model ten będzie poprawny dla “sam z sobą” i symultany).
Z analizy widać, że grający sami przemieszczają bierki. W tym miejscu warto zaznaczyć, że “odkrywamy” znaczenie wymagania Kontrola reguł gry: nie jest to planowane w pierwszej fazie projektu a program ma jednak do czegoś służyć. Jak widać, w pierwszej fazie stanowi sobą tylko wirtualną planszę, ma zastąpić chybotliwą na kolanach planszę i rozsypujące się po podłodze bierki. Użyte reguły biznesowe (lista osobno) ograniczają jedynie położenie bierek, narzucają (symulują) fizyczne ograniczenia planszy. Proces należy doprowadzić do postaci opisującej faktyczne zachowanie (czynności i ich cele) użytkowników. Użytkownik (każdy) ma jeden i ten sam cel: przestawienie bierki (to czy taki ruch ma sens ocenia on a nie plansza).
Zaznaczamy na modelu procesu czynności wchodzące w zakres projektu (tu są to wszystkie), budujemy diagram przypadków użycia:
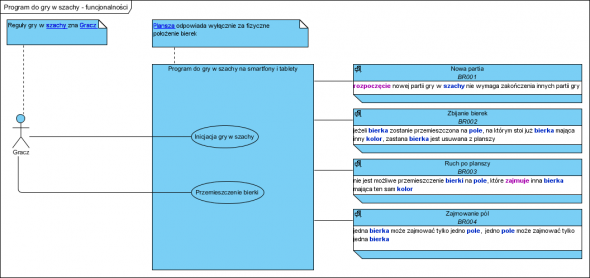
Na diagramie dodałem reguły biznesowe (elementy z poza notacji UML/przypadki użycia) by pokazać, że są one wymaganiem, będą wbudowane w program (zdecydują o jego zachowaniu). W realnych projektach, reguły biznesowe nie są tak umieszczane, stanowią osobną specyfikację.
Druga uwaga, na tym etapie:
doprecyzowujemy i separujemy odpowiedzialność programu i aktora (coś czego prawie nikt nie robi w projektach!).
Tu widać, że reguły regulujące fizyczne możliwości szachownicy (program nie powinien pozwalać na to, na co nie pozwala prawdziwa szachownica) to odpowiedzialność tworzonego programu, zasady gry w szachy (ich znajomość i przestrzeganie) to odpowiedzialność Gracza (program w pierwszym etapie tworzenia nie będzie tego więc kontrolował). Zwracam tu uwagę, że szachownica nie zna zasad gry w szachy! 🙂
Na tym etapie można utworzyć zapytanie do firm, poszukując gotowego oprogramowania na rynku. Dysponujemy przypadkami użycia (wymagania funkcjonalne to usługi aplikacji), regułami biznesowymi (wymagania dziedzinowe) oraz uporządkowaną (ewentualnie przefiltrowaną na okoliczność zgodności z celami biznesowymi) listą wymagań biznesowych, które tu mogą pełnić rolę wymagań poza-funkcjonalnych.
Jeżeli na gotowe, spełniające nasze wymagania oprogramowanie (moduły) nie ma szans, projektujemy je czyli specyfikujemy to, co chcemy dostać od developera.
Jak to się ma do systemów biznesowych ERP i nie tylko ERP?
Kluczowym elementem każdej takiej analizy jest określenie celu sponsora projektu, nazwanie problemu. W tym przypadku (opisana szachownica) istotne jest wykrycie, że celem sponsora jest opracowanie wirtualnej szachownicy a nie “komputerowej gry w szachy” (co na początku, z treści wymagań, nie było oczywiste). Dodanie do szachownicy kontroli reguł gdy to gadżet (element automatyzacji, możliwy do późniejszego wdrożenia). Cel analizy poprzedzającej zakup, to narzędzie do nazwania rozwiązania, a konkretnie wyspecyfikowania wymagań jakie stawiamy przed tym rozwiązaniem. Takie wymagania określono tu na etapie przypadków użycia i reguł biznesowych. Duże projekty, to pewna liczba takich elementarnych (jak ten tu opisany) problemów. Otrzymamy większą specyfikację takich wymagań, praktyka pokazuje, że część z nich (typowo ok. 80% – znowu zasada Pareto) uda się zrealizować z pomocą dostępnego na rynku oprogramowania, pozostałe 20% albo zostanie zaprojektowane i zbudowane jako dedykowane moduły (kastomizacja gotowego jest odradzana) metodą tu opisaną, albo zostaną zaniechane (nie budują wartości uzasadniającej taką inwestycję).
<Od tego momentu powstaje dokumentacja techniczna, jest to wymaganie w stosunku do developera. Zamawiający usługę otrzymuje ten dokument, ale nie jest jego adresatem (nie musi go rozumieć). Wartość dodana tego dokumentu: przetestowany projekt pozwala napisać oprogramowanie “za pierwszym razem”, projekt jako dzieło analityka projektanta działającego na zlecenie Zamawiającego przejmuje Zamawiający, developer nie jest autorem projektu więc nie ma żadnych praw do oprogramowania jakie wytworzy na bazie zlecenia (tworzy tak zwany utwór zależny), w związku z tym nie może tak napisanego oprogramowania sprzedawać na rynku np. konkurentom Zamawiającego, przeczytaj więcej o prawach autorskich i nadużyciach firm programistycznych>.
Pora na model dziedziny – dedykowane rozwiązanie
Teraz wielka kość niezgody :). Ale po kolei.
Do tej pory nadal nie wiadomo “jak to ma działać”. Wiemy tylko do czego posłuży.
To jest ten moment, w którym developer nadal niema czego wyceniać, nadal nie wiemy co dostaniemy, złożenie zamówienia na dedykowane oprogramowanie z powyższą dokumentacją jest wielkim ryzykiem, możliwe jest, że mimo powyższej dokumentacji, dostawca po wielu próbach (po terminie i większym kosztem) dostarczy produkt, może przydatny ale kosztowny w rozbudowie a nie raz wymagający gruntownej przeróbki przy każdej nowej funkcjonalności (praktyka: 100% dotychczas pytanych developerów i studentów, umieściło by reguły przemieszczania bierek w operacjach klas reprezentujących te bierki, a to najgorszy pomysł).
Poniższy model wyjawia “zbyt dużo” jak na ten etap projektu ale jakoś musiałem to pokazać:
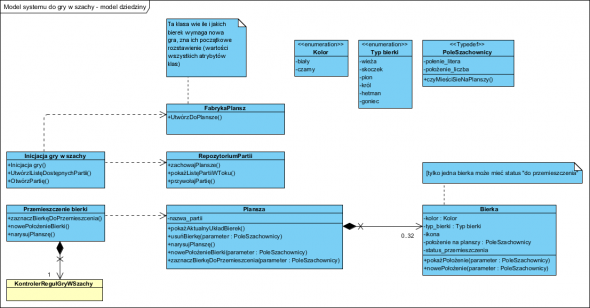
Modele jak powyższy spotkacie na szczęście, np. w książkach o obiektowych wzorcach projektowych. Jak widać nie jest to “model dziedziny”, jaki można zobaczyć na stronach wielu blogów analityków czy materiałów szkoleniowych (nawet uczelnianych 🙁 ). Tam spotkacie raczej modele pojęciowe lub UML’owe atrapy modeli danych. Co najgorsze, nie raz te modele są normalizowane (współdzielone połączenia klas w celu unikania redundancji co z metodami obiektowymi nie ma nic wspólnego, żeby nie powiedzieć kłóci się z nimi).
[tu kolejny przykład na stronie Uniwersytetu Warszawskiego, autor tutoriala pokazuje klasy pojęciowe gry w monopol, na tym etapie nie jest źle, nie wiem po co te liczebności (kto ma je kontrolować), ale nagle pojawia się pojęcie “częściowy model dziedziny” i widzimy ten sam model pojęciowy (!) napakowany atrybutami, co ciekawe nadal model nie zawiera żadnych operacji czyli praktycznie ten “system” nie działa! To klasyczny błąd polegający na projektowaniu strukturalnej bazy danych z masą atrybutów bez żadnej wiedzy o tym ‘co się dzieje i dlaczego”. Klasyczny [[anemiczny model dziedziny]]. Zaryzykuje tezę, że żaden sensownie działający program symulujący grę w monopol nie będzie miał takiego modelu dziedziny. Można mnie teraz zlinczować, ale odradzam ten materiał].
Model na powyższym, moim, diagramie to model dziedziny systemu, czyli komponent M wzorca MVC. Jak powstawał? Najpierw zidentyfikowano klasy, które za “coś” odpowiadają. Powstały klasy Plansza i Bierka, druga odpowiada za wiedzę o istnieniu każdej bierki, czym ona jest i jej położeniu. Plansza odpowiada za utrzymanie kolekcji Bierek jednej gry (partii) i zobrazowanie zmian ich położenia. Następnie powstała klasa FabrykaPlansz, odpowiada za tworzenie nowych “dziewiczych” plansz z bierkami ustawionymi w położeniach inicjujących grę. Mamy już plansze i mechanizm tworzenia nowych. Przychodzi pora na “obsługę” przypadków użycia. Dobrą praktyką jest separowanie klas reprezentujących byty dziedzinowe od tego w jaki sposób są wykorzystywane (pełnią bierną rolę, bierki same się nie przesuwają!). Ma to dwie podstawowe zalety: nie przeciążamy klas odpowiedzialnością oraz zachowujemy kluczową potrzebę: możliwość łatwego rozwijania aplikacji bez przebudowy (tak zwane [[open closed principle]]). Jak to działa? Wyobraźmy sobie, że nie ma jeszcze żółtej klasy KontrolerRegułGryWSzachy. Wydawało by się, że klasa PrzemieszczanieBierki jest zbędna (klasa Plansza ma wszystkie jej operacje). Po co to?
Zasada “nigdy nie mów nigdy” oznacza, że żaden program nie jest skończony. Innymi słowy powinno być możliwe rozszerzanie jego funkcjonalności bez przebudowy. W wymaganiach pojawiło się “Kontrola reguł gry”. Wyobraźmy sobie, że wymaganie to “wyskakuje” jak królik z kapelusza, dopiero po oddaniu programu do użytku (czyli norma :)). Gdyby nie było klasy PrzemieszczanieBierki, zapewne “odpowiedzialność” ta (reguły gry) wylądowała by w Klasie Plansza lub Bierki zostały by obciążone wiedzą o tym jak wolno je przestawiać (to najgorszy pomysł). Klasy zaczynają puchnąć i ulega rozmyciu ich pierwotna logika.
Zaprojektowanie od razu, pozornie niepotrzebnej klasy PrzemieszczanieBierki, izoluje logikę gry w szachy (pierwotnie odpowiada za nią aktor) od planszy, która tej logiki nie powinna znać (bierki “są przesuwane” a nie “się przesuwają”). Nowe wymaganie Obsługa logiki gdy w szachy, to nowa klasa KontrolerRegułGryWSzachy “podpinamy” do klasy Przemieszczanie bierki, bo to naturalne: do tej pory te ruchy kontrolował gracz, teraz gracz jest kontrolowany (a raczej ograniczany) regułami, które zna “ktoś” a nie plansza (ta nie powinna nigdy być tym obciążona). Po drugie zmiana reguł gry to ingerencja w klasę KontrolerReguł, gdybyśmy obciążyli tą wiedzą plansze i bierki, przeróbki wymagałaby znaczna część programu (niemalże cały).
Kolejna korzyść: komponent View ma prosty problem: dla jednego przypadku wywołuje jedną klasę i ta kontroluje cały scenariusz. Nie obciążamy komponentu View wiedzą o szczegółach dziedziny, ukrywamy ją przed nim (hermetyzacja). Jakakolwiek zmiana zachowania wymuszona np. zmianą tabletu na smartfon itp. nie przeniesie się poza klasę PrzemieszczanieBierki.
Mity. Model dziedziny nie powinien zawierać logiki biznesowej, ta jest elementem kontrolera. Jak widać jest to bzdura. Komponent Model Dziedziny powinien pozwalać na wykonanie wszystkich testów funkcjonalności bo taka jest jego rola! Zaczynamy modelować klasy od ich atrybutów. Bzdura. Klasy mają odpowiedzialność czyli operacje, które “coś potrafią” i od tego zaczynamy. Atrybuty powstają na samym końcu jako te elementy, które “coś zapamiętują” w związku z realizowanymi zadaniami (a zadania projektujemy najpierw). Na etapie analizy należy zaprojektować model bazy danych. Bzdura. To implementacja, która jest zadaniem wykonawcy, to on podejmie decyzje jak obsłuży utrwalanie danych, a to nie ma nic wspólnego z modelem i modelowaniem obiektowym.
Skąd te operacje w klasach
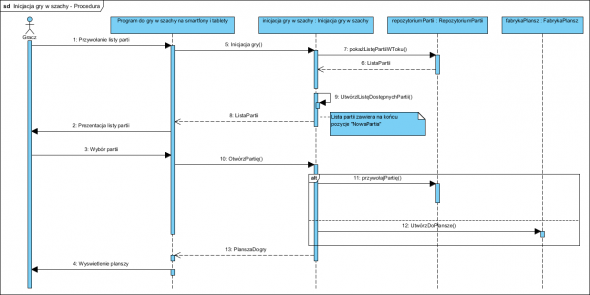
Mając model przypadków użycia budujemy dla każdego z nich scenariusz. Opisuje on dialog aktora z oprogramowaniem. Kolejny krok to test projektu modelu dziedziny: opracowany wstępny model (same klasy bez operacji i atrybutów) zostaje użyty do realizacji scenariuszy przypadków użycia. Nie ma większego sensu “wymyślanie” operacji klas “na zapas” bo nie mamy żadnych przesłanek do ich tworzenia. Wiemy, że bierka ma reagować na żądanie przemieszczenia ale treść tego żądania to skutek dialogu jaki zaistnieje. Wymyślanie “na zapas” (burza mózgów nad atrybutami i operacjami klas to najgorszy sposób) kończy się z reguły masą nadmiarowych i masą nieprzewidzianych atrybutów i operacji. Znacznie lepsza jest symulacja dialogu. Robimy to z pomocą opracowanych scenariuszy przypadków użycia i rozpisania ich na model dziedziny:
Inicjacja gry:
Przemieszczenie bierki:
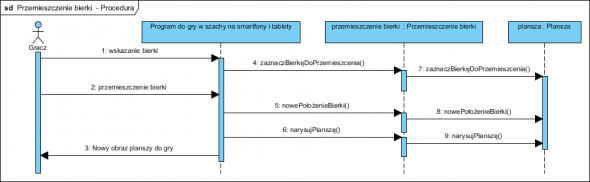
Odkryjemy przy okazji, że Inicjacja gry doskonale nadaje się na przywoływanie z Repozytorium partii przerwanych (jest takie wymaganie!). Teraz dopiero “obdarzymy” nasze klasy operacjami, są one naturalną konsekwencją tego dialogu, a pamiętamy, że paradygmat obiektowy to “współpracujące obiekty” a nie jakieś encje i funkcje.
Atrybuty. Teraz dopiero, na samym końcu, pojawia się potrzeba ich istnienia, są parametrami wywołań. Teraz wiemy jakie powinny one być. Kolejną dobrą praktyką jest stosowanie typów złożonych (albo w DDD valueObjects). Np. położenie bierki to w tym projekcie nie dwa proste (primitive) atrybuty wiersz i kolumna, a jeden atrybut PoleSzachownicy. Co osiągamy? Po pierwsze kontrolujemy w jednym miejscu jego poprawność (podana para opisująca położenie, musi wskazywać poprawne pole mieszczące się w obszarze szachownicy). Po drugie ewentualna zmiana np. wymiarów szachownicy będzie wymagała wyłącznie zmiany deklaracji tej klasy, a nie wszystkich innych operujących współrzędnymi pola szachownicy wywołań. Wyobraźmy sobie jaką pracę należało by wykonać by dostosować program do gry w szachy heksagonalne, w moim przykładzie były by to wręcz kosmetyczne poprawki a nie refaktoring całej aplikacji.
Stany. Może nam się przytrafić klasa mająca także stany. Stan to pewien szczególny atrybut klasy, jego zmiana rządzi się własnymi prawami, (regułami), dokumentujemy to modelem maszyny stanowej. Tu jest to nasza Bierka:
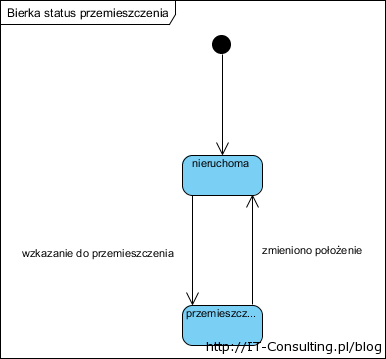
Potrzeba istnienia tego statusu wynika ze scenariusza ich przemieszczania: najpierw informujemy Plansze, która bierka będzie przemieszczana (a konkretnie jej położenie), drugi krok to polecenie o nowym położeniu. Plansza wie, że dotyczy ono tylko tej jednej bierki o statusie “przemieszczana”. Dzięki temu, w celu wydania polecenia przemieszczenia bierki, nie musimy operować “roboczą” parą danych “pole początkowe i pole końcowe” i która to bierka, co skomplikowało by program. Po protu najpierw pokazujemy konkretną bierkę (ona jest na jakimś polu) a potem pole na które ma się przemieścić. To dwa proste polecenia z minimalną ilością parametrów. Po drugie dokładnie odwzorowuje to co robi gracz. (gdyby w przyszłości ktoś zażądał funkcjonalności dokumentowania partii, wystarczy te polecenia rejestrować).
Dobrze zaprojektowanie oprogramowanie cechuje się tym, że koszt kolejnych nowych funkcjonalności jest porównywalny i względnie stały. Widać to na przykładzie “dodania” funkcjonalności “Kontrola reguł gry”.
Zarządzanie wymaganiami
Mamy tu do czynienia z wieloma modelami, każdy ma swoją role do odegrania, do tego nad nami “wiszą” wymagania. Warto zarządzać nimi, postępem ich realizacji oraz kontrolować wymagania “sieroty” (nie używane po wdrożeniu a wymagane funkcje programu) i wymagania “utajone” (odkrywamy je na etapie implementacji i wdrożenia jako brakujące a wymagane jednak przez użytkowników zachowania i cechy). Do tego celu służy model wymagań wykonany w notacji SysML:
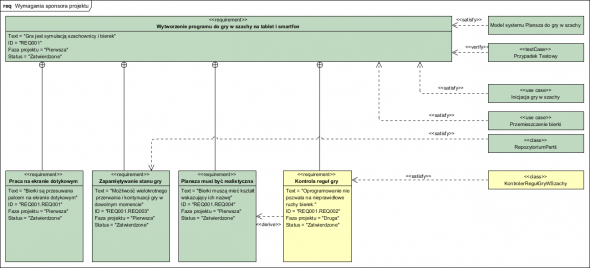
Wymagania otrzymane od Zamawiającego najpierw porządkujemy w ich hierarchię, potem wskazujemy jak są realizowane. Takie “śladowanie” ułatwia panowanie nad zakresem projektu, pozwala także na zarządzanie ich realizacją.
Teraz widać także, że podział na wymagania funkcjonalne i pozostałe “sam się dokonał”, znacznie lepiej niż domysły Zamawiającego na początku projektu (dla którego są to zresztą słusznie równoprawne wymagania).
Ten projekt zapewne można jeszcze ulepszyć, ale myślę (mam nadzieję), że już na tym etapie pokazuje zalety OOAD i różnice w stosunku do metod strukturalnych. Pokazuje także w praktyce dość bogaty model kompetencji Analityka Biznesowego wg. IIBA.
Analiza wpływu – narzędzia CASE
Nie raz w większym projekcie nieocenione są możliwości kontroli całego projektu w postaci analizy wpływu jednych elementów projektu na pozostałe, oraz kontrola tak zwanych sierot, czyli nieużywanych a zaprojektowanych elementów. Efekt takiej analizy może wyglądać tak (tu nie ma sierot ;)):
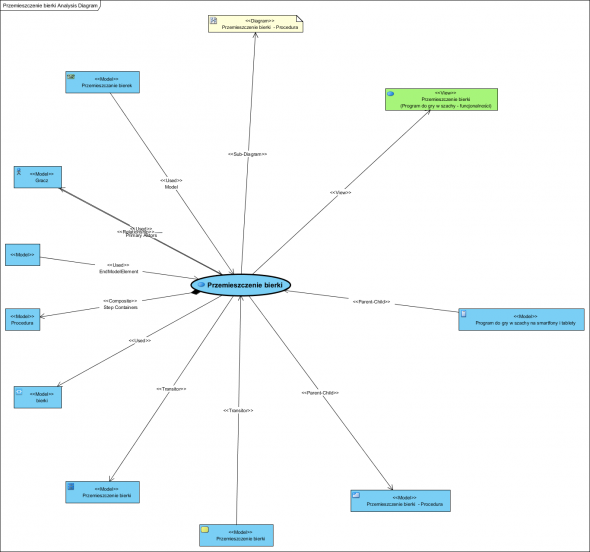
Wykonanie takiej analizy ręcznie to ogromna pracochłonność, podobnie zresztą jak śladowanie (wywodzenie jednych modeli z drugich metodą top-down, od ogółu do szczegółu) całego projektu. Dlatego niedawno pisałem, że prowadzenie takich projektów z pomocą zwykłego oprogramowania np. biurowego, zdjęć tablic zapisanych notatkami i żółtymi karteczkami, itp. to metody rodem ze średniowiecznych manufaktur. Bez narzędzi CASE takie projekty są bardzo pracochłonne i narażone na ogrom błędów.
Na zakończenie
Analiza i projektowanie obiektowe (ang. OOAD) to niejako “implementacja” klasycznej analizy systemowej. Nie ma ona nic wspólnego ze strukturalnymi metodami analizy i projektowania oprogramowania (czego wielu zdaje się nadal nie dostrzegać). Wygląda na to, że jest znacznie trudniejsza ale praktyka pokazuje, że daje znacznie lepsze rezultaty. Języki obiektowe to nie jakieś tam nowa nazwa klasy na podprogramy, a zupełnie nowy paradygmat programowania: musi być poprzedzany analizą i projektem. Jego zaletą jest to, że pozwala na odwzorowywanie, niemalże jak w grze, analizowanego i rozwiązywanego problemu, pozwala na przetestowanie pomysłu na program zanim powstanie choć jedna linia programu. Problemem i wyzwaniem na etapie analizy jest zrozumienie problemu, co mam nadzieję pokazałem.
Niestety wiele analiz dokumentowanych z użyciem notacji UML nie ma wiele wspólnego z OOAD, stanowią echa strukturalnych metod analizy i projektowania, stosowania baz relacyjnych już na etapie analizy (obiektowe narzędzia nie czynią projektów obiektowymi). Niestety błędy te popełniają nawet wykładowcy wielu uczelni i kursów.
Bardziej rozbudowany projekt, wraz z filmem o jego powstawaniu tu: Inżynieria oprogramowania z użyciem narzędzia CASE ? przykładowy projekt
Koszty
Są zależnie od składu zespołu developera i metody pracy. Ale zespół programista i tester, powyższe, robione metodą “agile”: czyli user story i od razu burza mózgów, “wsadzenie” do frameworka, kodowanie, testy, prototyp, testy u zamawiającego i kilka takich iteracji versus powyższe (to praca analityka tu moja, na jeden dzień). Porównanie kosztu musi każdy zrobić sam, ale z mojego doświadczenia wynika, że dojście do tego etapu (przemyślana i sprawdzona logika systemu) metodami burz mózgów i prototypowania – kolejne wersje kodu dla Klienta – to kilkukrotnie większy koszt i czas w porównaniu z opracowaniem powyższej analizy i projektu i wykonania poprawnego oprogramowania za niemalże pierwszym podejściem na bazie przemyślanego projektu (pisze na bazie wykonanych projektów, ale proporcje mogą być inne z innym zespołem). Na koniec statystyka pewnego developera (polecam cały wątek):
I started a company called Nascent Blue that specializes in MDD for application development. We have actually had the opportunity to compare MDD to traditional development side-by-side on large projects. Our client set up “the experiment” to collect the PM data for analysis. It was a large project with 5 teams. The results:
1. Our team was less than half the size of the other teams.
2. Our team produced more than twice the code of the other teams.
3. Our team achieved a 75% reduction in cost.
4. Our team achieved a 66% reduction in defect rate.
5. Our team was twice as fast (with half the size).
We have since gotten more efficient and more advanced, so I don’t know what the numbers are now.
We develop our own modeling tools (UML, ERD, and DSLs for UI and other things). We also have tools for ADM, so we can achieve similar productivity gains for re-platforming and re-architecture projects.
Literatura
Wyjątkowo podam zalecaną literaturę z nadzieją, że choć cześć tego uda się Wam analitykom, przeczytać. Sponsorom projektów polecam rozważny dobór analityków i projektantów :).
Kolejność troszkę przypadkowa (czyli z mojej półki i tylko część ;)):
1. Tytuł: Metody obiektowe w teorii i praktyce, Autor: Ian Graham, Wydanie: WTN, Warszawa 2004
2. Tytuł: Inżynieria Projektowania Strategii Przedsiębiorstwa, Autor: Lechosław Berliński, Ilona Penc-Pietrzak, Wydanie: Difin, Warszawa 2004
3. Tytuł: Inżynieria systemów informacyjnych, Autor: Paul Beynon-Davis, Wydanie: Warszawa, WNT 2004
4. Tytuł: UML. Inżynieria oprogramowania. Wydanie II, Autor: Perdita Stevens, Wydanie: Helion 2007
5. Tytuł: Strategie Konkurencji, Autor: David Faulkner, Cliff Bowman, Wydanie: Gebethner i ska, Warszawa 1996
6. Tytuł: Cybernetyka w zarządzaniu. Modelowanie cybernetyczne. Sterowanie systemami, Autor: Zdzisław Gomółka, Wydanie: Warszawa, Placet 2000
7. Tytuł: Modele referencyjne w zarządzaniu procesami biznesu, Autor: Tadeusz Kasprzak, Wydanie: Difin, Warszawa 2005
8. Tytuł: Teoria i Inżynieria Systemów, Autor: Czesław Cempel, Wydanie: Czesław CEMPEL, Poznań 2008
9. Tytuł: Business Inteligence, Autor: Jerzy Surma, Wydanie: PWN, Warszawa 2009
10. Tytuł: Architektura systemów zarządzania przedsiębiorstwem. Wzorce projektowe, Autor: Martin Fowler, Wydanie: Helion Gliwice
11. Tytuł: Head First Object-Oriented Analysis and Design, Autor: Brett D. McLaughlin, Gary Pollice, David West, Wydanie: Helion, Gliwice 2008
12. Tytuł: Projektowanie hurtowni danych. Zarządzanie kontaktami z klientami (CRM), Autor: Todman Chris, Wydanie: WNT, Warszawa 2003
13. Tytuł: Komponenty w UML, Autor: John Cheesman, John Daniels, Wydanie: WNT, Warszawa 2000
14. Tytuł: UML przewodnik użytkownika, Autor: Grady Booch, James Rumbaugh, Ivar Jacobson, Wydanie: WNT, Warszawa 2002
15. Tytuł: Inżynieria oprogramowania, Autor: Ian Sommerville, Wydanie: WNT, Warszawa
16. Tytuł: Projektowanie zorientowane obiektowo. Wzorce projektowe, Autor: Alan Shalloway, James R. Trott, Wydanie: Gliwice, Helion 2005
17. Tytuł: Wdrażanie strategii dla przewagi konkurencyjnej, Autor: Robert S. Kaplan, David P. Norton, Wydanie: PWN, Warszawa 2010
18. Tytuł: Wzorce projektowe, Autor: E.Gamma, R.Helm, R.Jonson, J.Vlissides, Wydanie: Helion, Gliwice 2010
19. Tytuł: UML w kropelce wersja 2.0, Autor: Fowler Martin, Wydanie: LTP
20. Tytuł: Analysis Patterns. Reusable Object Models, Autor: Martin Fowler, Wydanie: Addison-Wesley, 1997
21. Tytuł: Podstawy metod obiektowych, Autor: James Martin, James J.Odell, Wydanie: WNT, Warszawa 1997
22. Tytuł: Tworzenie architektury oprogramowania, Autor: Christine Hofmeister, Robert Nord, Dilip Soni, Wydanie: WNT, Warszawa 2006
23. Tytuł: Business Process Management, Autor: John Jeston, Johan Nelis, Wydanie: Butterworth-Heinemann, 2008 (Reprint 2009)
24. Tytuł: Requirements Analysis and System Design, Autor: Leszek A. Maciaszek, Wydanie: Addison Wesley 2001
25. Tytuł: Object-Oriented Construction Handbook, Autor: Heinz Zullighoven, Wydanie: Elsevier Inc. 2005
26. Tytuł: Stosowanie przypadków użycia, Autor: Geri Schneider, Jason P. Winters, Wydanie: WNT, Warszawa 2004
27. Tytuł: Porter o konkurencji, Autor: Michael E. Porter, Wydanie: PWE, Warszawa 2001
28. Tytuł: Strategie Konkurencji, Autor: Michael E. Porter, Wydanie: MT Biznes, Warszawa 2006
29. Tytuł: Michael E. Porter, Autor: Przewaga konkurencyjna, Wydanie: Helion, Gliwice 2006
30. Tytuł: Systems Analysis and Design with UML Version 2.0, Autor: Alan Dennis, Barbara Halley Wixom, David Tegarden, Wydanie: Second edition, John Wiley and Sons, Inc. 2005, USA
31. Tytuł: UML i wzorce projektowe. Analiza i projektowanie obiektowe oraz iteracyjny model wytwarzania aplikacji, Autor: Craig Larman, Wydanie: Helion, Gliwice 2011
32. Tytuł: Object-Oriented Construction Handbook: Developing Application-Oriented Software with the Tools & Materials Approach, Autor: Heinz Züllighoven, Wydanie: Morgan Kaufmann; 1 edition, October 13, 2004
33. Tytuł: Domain-Driven Design: Tackling Complexity in the Heart of Software, Autor: Eric Evans, Wydanie: Addison-Wesley
(zainteresowanych poznaniem opisanych metod analizy i projektowania zapraszam na moje szkolenia)
A na zakończenie cytat:
Moja rada dla osób zaczynających pracę w IT… zanim usiądziesz do komputera i zaczniesz programować czy konfigurować weź kartkę, pomyśl, napisz i narysuj co chcesz zrobić, pomyśl jeszcze raz, popraw, pokaż innym, spytaj ich o opinie, po raz kolejny pomyśl, jeszcze raz popraw i dopiero wtedy siadaj do komputera. (Zanim zaczniesz programować weź kartkę, pomyśl, napisz i narysuj co chcesz zrobić – Computerworld).
W sieci można znaleźć wiele takich i podobnych przykładów, tu jeden z nich który polecam. Powyżej opisywałem proces analizy biznesowej i projektowanie z użyciem trzech notacji (narzędzi), bo każde z nich powstało dla danego obszaru pojęciowego (osobno BMM, BPMN i UML). Poniżej przykład analizy (a raczej specyfikacji, autorka opisała treść dokumentu a nie jak powstawał) jednak co do zasady jest to “klasyczny” proces od opisu biznesu do specyfikacji aplikacji, dodam – bo tu to ważne – autorka korzystała wyłącznie z możliwości MS Office/Visio (Visio, poza pewnymi nieformalnymi bibliotekami symboli do tworzenia schematów blokowych, nie zawiera innych notacji niż UML):
Complete Business-Systems Analysis Model (UML Example) […] NOTE: The following example is the result of an analysis effort that was constructed with MS Visio and Word. (Complete Business-Systems Analysis Model (UML Example).



Bardzo dziekuję za ten artykuł. Jeszcze go szczegółowo nie skomentuję, bo do dobrego przetrawienia tak dużej ilosci skondensowanej wiedzy potrzeba go z kilka razy przeczytać. Na razie spraktykuję część sprzed “kości niezgody”. Wnioski ogólne pozwolę sobie potem umiescić w komentarzu.
Artykuł jest zdecydowanie ciekawy, niemniej jest jednocześnie zbyt ogólny by miał zastosowanie w praktyce, i zbyt szczegółowy bym wiedział gdzie dalej szukać odpowiedzi na pewne pytania.
Od nagłówka “Model dziedziny” artykuł przestał być dla mnie zrozumiały, ponieważ użyto pojęć których nie znam z definicji a nie ma tych definicji podanych w tekście.
Niemniej, źródło jest wartościowe jako początek poszukiwań.
Kolejna kwestia to taka, że nie widzę wartości w tak niskopoziomowej analizie. Diagram dziedziny i ilustracja Inicjacji gry są niezrozumiałe dla mnie jako laika i tak samo będą niezrozumiałe dla mojego klienta.
Nie wiem więc czemu dokładnie służą i co wnoszą.
Zabezpieczają przed ryzykiem wykonana przez developera złej (czytaj kosztownej w wykonaniu i w utrzymaniu) implementacji. Ten poziom “szczegółowości” chroni inwestora przed developerem (ten dokument jest dla developera a nie dla sponsora projektu, podobnie jak projekty architektoniczne zleca się w biurze architektonicznym nie wykonawcy).
Problemem większości projektów IT jest założenie, że tylko dostawca/wykonawca usługi ma wiedzę o tym jak to zrobić. Tezę tę forsują najczęściej własnie wykonawcy (developerzy), a problem polega na tym, że wykonawca dąży tu do sytuacji gdy sam sobie stawia wymagania a potem rozlicza ich realizację.
Artykuł wskazuje ryzyka a potem “właściwe postepowanie”. Przewrotnie odpowiem: to, że Pan nie rozumie “Od nagłowka…” znaczy, że nie powinien sam zlecać takich prac, bo nie ma Pan żadnej możliwości oceny czy to co Pan dostał jest tym co Pan zamówił.
Artykuł został uzupełniony o komentarz dot. wartości dodanej części projektowej, czyli przed czym chroni Zamawiającego druga część, ta której zamawiający nie rozumie.
Dodałem na końcu artykułu link do innej ciekawej przykładowej innej analizy, wykonanej w całości w UML (ograniczenie MS Visio).
Herezji krąży po sieci wiele, tu np. tylko trzeci diagram jest poprawny: http://stackoverflow.com/a/26203938
Odkopałem artykuł, ale do takich zawsze warto wracać. Mam pytanie o strzałki zwrócone wstecz na diagramie procesów biznesowych i “cofanie się w czasie”. Gdzieś wspominałeś, że taki zapis może mieć wątpliwe interpretacje w kontekście definicji procesu biznesowego (chronologiczny ciąg czynności). Czy ma sens modyfikacja diagramu i przypięcie do czynności “Przemieszczenie bierki” zdarzenia “Koniec rundy” zamiast bramki?
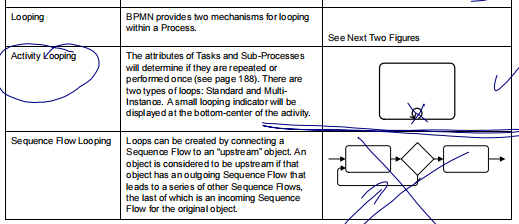
Na tym diagramie pokazałem także “procedurę” (pętla), stąd ta “strzałka wstecz”. Troszkę “na skróty” (skrót myślowy ;)) umieściłem na diagramie “jawnie” tę pętlę. W BPMN można to (konstrukcja pętli “do siebie”) zastąpić dedykowanym symbolem (aktywność oznaczona pętelką u dołu, element Loop w BPMN).
Można to podzielić na dwa procesy:
– inicjacja gry (wykonywa raz dla danej partii),
– przemieszczenie bierki (wykonywany “na żądanie” gracza aż do zakończenia partii).
Wtedy nie będzie tej “pętli” a model będzie także poprawny.
Czy związek kompozycji na modelu klas został użyty z względu na to, że te klasy obrazują rzeczy materialne?
Tak jak pisał Pan w artykule:
” związek kompozycji stosowany jest do “rzeczy materialnych” (np. odwzorowywanie powyższego w postaci struktury klas w kodzie, OOP, pokazanie struktury materialnych konstrukcji, np. samochodu) (…).”
https://it-consulting.pl/2016/10/24/zwiazki-w-uml-czyli-abstrakcja-vs-rzeczywistosc/
Związek kompozycji to powiązanie dwóch “istniejących” rzeczy (np. komponentów w kodu). W tym artykule użyty nieco “na siłę” by to pokazać. W projektowaniu generalnie jest rzadko używany, bo rzadko ma sens. Komponenty wymieniają komunikaty, jeżeli są częścią nadrzędnego to raczej modelujemy to tak jak tu:
Figure 11.5 Associations compared with Connectors (spec. UML)
Figure 11.14 Port examples
W zasadzie na modelach pojęciowych używamy tylko asocjacji i generalizacji, na modelach “działającego systemu” tylko związków zależności
“raczej modelujemy to tak”
czy nawet powinniśmy tak modelować? Bo jak patrzy się na gros modeli dostarczanych przez ludzi, to zawsze człowiek widzi kompozycje. Zawieranie chyba tylko u Pana.
” Bo jak patrzy się na gros modeli dostarczanych przez ludzi, to zawsze człowiek widzi kompozycje.”
Tacy “ludzie” powinni w “nagrodę” odtworzyć to literalnie w kodzie …. o ponosić skutki 🙂
“Zawieranie chyba tylko u Pana.”
Nie tylko, wielu autorów publikacji o projektowaniu o tym pisze. Problem w tym, że UML został zdominowany przez Java-pisarzy, a ten język (podobnie jak C++) z “obiektowością” niewiele ma wspólnego na co sam Alan Kay 9pomysłodawca OOP/OOAD) mówi od ponad 20 lat … JavaEE i jego potomkowie (Spring/Jakarta) to zlepek antywzorców z dziedziczeniem i anemicznym modelem na czele.
“wielu autorów publikacji o projektowaniu o tym pisze”
proszę o przykłady takich publikacji.
na początek polecam po prostu oryginalną specyfikacje UML :), przykładowe rysunki z niej podałem wyżej, 🙂
a np. tu pokazano kiedy kompozycja może mieć sens: Figure 11.45 An alternative nested representation of a complex Component
związek zawierania opisano tu: Figure 12.5 Examples of a Package with Members
to są rzadko używane związki, najczęściej w modelowania metamodeli (kompozycje) i struktur XML/JSON (zawieranie)