Od pewnego czasu coraz częściej pojawiają się publikacje na temat zastosowywania technologii sztucznej inteligencji (AI, ang. artificial intelligence) i uczenia maszynkowego (ML, ang. Machine learning, rozumiane jako uczenie się maszynowe). Pojawiają się projekty takie jak automatyzacja czy robotyzacja procesów biznesowych. Projekty tego typu mają często na celu ograniczanie zaangażowania ludzi, jednak większe korzyści osiąga się gdy wdrożenia nastawiają się na wsparcie ludzi i minimalizacje popełnianych błędów.
W roku 2023:
System AI: “Zaprojektowany system, który generuje dane wyjściowe, takie jak treści, prognozy, zalecenia lub decyzje dla danego zestawu celów zdefiniowanych przez człowieka”.
źr.: key definitions in ISO/IEC 22989, https://www.holisticai.com/news/iso-iec-22989-foundational-standard-on-ai-open-source
Wstęp
Najpierw kilka kluczowych pojęć:
sztuczna inteligencja: dział informatyki badający reguły rządzące zachowaniami umysłowymi człowieka i tworzący programy lub systemy komputerowe symulujące ludzkie myślenie (źr. Słownik Języka Polskiego PWN)
uczenie maszynowe (ang. machine learning): jest nauką łączącą takie dziedziny jak informatyka i robotyka. Głównym celem uczenia maszynowego jest rozwój sztucznej inteligencji poprzez samodoskonalenie się systemu na podstawie dostarczonych danych (czyli doświadczenia) i zdobywanie wiedzy. (źr. Mfiles.pl)
deep learning: proces, w którym komputer uczy się wykonywania zadań naturalnych dla ludzkiego mózgu, takich jak rozpoznawanie mowy, identyfikowanie obrazów lub tworzenie prognoz. Zamiast organizować dane i wykonywać szereg zdefiniowanych równań, w przypadku deep learning komputer zbiera podstawowe parametry dotyczące danych i przygotowuje się do samodzielnego uczenia, poprzez rozpoznawanie wzorców z zastosowaniem wielu warstw przetwarzania. (źr. SAS Inst.)
robot: urządzenie zastępujące człowieka przy wykonywaniu niektórych czynności (SJP PWN)
Te pojęcia (także robotyzacja, automatyzacja), coraz częściej pojawiają się w przestrzeni publicznej, nie mają one jednak ścisłych definicji, powyższe uznałem za reprezentatywne w kontekście publikacji prasowych. Zestawmy je teraz z definicją:
Inteligencja: zdolność rozumienia, uczenia się oraz wykorzystywania posiadanej wiedzy i umiejętności w sytuacjach nowych.
(na podst.: https://pl.wikipedia.org/wiki/Inteligencja#:~:text=intelligentia%20%E2%80%93%20zdolno%C5%9B%C4%87%20pojmowania%2C%20rozum),i%20umiej%C4%99tno%C5%9Bci%20w%20r%C3%B3%C5%BCnych%20sytuacjach.
Pojęcie inteligencji także nie ma ścisłej definicji, jednak powyższa definicja zawiera dwa kluczowe pojęcia: rozumienie oraz wykorzystanie umiejętności. Oba są domeną ludzi, ludzkiej inteligencji.
Oprogramowanie gromadzi i przetwarza dane, dane te mogą nieść informacje, ale wiedza to zbiór danych zrozumiałych dla człowieka. To co odróżnia człowieka od maszyny to to, że człowiek rozumie pojęcia a maszyna je jedynie przechowuje i przetwarza jako dane, a nie jako “słowa”. Warto tu zwrócić uwagę na to, że pod pojęciem komputerowego rozpoznawania mowy czy obrazu rozumiemy automatyczną zamianę głosu (dźwięku) lub obrazu na tekst, a nie rozumienie “tego co słychać” lub “widać”. Tak więc nawet, jeżeli nie potrafimy wskazać wyraźnej granicy między inteligencją sztuczną i tą prawdziwą, wiemy, że ta granica jednak jest.
Algorytmy i ich “inteligencja”
Obecna moda na sztuczną inteligencję jest w moich oczach tylko kolejną falą mody. Stosunkowo niedawno była podobna moda na “marketing automation” (także robotyzacja, inna nazwa na to samo?). Entuzjaści automatyzacji (robotyzacji) podkreślają to, że maszyny są w wielu zadaniach szybsze od człowieka, nie męczą się. Wskazują, że możliwe jest, by algorytmy same się doskonaliły (machine learning, algorytmy genetyczne, itp.). Renesans sieci neuronowych (deep learning itp.) dał części ludziom wiarę w to, że maszyna nas dogoni a nawet, że jest od nas: ludzi, lepsza. Niewątpliwie jest szybsza, ale przewagą człowieka (homo sapiens) nigdy nie była szybkość czy siła, więc to sztuczne zawody: człowiek nie ściga się z maszyną (robotem) i nie próbuje być od niej ani szybszy ani silniejszy.
Od pewnego czasu w dziedzinie sztucznej inteligencji, regularnie pojawiają się pojęcia ontologia i język OWL (OWL ang. Web Ontology Language), język ze składnią opartą na XML, a semantyką opartą na logice opisowej (ang. description logics). OWL służy do opisywania danych w postaci ontologii i budowania w ten sposób tzw. Semantycznego Internetu. Problem w tym, że modele semantyczne (ontologie) są tak złożone, że są problemy z ich implementacją. Po drugie ontologia ma sens z perspektywy człowieka, który rozumie pojęcia (interpretuje słowa), ale maszyna może co najwyżej przetwarzać dane. Jednym z moich ulubionych przykładów niemocy inteligencji maszyn, budowanej na modelach ontologicznych jest poniższy przykład tak zwanej kontekstowej (skojarzeniowej) reklamy w pewnym portalu (przykład tak zwanego “marketing automation” czyli robota, który bez udziału człowieka wyświetla skojarzone reklamy): pewne słowa kluczowe w tekstach są uwydatniane, jeżeli zostaną automatycznie skojarzone z treścią (słowami kluczowymi) reklamy, efekty potrafią być zaskakujące:

Ciekawy wywiad:
Czy sztuczna inteligencja może uczynić systemy ERP lepszymi?
Automatyzacja obszarów działania nie stwarzających ryzyka wygenerowania szkodliwej dla firmy decyzji, nie jest niczym nowym, to co nazywamy MRPII to nic innego jak wykorzystanie faktu, że w pewnych obszarach problemem jest wymagana szybkość obliczeń a nie ich złożoność czy wręcz trudność, bo ryzyko złej decyzji tu nie istnieje. Niektóre moduły oprogramowania są wtedy robotami, który samodzielnie i automatycznie realizują z góry określone operacje.
Wiele się pisze o Big Data i automatycznym wykrywaniu nadużyć, jednak warto wiedzieć, że maszyna daje co najwyżej przesłanki, decyzje podejmuje (powinien) człowiek. Powyższy przykład reklamy w Internecie jest tego dobitnym przykładem.
Niewątpliwie postęp technologiczny jest źródłem wzrostu wydajności, postępująca automatyzacja obniża koszty i także podnosi efektywność, jednak są to wszystko te obszary działania człowieka, w których nie miał on nigdy aspiracji na bycie lepszym od maszyny.
Modne się staje znowu automatyczne obsługiwanie kontaktów z klientem. Każdy kto często zgłasza nadużycia na Facebooku i czyta odpowiedzi wie, że to bardzo frustrujące (większość takich zgłoszeń w FB obsługują automaty/roboty).
Wiele mechanizmów automatycznej obsługi klientów opiera się na założeniu, że wielka liczba takich kontaktów podlega statystycznym prawom, i można sobie pozwolić “ofiary” bo jest ich na tyle mało, że zwiększenie efektywności daje dodatni bilans korzyści z tej automatyzacji. Zapewne statystycznie tak, ale statystyka, jako tylko historia, nigdy nie przekroczy progu jakim jest przewidywanie przyszłości. Nie da się przewidzieć, który pytający to przyszłe “zamówienie na milion”. Decyzja o automatyzacji obsługi klienta może być dobrą decyzją, o ile jest to decyzja świadoma tego. Jednak nie raz obserwuję u przedsiębiorców zachłyśnięcie się ofertą technokraty, co nie raz skutkuje niestety stratami zamiast zysków.
Coraz częściej wskazuje się na duży postęp techniczny w obszarze rozpoznawania mowy, obrazów i uczenia się maszynowego, jednak to jest problem nadal z obszaru ryzyka i etyki zarazem. Doskonałym, moim zdaniem, przykładem są filozoficzne dysputy na temat autonomicznych samochodów. Dyskusja jest często przenoszona na pole dywagacji o tym czy zabić można staruszka na pasach dla pieszych czy matkę z dzieckiem na poboczu. Tak postawiony problem to czysto technokratyczny tok myślenia, polegający na uznaniu niepodważalności zastosowania samej technologii i jedynie ocenie szkodliwości skutków jej użycia. Znacznie mniej popularne jest istniejące i proste rozwiązanie tego dylematu: badania wskazują, że potrącenie pieszego stanowi dla niego minimalne ryzyko utraty zdrowia lub życia o ile pojazd porusza się z prędkością nie wyższą niż 30km/h. Więc wystarczy przyjąć zasadę, że pojazdy autonomiczne mają “zakaz” poruszania się większą prędkością i problem znika. Technokracja i biznes jednak podnosi, że tak wolny samochód nie znajdzie zbyt dużego popytu na rynku. Rozsądna odpowiedź powinna brzmieć: trudno.
Na zakończenie
Czy system ERP różni się tu czymkolwiek od samochodu? Moim zdaniem nie, jako automat może przynieść tyle korzyści co i szkód. Obecny stan wiedzy pozwala w moich oczach przyjąć prostą zasadę: tam gdzie automatyzacja nie stwarza ryzyka, z powodzeniem można ją stosować, jednak człowiek ma nad maszynami tak wielka przewagę ? swoją prawdziwą a nie sztuczną inteligencję, że przesadne eliminowanie go z procesów biznesowych poprowadzi raczej do upadku niż sukcesu.
Kończąc ten, dość filozoficzny, wątek jakim jest inteligencja systemów ERP, powiem: komputer to uniwersalny mechanizm ale człowiek to nie jest tylko mechanizm. System ERP nie będzie więc mądrzejszy, ale szybszy owszem…
Artykuł ukazał się w raporcie PERSPEKTYWY ERP 2019. ERP View. . Published March 7, 2019. Accessed March 8, 2019.
Narodziny ChatGPT
W roku 2022, na stronie openai.com, pojawił się produkt o nazwie ChatGPT. Bot prowadzący rozmowy. Wielu ludzi zachłysnęło się “trafnością” odpowiedzi. Realnie jest to zakrojony na wielką skalę Test Turinga (patrz także: https://www.gov.pl/web/ncbr/sztuczna-inteligencja–czy-pamietamy-o-tescie-turinga).
Pojawiły się zachwyty, którymi tu nie będę poświęcał czasu. Znamienne i groźne moim zdaniem, są plany upodmiotowienia sztucznej inteligencji (AI, artificial intelligence):
Rektor Uniwersytetu Gdańskiego powołał przy Wydziale Prawa i Administracji Centrum Prawa Nowych Technologii, które będzie się zajmować zagadnieniami takimi jak: (1) totalitaryzm cyfrowy, (2) upodmiotowienie sztucznej inteligencji czy (3) zautomatyzowane wydawanie orzeczeń i decyzji. Więcej informacji niebawem, serdecznie zapraszam do współpracy! 😉
źr.: https://www.linkedin.com/feed/update/urn:li:activity:7010686870305017856/
Kluczowy i nieukrywany już cel to zdejmowanie odpowiedzialności z producentów sprzętu:
Prace na temat odpowiedzialności AI polegają między innymi na opracowaniu obszaru odpowiedzialności programisty, osoby dostarczającej danych learningu, integratora, samego algorytmu, itd.
źr.: https://www.linkedin.com/feed/update/urn:li:activity:7011310352357335040?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7011310352357335040%2C7011336407453417472%29&replyUrn=urn%3Ali%3Acomment%3A%28activity%3A7011310352357335040%2C7012770739535699968%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287011336407453417472%2Curn%3Ali%3Aactivity%3A7011310352357335040%29&dashReplyUrn=urn%3Ali%3Afsd_comment%3A%287012770739535699968%2Curn%3Ali%3Aactivity%3A7011310352357335040%29
W efekcie dzisiaj, gdy np. wadliwy odkurzacz spowoduje szkody np. na ciele użytkownika, to można mieć roszczenia do jego producenta, i uzyskać zadośćuczynienie. Upodmiotowienie odkurzacza (bo ktoś mu wstawi do środka komputer i AI) spowoduje, że pokrzywdzony będzie mógł pozwać w sądzie odkurzacz, który “za karę” zostanie wyłączony lub poddany utylizacji. Czy jako ludzie na prawdę tego chcemy? Czy na prawde chcemy całkowicie zwolnić producentów zaawansowanych technologicznie urządzeń z wszelkiej odpowiedzialności?
Staje sie to groźne, bo fascynacja technologią to cecha głownie ludzi nierozumiejących jej istoty. Technokraci to ludzie często uznający wyższość algorytmu nad człowiekiem, bo “człowiek jest omylny”. Owszem jest, ale ma też jednak nadal niezaprzeczalna przewagę na algorytmami: inteligencje i świadomość, o czym zdaja sie zapominac technokraci. Mimo tego, że powstało wiele filmów opisujących skutki “wiary w nieomylność robotów” (Ja Robot, Terminator, …) nadal są ludzie chcący powierzyć swoje życie tym urządzeniom….

Obawiam się, że nadal prawdziwa jest teza mówiąca, że ludzie w swej masie zachwycają się tym czego nie rozumieją i obdarzają to Coś szczególną nadludzką mocą: raz jest to Bóg Wszechmogący a raz Sztuczna Inteligencja. Im więcej zachwytów nad AI czytam, tym bardziej odnoszę wrażenie, że u wielu ludzi zaciera sie różnica między tymi dwoma Bytami.
“ChatGPT jest bardzo inteligentnym programem w tym sensie, że jest wyjątkowo inteligentnym projektem, efektem zbiorowej myśli wielu ludzi o nieprzeciętnej inteligencji. Natomiast program sam w sobie nie ma ani krzty inteligencji, ani krzty inwencji. Jest takim samym programem jak każdy inny program reagujący na polecenia użytkownika (input) dokładnie według wcześniej przygotowanych przez programistów, ściśle określonych instrukcji.”
Andrzej Kisielewicz. (2023, July 18). Andrzej KISIELEWICZ: Bajki o sztucznej inteligencji i prawdziwe zagrożenia. Wszystko co najważniejsze. https://wszystkoconajwazniejsze.pl/andrzej-kisielewicz-bajki-o-sztucznej-inteligencji-i-prawdziwe-zagrozenia/
Bardzo ciekawe i obrazowe wyjaśnienie graniczy między inteligencja i zrozumieniem a sztuczna inteligencją :
Dodatek
W ciekawej pracy “Sztuczna inteligencja jest głupia i rozumowanie przyczynowe tego nie naprawi” znajdziemy model neuronu:
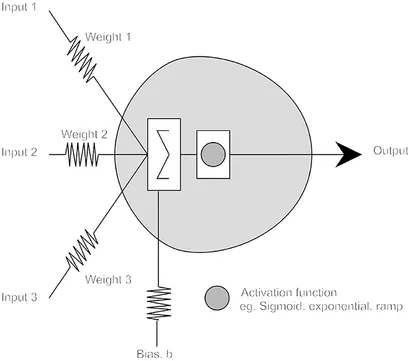
W zasadzie tłumaczy on wszystko a matematycznie można go opisać tak:
n∑iXi×Wi+b≥0
Ten niewinny schemat i wzór pod nim mówią jedno: to co generuje AI to jedynie wysublimowana suma tego co podano na wejście. Proces “uczenia” LLMów polega na przetwarzaniu danych, którego wynikiem jest statystyka a tak zwane prompty to jedynie parametryzacja tego co AI wypluje z siebie w danej sytuacji.



Wydaje się, że w artykule brakuje rozróżnienia na wąską (narrow) i ogólną (general) sztuczną inteligencję. O ile można się zgodzić z tezą, że na poziomie ogólnym kognitywne możliwości ludzkiego mózgu są ciągle poza zasięgiem systemów sztucznych, o tyle rozwiązania należące do klasy narrow często przekraczają ludzkie możliwości poznawcze i nie zawsze chodzi tylko o szybkość działania, czy precyzję obliczeń. Ostatnie wyniki DeepMind pokazują, że zdolności systemów sztucznych są w stanie “przekroczyć” osiągnięcia człowieka wypracowane na przestrzeni setek lat – tak się stało w grze w GO oraz szachach. Pojawiły się nowe strategie, których mistrzowie tych gier nie byli w stanie odkryć. Podobne efekty uzyskiwane są w badania eksperymentalnych w nauce.
https://www.quantamagazine.org/machine-learnings-amazing-ability-to-predict-chaos-20180418/
W tej sytuacji stwierdzenie, że wszystko sprowadza się do automatyzacji osiągnięć ludzkiej inteligencji wydaje się być nieadekwatne.
Pozdrawiam.
Szybkość czy precyzja obliczeń nie są cechą i miernikiem inteligencji. Gra w szachy też nie. Jak na razie najpotężniejsze sieci neuronowe nie potrafią odróżnić na zdjęciu obiektu od jego cienia, a samochody autonomiczne nadal są niebezpieczne… Komputery jak na razie nie wyszły poza bańkę determinizmu. Machine learning to nie uczenie się w ludzkim rozumieniu, a zbieranie wiedzy zaś wielkie zbiory danych to nie inteligencja. Ten eksperyment z przewidywaniem chaosu to tylko statystyka, ta zaś nie ma nic wspólnego z ludzką inteligencją. Jak na raze żadna sztuczna inteligencja nie odkryła niczego nowego, a jedną z miar rozumu jest zdolność do abstrakcyjnego myślenia i odkrywania (poznanie).
Trudno mi się z Panem zgodzić.
Szybkość przetwarzania informacji to podstawa IQ, czyli psychometrycznego pomiaru ludzkiej inteligencji. IQ zależy m.in. od pojemności tzw. pamięci roboczej, czyli określonych procesów/struktur neuronalnych, które obecnie często modeluje się przy pomocy podejścia obliczeniowego. Warto zauważyć, że proces naturalizacji umysłu ludzkiego postępuje i choć ciągle jesteśmy na początku tego procesu, to opinie typu “Machine learning to nie uczenie się w ludzkim rozumieniu” mogą z czasem okazać się jedynie przejawem tzw. psychologii ludowej (patrz koncepcja predictive coding oraz free energy principle stosowana w obszarze uczenia maszynowego oraz przez Karla Fristona, czołowego neuro-obliczeniowaca do opisu działania mózgu – obecnie jest to jedna z najbardziej płodnych i popularnych koncepcji teoretycznych w neuroscience). Dodam, że największym wyzwaniem teoretycznym w obszarze modelowania mózgu-umysłu nie są zdolności poznawcze człowieka, czy modelowanie zachowań, ale kwestia świadomości. Tutaj ciągle mamy kłopot, żeby znaleźć pojęcia, które adekwatnie uchwycą status i funkcję tego fenomenu.
A co do sieci nie odróżniających obiektu od cienia, to proszę mi wierzyć, tego typu problemy są sukcesywnie rozwiązywane – najlepsze sieci segmentujące oferowane w modelu transfer learning są w stanie rozróżniać setki kategorii obiektów, włącznie z obiektami częściowo przesłoniętymi. Często ich efektywność przewyższa możliwości człowieka np. co do rozróżniania różnych ras psów. Z resztą ludzki aparat percepcyjny też ma swoje przypadki brzegowe – patrz iluzje wzrokowe. Podobnie jest / będzie z systemami sterującymi samochodami autonomicznymi. Choć ciągle nie są one bezbłędne, to postęp jest ewidentny i w ciągu kilku lat można się spodziewać masowych wdrożeń. Jeśli ma Pan wątpliwości, to proszę zweryfikować w co inwestują obecnie duże firmy z obszaru automotive. O ile wiem, nie ma dużej firmy na rynku samochodowym, która nie przygotowywałaby się do rewolucji związanej z autonomus driving.
Jeśli chodzi o wskazany wynik dotyczący chaosu, to to z pewnością nie jest zwykła statystyka. Gdyby tak było, to nie mielibyśmy problemu z przewidywaniem pogody. Przedstawiony artykuł pokazuje, że odpowiednio zaawansowane uczenie maszynowe jest silnym narzędziem modelującym, które pozwala wykroczyć poza dotychczasowe ograniczenia, również teoretyczne, gdyż jak wiemy zwiększona moc obliczeniowa tylko w niewielkim stopniu zwiększa możliwości predykcyjne modeli chaotycznych.
Abstrahowanie to jedno z podstawowych wymagań dla systemów uczących się. Jeśli sieć nie potrafi znaleźć ogólnych prawidłowości w dostarczonej próbce uczącej, to uważa się, że model niczego się nie nauczył, a jedynie zapamiętał dostępne dane. Nie chcę przez to powiedzieć, że ludzka zdolność abstrahowania niczym nie różni się od tego, co robią dostępne obecnie algorytmy, ale różnica niekoniecznie musi być jakościowa. Może się okazać, że to jest bardziej problem ilościowy niż jakościowy – patrz teoria Tonioniego: https://en.wikipedia.org/wiki/Integrated_information_theory.
Podsumowując: duże dzieje się obecnie na styku AI – badania na ludzkim mózgiem-umysłem, dlatego wszystkie kategoryczne stwierdzenia dotyczące fundamentalnych różnic pomiędzy systemami sztucznymi a biologicznymi mogą w pewnym momencie okazać się mniej istotne niż nam się to obecnie wydaje.
Pozdrawiam.
To co napisałem, to nie kategoryzacja. Ale czekamy aż przypuszczenia się okażą faktami. Na razie nie ma ścisłej definicji inteligencji …
Na koniec jeszcze jedna ciekawostka: https://www.quantamagazine.org/how-artificial-intelligence-is-changing-science-20190311/
Ciekawy artykuł. “Sztucznej inteligencji” jeszcze daleko do prawdziwej inteligencji. Automaty odnajdują tylko pewne schematy, na podstawie jakiegoś wyuczonego(zbadanego) modelu, daleko im do inteligencji ponieważ nie są kreatywne. Na podstawie wyuczonego modelu nie są w stanie stworzyć nic odmiennego(oryginalnego) – tak przynajmniej rozumiem inteligencję.
Wielu tak właśnie ją rozumie 🙂
z tym znajdowaniem schematów na podstawie wyuczonego modelu i brakiem kreatywnosci do nie do końca prawda.
http://wyborcza.pl/7,75400,22768383,sztuczna-inteligencja-wygrywa-w-szachy.html
Jak wynika z artykułu posunięcia szachowe AI są bardziej kreatywne niż ludzkie!
Ten artykuł opisuje pojedynek dwóch programów a nie programu z człowiekiem a niestandardowe zachowanie to jeszcze nie inteligencja. No i pamiętajmy, że wygrana w szachy nie jest testem inteligencji a wygraną w szachy. “Naprzeciwko Alpha Zero stanął Stockfish 8 ? program komputerowy do gry w szachy ? przez wielu uważany za najlepszy na świecie.” Proszę mi wybaczyć ale argument dziennikarza GW w rodzaju “przez wielu uważany…” to podejście populistyczne a nie naukowe.
(generowanie wariantów nie jest kreatywnością)
Polecam artykuł:
Andrzej Kisielewicz. (2023, July 18). Andrzej KISIELEWICZ: Bajki o sztucznej inteligencji i prawdziwe zagrożenia. Wszystko co najważniejsze. https://wszystkoconajwazniejsze.pl/andrzej-kisielewicz-bajki-o-sztucznej-inteligencji-i-prawdziwe-zagrozenia/
Snapshot of key definitions in ISO/IEC 22989:
https://www.holisticai.com/news/iso-iec-22989-foundational-standard-on-ai-open-source
Uzupełniłem artykuł o bardzo ciekawe i obrazowe wyjaśnienie czym jest i czym nie jest AI (referat YT)
Uzupełniłem artykuł o prezentację pewnego ciekawego eksperymentu, pokazującego że test Turinga niestety nie mówi nic o inteligencji.
Dodałem dodatkowe źródło na temat eksperymentu “Chiński pokój”.