Strona poświęcona mojej pracy naukowej i usługom jakie świadczę polskim podmiotom. Zapraszam tych którzy szukają wiedzy i tych którzy szukają wsparcia w swoich projektach informatyzacji.
"Jeżeli nie potrafisz czegoś narysować, to znaczy że tego nie rozumiesz…"
Na temat projektowania, modelowania, analizy itp. napisano wiele. Wiele razy też czytałem i obserwowałem jak psuje się projekty tak zwaną optymalizacją, która jest jednak nie raz niczym innym jak upraszaniem prowadzącym często do katastrofy podczas przyszłej rozbudowy.
Często spotykam się z tezami, że modele tworzone w stylu DDD ([[Domain Driven Design]], ang. Projektowanie Zorientowane na Dziedzinę systemu) są mało optymalne. Najczęściej przytaczanym przykładem jest krytyka agregatów ([[wzorzec projektowy Agregat]], obiekt biznesowy modelowany jako obiekt główny i jego komponenty) jako mało wydajnych konstrukcji w przypadku zapytań o filtrowane i agregowane raporty. Jest to prawda ale wzorzec agregatu służy do zarządzania tymi obiektami a nie do tworzenia zaawansowanych wyliczeń z użyciem ich wybranych atrybutów. Zgodnie z DDD raczej należy wtedy zaprojektować osobną klasę (agregat) będącą utworzonym „na boku” stosem danych do analiz. Czy tak się robi? Oczywiście, w dużych systemach stawia się dodatkową hurtownie danych, których architektura jest przystosowana do takich własnie zapytań, w mniejszych projektuje się specjalna tablicę danych do takich raportów.
Niestety spotykam się często z upraszczaniem dobrych modeli „bo będzie się lepiej raportowało”. Czy lepiej to się okaże w praktyce zaś model „zepsuty” (najczęściej optymalizacja polega na upraszczaniu konstrukcji agregatu) staje się później nie raz niemożliwy do rozbudowy.
Właśnie mam w ręku książkę [[Joshua Blocha Java Efektywne Programowanie]] (kupiłem by poczytać co robią programiści a nie programować ;)))) i tam jest rozdział o optymalizacji, a w nim super sentencja: staraj się pisać programy poprawne a nie szybkie, po szczegóły tej myśli odsyłam do książki… Jakakolwiek optymalizacja na etapie projektowania jest przedwczesna, dopiero po skompilowaniu i testach należy ocenić czy program jest za wolny, bo może nie jest …
Czemu lubię i polecam styl DDD? Bo nawet jak nie znamy przyszłych zmian (nowych wymagań) to na pewno projekt będzie się dało rozbudować zamiast zmieniać. Dlaczego? Bo jeśli projekt dobrze „modeluje” rzeczywistość to znaczy, że jeśli tylko coś zmieni się w tej rzeczywistości będzie możliwe to, do takiego samego odwzorowania w projekcie. (tu polecam także artykuł ze stron devlab.pl o tak zwanych ValueObject): Ważne jest także przestrzeganie hermetyzacji, która także modeluje rzeczywistość. Innymi słowy „jest tylko jeden sposób by poznać lub zmienić zawartość mojej teczki: poprosić mnie”. Optymalizacja polegająca na udostępnianiu danych obiektów wprost, jeśli nie (o zgrozo) bezpośrednio z innych obiektów, to z pomocą operacji get/set (bezpośrednie pytania o konkretne atrybuty i operacje na nich) mamy na tacy to co powinno być chronione. Skutki są takie, że być może nieco uprościliśmy kod ale jego przyszła rozbudowa i konserwacja raczej będzie koszmarem. Zapewne wielu z Was spotkało się z przypadkiem, poprawienia (uzupełnienia) jakiejś funkcjonalności powodującą lawinę błędów w innych. To jeden z typowych efektów łamania zasady hermetyzacji.
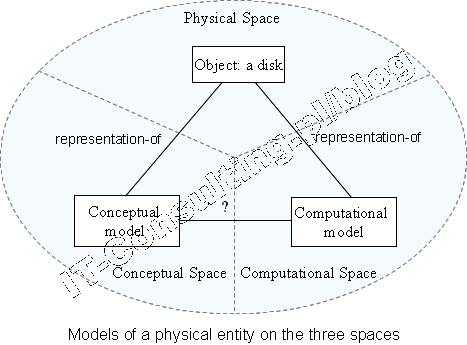
Polecam artykuł z MSDN (cytat poniżej), dodam że DDD to raczej styl analizy i projektowania a nie metodyka bo nie istnieje recepta na analizę i modelowanie. Trzeba zrozumieć to co się modeluje i odwzorować w postaci modelu w implementowanym oprogramowaniu. Porównanie z jaskinią Platona jest doskonałe :):
Możecie przyrównać [[teorie o Jaskini Platona]] do formuły modelowania DDD. Wiele z tych zaleceń pomaga nam zbliżyć się idealnego modelu w ogóle. Droga prowadząca do tworzonego kodu zależy od głów wielu ekspertów dziedzinowych i projektantów, sponsorów projektu, wymagań branży w której pracujemy. Dlatego ma ogromny sens patrzenie (razem) na projektowany system (oprogramowanie) jak na cienie odwzorowujące rzeczywistość na ścianie jaskini przed jej mieszkańcami. (źr. An Introduction To Domain-Driven Design.)
Na koniec mała uwaga dla zwolenników metod zorientowanych na przypadki użycia. Projektowanie na bazie [[sesji JAD]] i kolekcjonowaniu przypadków użycia bardzo często prowadzi do bardzo kosztownych analiz i opasłych dokumentów, gdzie odkrywane potem w prototypach nowe wymagania niszczą budżet i harmonogram projektu, jeśli nie wyraża się na nie zgody niszczą przydatność produktu. Piękną metaforę przytoczył [[Martin Fowler]]:
Wyobraźmy sobie kogoś, kto chce napisać program symulujący partnera do gry w snookera. Problem ten może zostać opisany przypadkami użycia opisującymi cechy tej gry scenariuszem: „Gracz uderza białą kulę, która przemieszcza się z konkretną prędkością, ta po określonym czasie uderza czerwoną kulę pod określonym kątem, uderzona czerwona kula przemieszcza się na pewną odległość w pewnym kierunku.” Możesz sfilmować setki tysięcy takich uderzeń, zarejestrować (scenariusz) parametry każdego uderzenia i jego skutki. Jednak tą metodą i tak nie stworzysz nawet dość dobrej symulacji. Aby napisać na prawdę dobrą grę, powinieneś raczej zrozumieć prawa rządzące ruchem kul, ich zależność od siły i kierunku uderzenia, kierunku itp. Zrozumienie tych praw pozwoli Ci znacznie łatwiej napisać dobre oprogramowanie.” (źr. [[Analysis Patterns. Reusable Object Models, Martin Fowler, Addison-Wesley, 1997]], wtrącenia moje).
Powyższy cytat, moim zdaniem powinien sobie wziąć do serca każdy dobry analityk i projektant. Powiem też, że dla mnie sam ten cytat wart był ceny książki. To jest właśnie sposób myślenia, który gorąco polecam i sam stosuję. Z innej książki: przedmiotem analizy jest to co ogólne, rzemiosło w szczegółach jako narzędzie projektowania się nie sprawdza.
Na koniec polecam także inny ciekawy artykuł kończący się słowami:
… gdy sytuacja robi się złożona, dobrze jest zdecydować się na podejście w stylu DDD, ponieważ jest dużo bardziej czytelniejsze i lepiej odpowiada skali skomplikowanych i dużych aplikacji. (źr. La Gal?re / Propaganda Kapitana Pazura ? Blog Archive ? O walidacji słów kilka).
Jarosław Żeliński: autor, badacz i praktyk analizy systemowej organizacji: Od roku 1991 roku, nieprzerwanie, realizuje projekty z zakresu analiz i projektowania systemów, dla urzędów, firm i organizacji. Od 1998 roku prowadzi samodzielne studia i prace badawcze z obszaru analizy systemowej i modelowania (modele jako przedmiot badań: ORCID). Od 2005 roku, jako nieetatowy wykładowca akademicki, prowadzi wykłady i laboratoria (ontologie i modelowanie systemów informacyjnych, aktualnie w Wyższej Szkole Informatyki Stosowanej i Zarządzania pod auspicjami Polskiej Akademii Nauk w Warszawie.) Oświadczenia: moje badania i publikacje nie mają finansowania z zewnątrz, jako ich autor deklaruję brak konfliktu interesów. Prawa autorskie: Zgodnie z art. 25 ust. 1 pkt. 1) lit. b) ustawy o prawie autorskim i prawach pokrewnych zastrzegam, że dalsze rozpowszechnianie artykułów publikowanych w niniejszym serwisie jest zabronione bez indywidualnej zgody autora (patrz Polityki Strony).
Wiele w tym prawdy. Warto jednakże zauważyć, że wskazując problemy z optymalizacją tak na prawdę mówisz o jej karykaturze. Optymalizacja winna prowadzić do subiektywnie(z punktu widzenia projektu) lepszego(szybszego, łatwiejszego dla użytkownika) osiągnięcia tych samych celów, przy zachowaniu wymagań (w tym ograniczeń i łatwości modyfikacji). Dobra optymalizacja na etapie projektowania pozwala zachować zalety DDD, czy inne parametry przyjęte w wymaganiach. Rozwiązań jest wiele – ot choćby odpowiednie agregaty dla filtrów, lub agregacje o poziom niżej w taksonomii. Ale to już zbyt szczegółowe kwestie:)
Jeśli chodzi o DDD i problem raportowania czy prezentowania danych spomiędzy agregatów oraz optymalizację wydajności, to warto spojrzeć dodatkowo na wzorzec CQRS (Command-Query Responsibility Segregation). W skrócie chodzi o to, że rozdzielamy w systemie odpowiedzialność za przetwarzanie komend zmieniających stan systemu od części wyciągającej dane do prezentacji. Efekt jest taki, że model dziedziny (w oparciu o DDD) odwzorowany jest w części przetwarzającej komendy, zaś struktura danych w części Query jest maksymalnie uproszczona i odpowiada stricte potrzebom widoków prezentowanych użytkownikowi.
Nie do końca. Po pierwsze, to źródło danych nie musi agregować danych z różnych systemów, więc nie jest potrzebny złożony ETL. Po drugie, zwykle te dane nie są wykorzystywane do przygotowywania skomplikowanych raportów historycznych z możliwością analizy wielowymiarowej, a raczej jako część zwykłego systemu transakcyjnego więc zamiast systemu OLAP wystarczy baza danych (relacyjna lub nie).
pisząc „hurtonia danych” miałem raczej na myśli dedykowaną do raportowania strukturę a nie od razu ETL i wielowymiarowe modele danych, rzecz w tym, by „prowadzić” równolegle płaską tabelę do raportowania. Jednak zapewne potrzebne będzie oszacowanie na ile ważna jest funkcja operacyjna agregatów a na ile raportowa…
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.



Wiele w tym prawdy. Warto jednakże zauważyć, że wskazując problemy z optymalizacją tak na prawdę mówisz o jej karykaturze. Optymalizacja winna prowadzić do subiektywnie(z punktu widzenia projektu) lepszego(szybszego, łatwiejszego dla użytkownika) osiągnięcia tych samych celów, przy zachowaniu wymagań (w tym ograniczeń i łatwości modyfikacji).
Dobra optymalizacja na etapie projektowania pozwala zachować zalety DDD, czy inne parametry przyjęte w wymaganiach. Rozwiązań jest wiele – ot choćby odpowiednie agregaty dla filtrów, lub agregacje o poziom niżej w taksonomii. Ale to już zbyt szczegółowe kwestie:)
Wzmianka o jaskini Platona to strzał w dziesiątkę. Chyba muszę zacząć pisać artykuły, bo ja wpadłem na to już parę lat temu 🙂
Jeśli chodzi o DDD i problem raportowania czy prezentowania danych spomiędzy agregatów oraz optymalizację wydajności, to warto spojrzeć dodatkowo na wzorzec CQRS (Command-Query Responsibility Segregation). W skrócie chodzi o to, że rozdzielamy w systemie odpowiedzialność za przetwarzanie komend zmieniających stan systemu od części wyciągającej dane do prezentacji. Efekt jest taki, że model dziedziny (w oparciu o DDD) odwzorowany jest w części przetwarzającej komendy, zaś struktura danych w części Query jest maksymalnie uproszczona i odpowiada stricte potrzebom widoków prezentowanych użytkownikowi.
Czy to przypadkiem nie skutkuje „produktem”: Model Dziedziny operacyjny plus „hurtownia danych na boku” do raportowania?
Nie do końca. Po pierwsze, to źródło danych nie musi agregować danych z różnych systemów, więc nie jest potrzebny złożony ETL. Po drugie, zwykle te dane nie są wykorzystywane do przygotowywania skomplikowanych raportów historycznych z możliwością analizy wielowymiarowej, a raczej jako część zwykłego systemu transakcyjnego więc zamiast systemu OLAP wystarczy baza danych (relacyjna lub nie).
pisząc „hurtonia danych” miałem raczej na myśli dedykowaną do raportowania strukturę a nie od razu ETL i wielowymiarowe modele danych, rzecz w tym, by „prowadzić” równolegle płaską tabelę do raportowania. Jednak zapewne potrzebne będzie oszacowanie na ile ważna jest funkcja operacyjna agregatów a na ile raportowa…
Ok. W takim razie mówimy o tym samym 🙂 Rzeczywiście skutkiem jest zazwyczaj osobna baza danych pod zapytania.